I think Bayesian models should be used everywhere and for all sample sizes. It’s just a matter of spending a little more of your time, but the payoff is large. The only problem with using Bayes with the linear model is the way priors for residual variance are specified. Since \sigma is a scaling parameter in real Y units one can’t use the same prior for multiple datasets. So Stan-oriented software scales by the observed SD of Y. This is criticized by some for not being fully Bayesian but the harm from doing this is very minimal. I’d like to study this issue more. There are probably good discussions on this on the Stan discourse site.
On the other hand, I very seldom use linear models because I want results to the Y-transformation invariance. Ordinal model linear predictors are unitless so you don’t have this problem with \sigma; you have a different issue of selection of priors for the intercepts. It’s worth running rmsb and brms and comparing results to see if this prior choice actually matters. I chose the default prior in rmsb based on getting posterior modes to agree of MLEs for a large number of distinct Y values.
So you pretty much run all continuous outcomes as ordinal models? I like the idea, I think the difficulty for me (perhaps for many statisticians working with researchers) would be convincing people of the merits of suddenly describing effects for continuous outcomes in terms of odds ratios (probabilities). Maybe the same inertial difficulties in convincing people why they shouldn’t use change scores, why restricted cubic splines solve functional form issues at the cost of losing that simple unit change interpretation, etc.
In the meantime I am super-inspired to learn more about Bayesian modelling.
So glad you’re more interested in Bayesian model. Yes I use ordinal models on continuous Y routinely. I have multiple case studies including in RMS where I show how to convert the result to different scales: exceedance probabilities, quantiles, means. When estimating covariate-specific means or covariate-adjusted differences in means with an ordinal model, Bayes has a big advantage of automatically giving you exact uncertainty intervals on derived quantities. The rmsb package makes that easy, with its Mean function ((full name Mean.blrm).
Hi,
I fitted an orm model with Y as difference between post-pre value. If want to use odds ratio to summarise the statistical association of each indipendent variable with the Y, how should I interpret these when, for example, I have:
“FEV1”: OR 0.71 (95%CI:0.63 to 0.81)
“genotype”: one mutation versus another: OR 1.26 (95%CI:1.06 to 1.5)
You shouldn’t use change scores (post minus pre). Just use the post value as Y and the pre value as a covariate (X). You could use the Mean() function to produce effect estimates on the mean scale, which are easier to interpret.
Thks for your reply. Unfortunately, for this particular analysis, people are more interested in how they get to their post-values rather then in their final value, so I used the difference and baseline value as covariate. I woud like to understand how OR can be interpreted in this particular framework.
Please don’t do that. The difference between two ordinal variables may not be ordinal. Most importantly you can get anything you want from a raw data model. For example you can estimate change by getting the predicted median and subtracting the baseline. Much better: plot baseline vs. predicted median/mean/whatever.
Hello Prof Harrell,
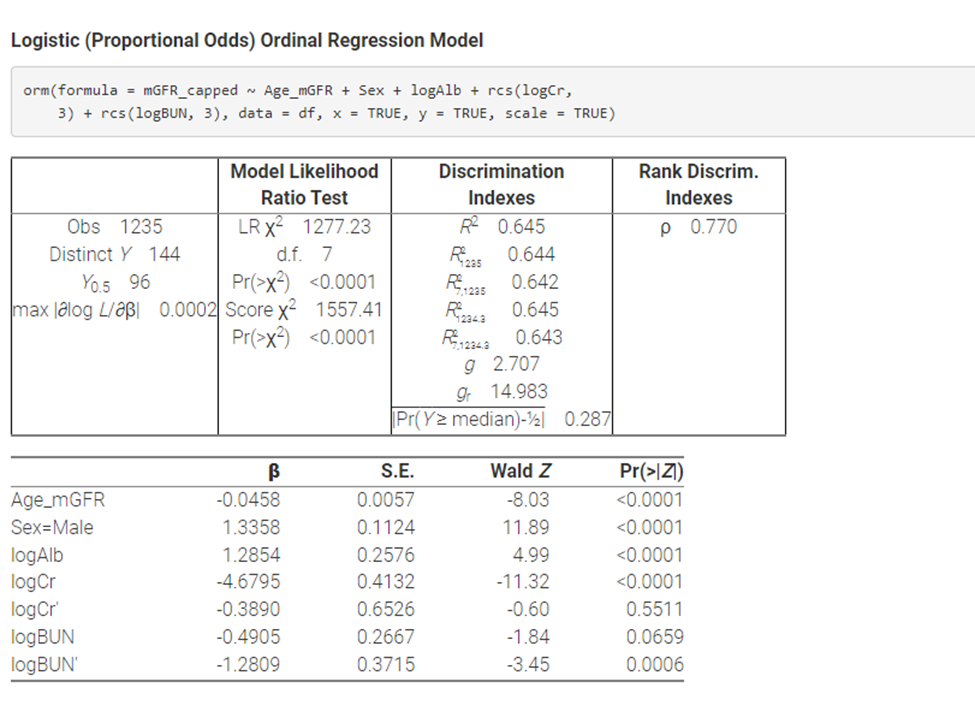
My goal is to estimate GFR for cirrhotic patients. Expert knowledge indicates using as predictors Age, Sex, Albumin, BUN, and CR.
The equations in literature available tend to underestimate the low values of GFR.
I considered a cumulative probability model (CMP) to predict measured GFR and I estimated the conditional mean and conditional quantiles (Median, Q25).
Below is the model.
I looked at the model performance using data from another center. In some situations (subgroups of patients), the Q25 estimate of the GFR seems to be a better choice, in others the conditional median. There is an interest to come up with a role to decide in clinical practice when to use the conditional median estimate and when to use a lower quartile estimate.
I was thinking of finding a compromise or providing both median and a lower quartile, but I am not sure how one would decide which estimate of GFR to use. Any suggestions?
Also, the measured GFR is capped at 10 (for values less than 10) and to 150 for values greater than 150. Can this be a problem for a CPM model?
Capping of values do not hurt quantile estimates unless a cap is close to the quantile of interest. Ordinal regression will estimate the entire distribution of eGFR which is a good starting place (see the ExProb function). Presenting multiple quantiles all be one way to summarize the cumulative distribution.
I tried to estimate change as you suggested and it worked perfectly, so much information indeed. Thks!
With regard to calibrating orm model, any calibrate function available soon?
Good! If calibrate doesn’t already work for orm you might try using lrm just for calibration. I had hoped that calibrate with orm would work at least for predicting being above the median or first intercept, but maybe not.
I am quite intrigued by this. When one uses ordinal models for continuous data, don’t they lose information on the scale of the outcome?
An example situation: Consider you have a given sample with an outcome bounded by 0 and 1. You have a large sample size and observed values for each 0.01 increment.
Then, consider another sample for which you use the same outcome scale but data concentrate in some values while some are not observed at all (e.g., you don’t observe 0.17, 0.25, 0.31, 0.32, and 0.33).
In this case, does the model handle the transitions between 0.10 and 0.11 (successive values) and the cases adjacent to nonobserved values (0.16 and 0.18, 0.24 and 0.26, 0.30 and 0.34) the same way? Wouldn’t that be problematic? While I see that the intercepts would take care of this to some extent, it is not intuitive for me why that would not be problematic when estimating the variable coefficients since the model doesn’t know there are nonobserved values of the outcome and that some 1-level transitions are actually as large as several transitions in the actual measurement.
I understand that this would not be a huge problem in a scenario with few nonobserved values, but it seems to become more important as the outcome measurement gets more granular. I feel like it disregards useful information on the outcome. Am I missing something?
Obs.: I have seen this but it doesn’t seem to be the exact same issue
See if it’s helps to think about the special case of the proportional odds mode: the Wilcoxon two-sample rank test. The kind of information loss it suffers, compared to the t-test which uses exact values, is only 1 - \frac{3}{\pi} which is about 5%. And the Wilcoxon test works great when the two groups don’t have any values in common.
My concern is not about the information loss for the hypothesis test, but for the magnitudes when estimating the coefficients. It sounds odd (no pun intended) that transitions corresponding to two or three times other transitions in the original scale will be used as one-level transitions when estimating the model.
A potential solution to this would be if the model understood levels of the ordinal scale not as 1-level transitions, but rather as the intercepts estimated for each level. If so, the distances between intercepts for each level would handle that completely, e.g., the distance between the intercept for 0.30 and 0.34 would be expected to approximate four times that from 0.30 to 0.31 (even if 0.31 is not observed for some reason) and everything would make sense. I guess that’s what happens in the backstage, otherwise creating ordinal composites using continuous scales and binary events wouldn’t make sense. Still need to dig deeper though.
The extra information you are seeking does not amount to enough when considering the non-robustness it may create. And when you use an ordinal model to estimate the mean of Y|X you get back the original efficiency because the estimator uses all the raw values.
Hi Frank and community members. I have a question about ordinal regression, specifically, interpreting the output of plot(Predict(fit, fun = exp)) when, for instance, one of the predictors is categorical.
Usually, (with lrm), I use plot(summary(f1, antilog = TRUE)). Here, the interpretation is straight-forward in the sense that each category is compared to the reference category. But in the case of Predict(), I’m not really sure what’s going on since there does not seem to be a reference category.