I am in a nursing PhD and am pretty much self-taught on the analysis front outside of our (very general) graduate level stats course. I am very interested in the “secret curriculum” that comes along with formal training in a quant heavy discipline (e.g. epi, statistics), and have benefited greatly from conversations online in terms of reproducible research, best practices for statistical programming, etc… In the last three years I have gone from SPSS drop-downs to limiting repetition through functional programming in R, but I can’t shake the sense there are more basics to learn.
One thing I still wonder about is what would be considered “best practice” for QA’ing code. In other words, what is it that the pros do to feel confident that their program isn’t just dutifully spitting out the wrong answer?
My own workflow consists of verifying that model predictions make sense, adding complexity iteratively so I can monitor whether model specifications introduce counter-intuitive results, obsessively cleaning my environment before running anything I intend to present, and then reviewing code after a cooling off period.
Is there anything I can to improve this process or make it more efficient? Are there parts of this that are just a sophisticated way for me to fool myself?
In larger centres, is there any sort of formal or informal internal code review? Assuming I am on an analysis island, it seems like it might be worthwhile to add simulation to my workflow based on responses here.
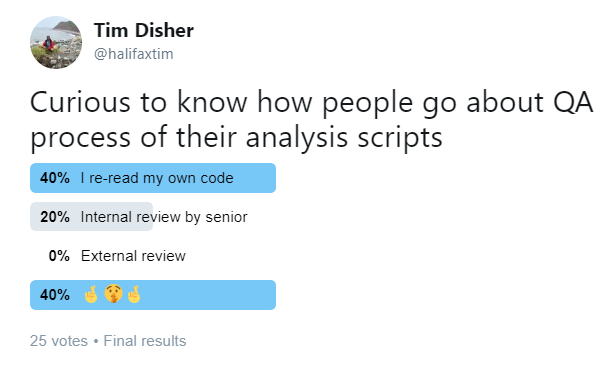
Am I just doomed to live in fear I made some small error on line 8 that invalidates everything that follows? Relevant twitter poll below:
excellent question, and i’m too busy to give a full answer. I fear that coding errors are far more rife than we’d like to think - in academia especially; in industry they have the resources to validate code properly. Ben Goldacre argued that statisticians should provide their code when submitting to a journal [bmj], i tried to push back for various reasons [bmj2]. If authors do provide their code i believe we will see just how bad the problem is and maybe it is contributing to the “reproducibility crisis”. Altho someone attempted to recode analyses for studies where data had been provided to the bmj [bmj3]. And they succeeded. But it’s possible programmers are far more careful when they know others can access their data. Regarding best practice, in industry they tend to identify 3 types of validation … suffice to say, only independent validation is reliable ie coding from scratch and (importantly) without viewing the other programmer’s code. There are some books on the topic but they are written by industry people, hence SAS sas book, SAS paper I feel that academics don’t even acknowledge the problem. You have this Cornell guy sacked yesterday, and he said “this seems to be happening based on us not being able to send them the original surveys from 10-20 years ago.” chronicle Not enough effort given to creating, validating, archiving analysis datasets
edit: in response to ben goldacre I eventually created a blog to share code: [blog], not enough time for it tho
Good points @PaulBrownPhD. In two multinational clinical trials I’ve been the DMC reporting statistician for, we implemented our reports in R but the data coordinating center programmed all pivotal analyses also in SAS and we gave them a dummy randomization to execute, then compared results. I always viewed that as the highest level of quality assurance with regard to derived variables, analysis populations, and analyses. Ideally we would have this independent validation done in Stata rather than SAS, or have two independent R programmers validate each other.
Thank you both for the response, and @PaulBrownPhD for the great resources. I wonder if that BMJ re-analysis paper would have had as much luck reproducing results from non-randomized studies or microsimulation/decision models where I imagine the path to a final result is more complex. I know it’s relatively routine for errors of varying degrees to be found in decision models when they are submitted to a “model busting” process.
This is a tough one for me, and I wonder if it’s a blissful state of ignorance. Literally, never a topic discussed in any formal academic course I’ve ever taken so I imagine everyone just thinks that proof-reading, making sure your results “make sense” and exploring if not, etc… ARE what’s best.
agreed eg large adminstrative databases. Complex data will generate so many data handling issues, unless the researchers specify how all of these things were handled, I become sceptical when results are reproduced exactly. Independent coding helps spot these issues and assumptions that are embedded in the code and encourages us to make them explicit and more deliberate.
But there are many solitary statisticians out there and then independent coding is not an option. There are a number of techniques programmers can use to reduce the possibility of errors eg “defensive coding”, making code readable (many programmers have been taught to make their code as efficient as possible), documenting everything (every decision taken re data handling), simple things like looking at min and max values. In the industry they have good programming practice (GPP) guidelines (eg GPP)
maybe habits need to change, the mentality needs to change. Academic statisticians are little bit more a jack-of-all-trades, and I don’t know if this makes them nonchalant about programming skills. They should take pride in their code, stake their reputation on it. Maybe the open science movement will push us in a direction where errors are more likely to be spotted and that would be great to keep everyone on their toes
i wonder if the authors should describe their validation in the methodology section of the paper. I read a paper recently where the authors described an approach like the one you mention; i.e. the programmers were located in different countries and used different software. I would certainly boast about that if i could. I think the FDA typically redo the analyses when a company makes an application for marketing approval. It’s a different mindset in publicly funded research when we’re all just expected to simply believe the researches analysed the data as stipulated in the protocol. It’s ironic then that medical journals once insisted that industry sponsored trials are re-analysed by an academic before being accepted for publication (Stephen Senn pushed back hard against that). I wanted to work in a regulatory setting when i was young but someone talked me out of it, they said: it’s depressing to see the quality of work submitted, probably alluding to coding errors as well as bad methodology. And why would the quality be higher outside industry? And we would not know it because we have no access to the data
This question isn’t really relevant to the main objective of the thread, but wondering what you think of the anti-industry bias from academia more broadly? For example, differences between sponsored/academic RCTs interpreted as industry trials being biased when there are plausible alternative arguments (e.g. Industry may have actually ran a better trial) and unrecognized potential biases on academic side (e.g. Being seen as defender against industry bias, more excited to publish contrary results, career pressure)?
difficult Q i think the cynicism is healthy, and in some cases well deserved eg gsk and avandia and dr nissen would inspire enough cynicism to last a career. But books like angell’s “the truth about drug companies” is poorly written for a lay audience (the huge font size makes this apparent) and not always well-informed. And you have this kind of fashionable cynicism from some academics now where the rct and methods of the industry are out-dated and even unethical, because “in the field” you must be pragmatic. Fact is, the industry produces the highest quality data there is anywhere in the scientific enterprise, and a statistician should be delighted to have access to it. On the other hand I follow the group from UBC “Therapeutics Initiative” and believe they provide much needed introspection/criticism/diversity of opinion (TI). And it makes me nauseous when i attend a medical conference and the pharma companies are boasting that they had 3 million abstracts accepted, or something completely ridiculous - this is how you make a mockery of science, and their marketing materials are plastered everywhere you look. Personally I have enough scepticism to apportion between industry and academia. Stephen Senn had a great saying, i don’t know if i read it or overheard it, he said something like “yes, it’s true, pharmaceutical statisticians sell drugs, but academic statisticians sell themselves”. Very true
Wanted to chime in on this thread for awhile. Better late than never.
There’s always more to learn! No shame in admitting that.
Mostly, worry a lot, occasionally checking my results in a different program when I have the time. Another good way to do it that some folks mention is feeding it a simulated created dataset where they “know” what the answer should be before running the analyses on your real dataset. I think that’s a good approach, but admit I don’t use it as often as I should (tbh, I am usually analyzing data with fairly well-worn SAS packages, nothing too exotic).
That seems about as rigorous as you can get on your own.
Probably. In my small/medium center (6 PhD and 3 MS analysts) we don’t have anything formal. Occasional informal “Hey, take a look at this” stuff, but our overall demand and workflow doesn’t have enough time for us to double-analyze everything. I think “industry” might have more ability to do this, but can’t be sure as I’ve not actually worked on that side of things.
Yup. I still do.
This kinda validates my above statement.
Yeah. I’m torn on open data for a couple reasons, but I do think even without data sharing, code sharing would be beneficial - you could at least look and see if it looked like the code someone wrote actually did what they said they did in their Methods - a few papers that @venkmurthy has drudged up from the FAME-2 study, it’s virtually certain that the authors did NOT do the analyses they claimed to have done, and my guess is that they don’t even know how to do it. If Venk chimes in, maybe he can link the original twitter thread where he turned that up.
Paul, I do respect the arguments put forth against code sharing that you’ve laid out there, but I’m not sure that I fully agree. I’m happy to share any SAS macros I’ve written (quite amateurish in comparison to many expert programmers, true). I do believe a rising tide lifts all boats in that regard.
Depends who you mean by academics. Twitter has at least alerted me to a fair number of us that are willing to speak rather openly about these issues. But you’re right that this is not the majority, for sure. Some people may not be aware of just how bad the problem is - I’ve found that a lot of biostats faculty who are engaged more in methods work and less in practice (that is not meant to be such a broad-brush, bear with me) probably don’t see quite what I’ve seen: just how much data analysis is performed by people untrained in doing so, and the sheer staggering volume of published papers with no statistical input or consult. We statisticians are not perfect and have our differences in how things should be done, but I’ve rarely seen an article with statistical collaborators that had something which truly horrified me as a statistician (your threshold for horrifying may be different from mine), whereas I see some ghastly errors when amateurs try to do it all themselves, like people using logistic regression to analyze survival data.
Of course, to show how well it goes over when one tries to discuss such issues: I also recently posted a (now deleted, RIP) Twitter thread calling out an article written with poorly analyzed data that happened to include 2 authors from my own institution, and said authors are still directly and indirectly bullying me and making noises about “repercussions” so you see how most people will react to such things. It’s an inconvenient truth for most people to confront.
Certainly a gold standard to aim for when the money is there such as major multinational trials and/or industry trials that are (hopefully) going to be scrutinized by FDA. Lots of us not working in that world, though.
I was a truly “solitary” statistician for about 5 years before moving to my current job. I did my best, lol. I still feel like a lot of my coding started out very well, then got progressively messier as co-authors redirected their paper, asked for new analyses, etc.
This is my fervent hope. In a bit of a positive sign, I’ve been asked to give 2 talks at my institution since I was quoted in an NPR article* about the Wansink scandal, so at least some people are paying attention.
*which, in a real shame, did a very poor job describing p-values and focused way too much on p-hacking as the specific root cause of the Wansink scandal and not enough on research methods as a whole
I didn’t know this, but it would make some sense to me.
Totally agree. I understand why this view once existed, but I think “industry” statisticians are held to a much higher standard than analyses performed in an academic setting. Jack Wilkinson (who doesn’t post here, but is active on Twitter) posted this depressingly-accurate statement today:
In this paper, the authors claimed to have analyzed the data using Cox proportional-hazards models. But the data in Figure 3 is just unadjusted relative risks, not hazard ratios - after Venk pointed this out, the authors just changed the label on the Figure…but that’s still not good! They should have reanalyzed this data properly! If the authors had to submit their code, it would’ve been more abundantly obvious (instead, Venk and I had to get out our abacus and calculated by hand to confirm that these were “RR” and not OR or HR).
yes. i remember a statistician (assoc prof i think) explaining that wansink was wrong because he didn’t adjust for multiple testing, he should have used a significance level of 0.00005 and if he did then nothing would be significant, And it was said with such smugness, although it’s the default thinking of someone who’s regurgitating an intro stats text
i think code should be provided in a lot of cases eg i saw a paper describing the value of competing risks analysis recently and the authors didn’t include their code. If they want to promote the method then they must include the code. On the other hand, if you write code for a study (not a methodology paper) it will be extra effort to fill it with comments to anticipate misunderstandings etc. A consultant once told me he deliberately makes his code so arcane that no one can understand it
i think some problems are inherent eg academia permits much more freedom than industry, and this is good and bad. I spoke to two academic statisticians recently: one uses R, the other uses SPSS (an epidem) and I use SAS. We couldn’t even read each other’s code. Re, your deleted twitter thread, in the industry the focus is on protecting the company’s reputation, not the individual’s, and thus readily admitting fault is natural; it’s the opposite in academia it seems eg wansink’s self-promotion has harmed cornell
that’s one reason the FDA are insisting on certain data standards (sdtm, adam) i.e. it’s easier for them to run analyses if all companies submit data in the same format
some random things i should mention before i forget:
for comparing code i use diffmerge, it’s free and it’s fantastic [download]. There’s a number of reasons you might use it for validation purposes eg if you rework code and want to compare it to the original to confirm no unintended changes occurred, or you find several versions of a program and want to compare them etc.
for comparing datasets i use proc compare in SAS: sas guide (I’m not sure if R has something like this). Eg, i had a client resend the data and ask me to run all the analyses on this new dataset. I used proc compare to determine what data had changed then asked why they’d changed!
it can be a good idea to create a check list to use when validating code so nothing is forgotten. Eg, in SAS there are certain words you should always search for in the log. … etc. But since none of you fancy people use SAS i’ll leave it there
I really like the “simulation to see if you can recover the truth” approach. But the slightly more pressing problem is checking derived variables and inclusion/exclusion criteria. That’s where we’ve found the most number of discrepancies between statisticians. I’d like to have better ideas for checking these, in addition to what I mentioned above about having independent analyses with different computer systems using dummy randomization codes.
Post-publication peer review is critical precisely because author eminence seems to weaken pre-publication peer review. The more I look, the more I see of this.
Sharing code isn’t always easy though for many reasons: IP, need to be more formal/comment than necessary for simple things, dependence on other code, etc.
Careful testing as you suggest shouldn’t be optional, but bugs will always sneak through. Its inevitable. Key thing is to be open to finding them.
Agree. Derived variables often have many issues. Simulation here is useful here to, especially to find strange corner cases. I found a few recently in my pooled cohort equations function that way (just implemented it… try it out if you want. [https://github.com/venkmurthy/vmtools] Only caveat is I need to have better options for how to deal with ages outside of range… currently it chooses one option which works for my current project but not for others).
First, given the amount of 3-d pie charts I’ve seen, and the fact that still many analyses are pasted directly from SPSS output, anyone just using R is mile ahead.
I think a great deal goes in code structure- the QA and reproducibility gets easier.
A good idea is analyses as packages, but it comes with a lot of overhead.
The minimum should be seperate import/clean functions, and a seperate Rmd file for analysis.
there are many quality control Qs that could be asked:
-how is the final analysis dataset protected and version control maintained? (if you simply sort a dataset you change the date/time stamp on it)
-is the log file (for the complete run) saved for documentation ie proof that it was run without incident? (you may have to defend your work)
-is hard coding avoided? is it flagged within the program if it occurs?
-how is quality assured after stats release outputs to clinical (note that clinical will go in and change headings etc and version control is lost and responsibility is diffused)
-is the code validated against the protocol and standard operating procedures?
-who has ownership?
-some promote a risk based approach [ref] but this offers up a justification for limiting validation
etc
i’m interested to know: do programmers produce the stats in the software and then enter them into a table by hand? I know nothing about R, i don’t know if it encourages such (bad) practice. SAS doesn’t of course (it has proc report, proc tabulate)
There is a lot of development in R for making “final” tables to insert (sometimes automatically) into others’ reports. Some of the tools are in these packages: Hmisc, tangram, htmlTable, kable, kabelExtra. We at Vanderbilt and researchers at Northwestern U. are working on automatic table inserts into Word. I think it’s important that manuscripts start being reproducible. In an ideal world everyone would use the same, much simpler, solution: Markdown.
It seems that David Gohel has done something like this already with flextable. https://davidgohel.github.io/flextable/ Could you build on what he has already done?
 i think the cynicism is healthy, and in some cases well deserved eg gsk and avandia and dr nissen would inspire enough cynicism to last a career. But books like angell’s “the truth about drug companies” is poorly written for a lay audience (the huge font size makes this apparent) and not always well-informed. And you have this kind of fashionable cynicism from some academics now where the rct and methods of the industry are out-dated and even unethical, because “in the field” you must be pragmatic. Fact is, the industry produces the highest quality data there is anywhere in the scientific enterprise, and a statistician should be delighted to have access to it. On the other hand I follow the group from UBC “Therapeutics Initiative” and believe they provide much needed introspection/criticism/diversity of opinion (
i think the cynicism is healthy, and in some cases well deserved eg gsk and avandia and dr nissen would inspire enough cynicism to last a career. But books like angell’s “the truth about drug companies” is poorly written for a lay audience (the huge font size makes this apparent) and not always well-informed. And you have this kind of fashionable cynicism from some academics now where the rct and methods of the industry are out-dated and even unethical, because “in the field” you must be pragmatic. Fact is, the industry produces the highest quality data there is anywhere in the scientific enterprise, and a statistician should be delighted to have access to it. On the other hand I follow the group from UBC “Therapeutics Initiative” and believe they provide much needed introspection/criticism/diversity of opinion (