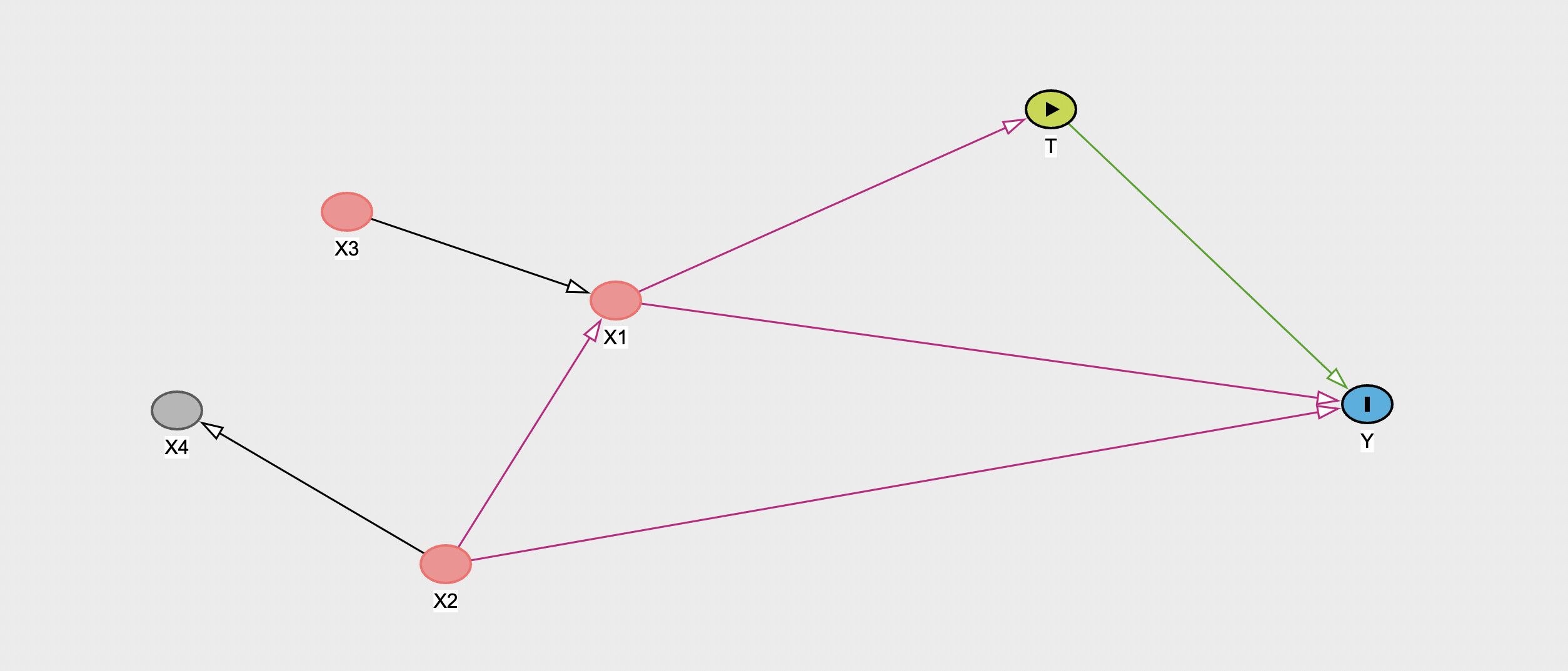
I am quite new to causal inference and want to try some methods for treatment effect estimation. For this purpose, I created a the following data generation process in Python:
My question is: Since X2 (according to the data generation) does not influence the assignment of T but does have an influence on the treatment effect itself, is there an edge between X2 and T (X2->T) required?
A causal arrow between X2 and T is not required for the reasons you list. The directed acyclic graph tells us that variables X1, X2 and T jointly and causally effect the outcome Y, but doesn’t specify how they do so. We know from the data generating process that a specific interaction tau exists between X2 and T, but this kind of additional statistical information is not encoded in standard DAGs.
Thank you so much for you reply! So for estimating the CATE (e.g. with econml) for each level of X2, the set of covariables X has to include {X1, X2} (since only X1 the backdoor adjustment)?
Based on the DAG you provided, to estimate the causal effect of T on Y you only need to adjust for X1. By doing so you will remove the confounding effects of X1, X2, and X3. Because X2 influences Y, you may also include it in your model (along with X1) to reduce outcome heterogeneity and thus increase the precision of your estimate (or the power under the null if the outcome is a non-collapsible outcome metric). Including X2 will not further reduce confounding bias. X1 is enough to do this.
Regarding your other question, the decision on whether or not to have X2 influencing T will be based on what you think the data generating process is. If you do decide that X2 influences T independently of X1 then your model needs to include both X1 and X2 to remove the confounding bias.