I have some survival data and 2 variables of interest. 1 variable is a current gold standard for treatment decision in a clinical setting. The other variable is a derived score that containing a non-linear combination of several gene’s expression values along with the gold standard variable.
My interest is in comparing a ‘gold standard model’ to a ‘derived variable model’ in a to a time to event setting. The 2 models would be set up exactly the same (run on the same data, same covariates, etc.). However, these are not truly nested models as the derived variable is not computed additively so I don’t believe a conventional LRT can be used. Is there another comparison that I can make that is more appropriate to statistically compare these models?
Extra info - the derived var is of the following flavor: exp(gene1 + gene2 + gold standard)
First make sure that the two models involve the same amount of overfitting, e.g., had the same number of candidate features. Otherwise they may not be comparable. Given that’s not a problem, you can pick one of various measures (see e.g. here) to quantify predictive ability and compare them. If you don’t need to quantify uncertainty that’s it. Otherwise you could bootstrap the model development and fitting processes in parallel to get bootstrap confidence intervals for differences in performance indexes.
You may also be able to compare AICs on non-nested data.
Great!
I really enjoyed the link and information contained. I was hoping to provide a little more background to hopefully get some discussion on what I have done and its appropriateness.
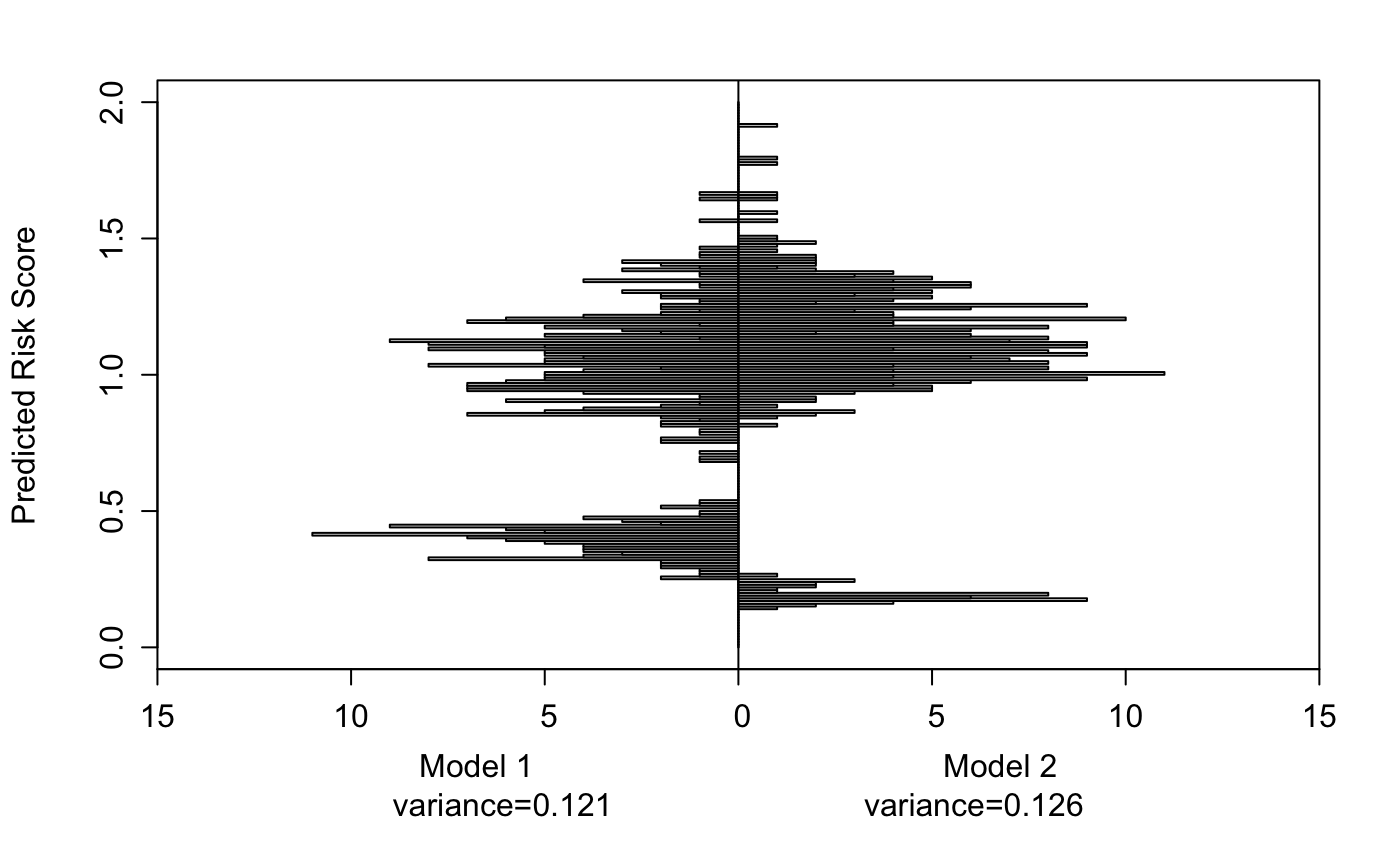
The variance of the predicted values is very similar here and Model 2 will actually captures more information.
I was wondering about utilizing the U-statistic that is also brought up in the article in rcorrp.cens(x1, x2, S) and want to make sure I am implementing the comparison correctly.
Would I let x1 = predicted values from Model 1
x2 = predicted values from Model 2
So rcorrp.cens(predict1, predict2, Surv(df$time, df$event))?
Or is the intent of x1 and x2 to be vectors of actual DerivedVar and GoldStandard data?
I think that’s correct. Will not take into account uncertainties from model fitting.
Without a gold standard, you might start with getting a bootstrap confidence interval for differences in predicted probabilities as was done with the impactPO function example in the RMS course notes. The particular two models you mentioned will not differ except for the difference between partial likelihood and full likelihood. Could also try rcorrp.cens.