There are studies where the effect size of an exposure on treatment response is small and not statistically significant when modelled as longitudinal change, yet the same variable, when dichotomised, show dramatic effect sizes.
I can only assume there is some underlying methodological issue, but am not smart enough to figure out what! Can you?
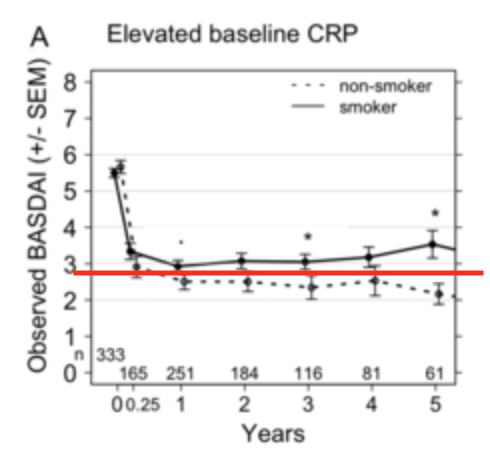
Here is one example when studying the effect of smoking on treatment response. The authors used mixed models to compare differences in a continuous outcome variable (called BASDAI: a disease activity index bounded between 0 and 10) according to smoking status. There was no difference between current and never smokers. (They didn’t give the overall effect size, but just to give you an idea: in a subanalysis where they did find a significant difference, the effect size was less than clinically meaningful difference of 1.)
However, when they used logistic models to study a binary version of this outcome (50% reduction, imaginatively called BASDAI50), the odds of achieving this response was reduced by approx 50% in current compared to never smokers!
My immediate thoughts are that outcomes other than non-response are being bundled into this binary variable (can’t meet response criteria if I stopped the drug due to an adverse reaction, or death!). But many such papers, including this one, are in very prestigious journals (I know what you’re going to say…), leading me to think whether there was cleverer explanation?
I don’t think this paper accounted for informative dropout in their longitudinal models but other studies have shown that additionally using inverse-probability censoring weights did not significantly change results.
it may just be an artefact of that particular dataset. the argument usually runs in the other direction. Eg senn runs a data simulation of placebo v paracetamol for pain relief and shows that if every hypothetical patient has migraine duration reduced by 25% under paracetamol (ie every patient benefits) then using a dichotomous outcome of “reduced pain within 2 hours” leads to the spurious claim that 10% of patients ‘responded’:
this doesn’t answer your Q, but it is a nice illustration…
From the paper (red line mine to indicate approximately 50% reduction):
If you dichotomize, you throw out information. Here, people with a 49% reduction are treated as equal to people with no reduction. People with 51% reduction are treated as equal to 90% reduction. 49% and 51% are treated as if they are very different. If it so happens that the average effect in the two groups fall on either side of this line in the sand, the effect gets amplified.
(should include disclaimer that 50% reduction may in fact be a meaningful threshold - I have no idea. I’m just attempting to explain why the dichotomized results come out significant and the continuous ones don’t)
Sorry for not bringing actual references, but IIRC in pain the proportion of 50% reduction is preferred over (or at least besides) the mean reduction, because the effect can be quite bimodal.
“in pain the proportion of 50% reduction is preferred over (or at least besides) the mean reduction, because the effect can be quite bimodal.”
The effect being bimodal is not a very good argument for “50% reduction” rather than mean reduction, though, because it treats a 49% reduction as a failure and a 51% reduction as success even with a minimal difference between those two outcomes, as @randy noted above.
If half of the treated population experiences a 45% reduction and the other half of the treated population sees 20% reduction, the “mean reduction” is about 32.5% but a “50% reduction” outcome would conclude that the treatment is wholly ineffective.
If half of the treated population experiences a 65% reduction and the other half of the treated population sees zero reduction, the “mean reduction” is still 32.5% but now the “50% reduction” outcome sees the result very differently, with half of the patients meeting the threshold for success.
Admittedly, the two results described here would have somewhat different implications, which is why we need more nuanced descriptions of results, but I am not sure that the dichotomized result offers an advantage (it may be a useful adjunctive piece of information but should not be considered valid as a primary endpoint, I would think). @f2harrell may point out that the most informative possible presentation of study results would be some sort of curve presenting the probabilities of a given patient experiencing > X% reduction, but I’d have to think about it some more.
Good points Andrew. There are very few variables that meet all the assumptions required for subtraction or division, and it is best to not make those assumptions. Pain scores with their floor and ceiling effects are especially problematic. It is almost always best to treat the patient response as a separate variable, treat it is ordinal and not interval (to handle weird distributions) and nonlinearly covariate adjust for baseline. From such a model you can compute any quantity of clinical interest. The most important quantity is the probability of having pain severity worse than y given baseline pain level x.
That there are two classes of binary responses: proportional reduction (eg 50% reduction), and a disease state (eg “remission” or patient-acceptable symptom level defined by a fixed low cut-off). Whilst it’s difficult to defend the former no matter how much more “interpretable” it is, there is some sense that, as a patient, I care more about the chances of my disease being treated to an acceptable level, than by how many units my symptoms are reduced. (Although the latter is so often the defence given for proportional reduction too.)
Is there an ulterior motive for many clinical trials to use binary response variables? I’d imagine dichotomising continuous variables would be counterproductive for power. In the paper I cited for this journal club, and other similar ones, the main defence for using binary response variables is that clinicians are familiar with these outcomes from the world of RCTs.
I do think it’s acceptable (and even desirable) to report certain outcomes like this, no doubt.
I simply caution against their use for comparative-effectiveness inference because of their potential noisiness and sensitivity to choice of different thresholds (admittedly, part of this is our statistical-significance paradigm, where a difference between groups might be “statistically significant” at p<0.05 if the threshold of success is “30% reduction” but not “statistically significant” if we changed the threshold for success to “50% reduction”)
The idea of what patients deem a good result is important here. In our work with patients getting back surgery we asked what best predicts their overall ordinal level of satisfaction with the surgical outcome at 12m, given their pre-op disability level and their 12m disability level. Patients clearly did not care about the change in functional ability. The 12m scale was what predicted their current satisfaction level, and the baseline scale was irrelevant. This teaches me that outcome variables should also be absolutes, i.e., current status (ordinal or continuous) adjusted for a smooth nonlinear function of the baseline value.