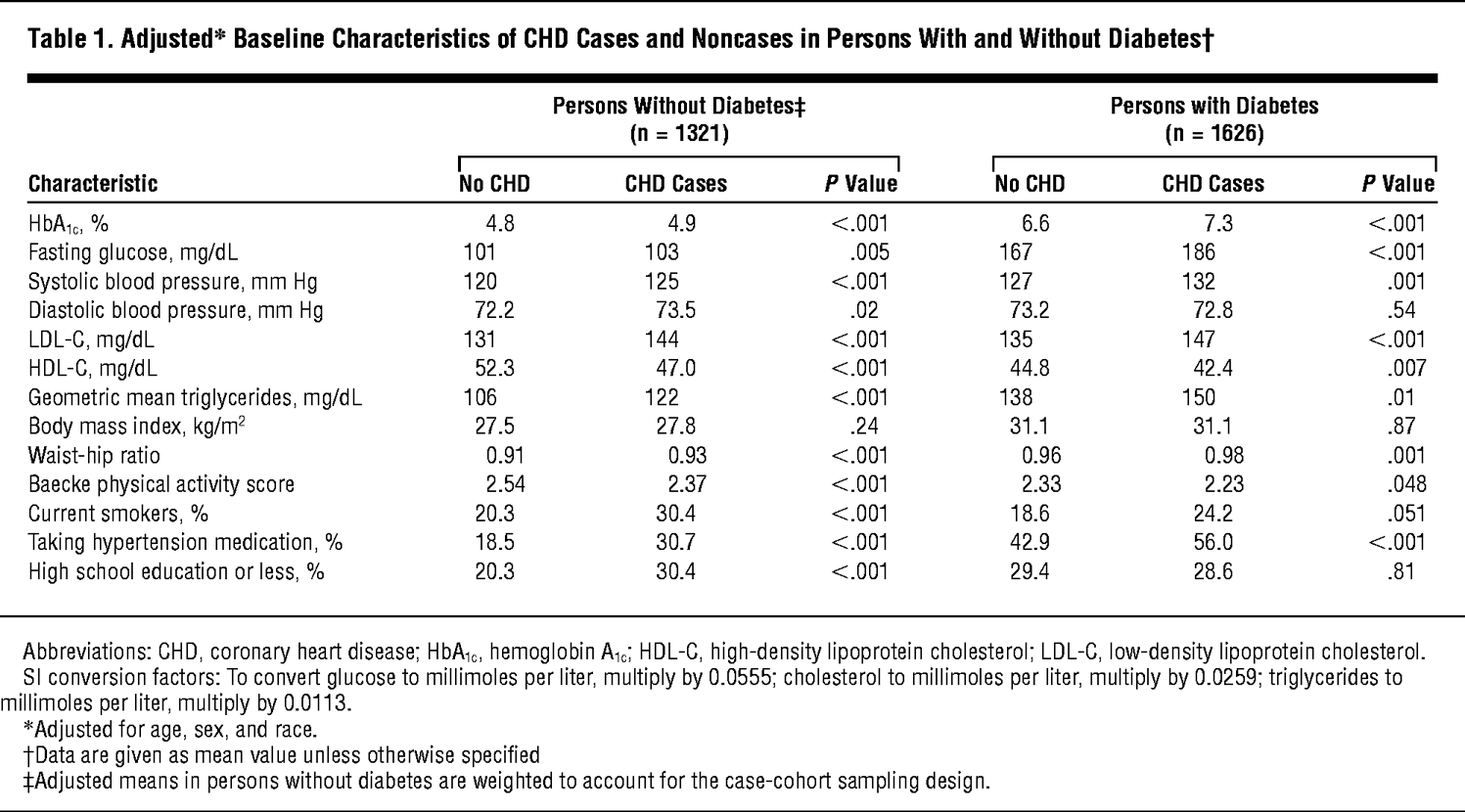
I found that several studies showed the adjusted baseline characteristics including proportion in Table 1. The adjusted means could be calculated by estimated marginal means (right?), but how could calculate the adjusted proportion? I remember the adjusted prevalence (or rate) could be calculated based on a reference population (the direct method). Is it applicable for this situation?
I don’t think so. At the same time i’m curious how others did that.
Thank you very much professor.
The goal is to show the baseline characteristics. It is not a ultimate goal. For exmaple, before analyzing the association between an exposure like diabetes and mortality, we often show the baseline characteristics in people with and without diabetes. My boss suggested me to show the age- and sex-adjusted baseline characteristics. Age and sex were often suggested to be adjusted.
I’ve never seen a paper that does an age and sex adjustment when attempting to show descriptive statistics for baseline distributions. That’s not to say that it doesn’t have meaning; it’s just unconventional. It also depends on whether you are wanting to adjust to an external population distribution (which would require a lot more information) or to adjust to a single value of age and sex.
Thank you for your kind comments.
Many researchers in our groups used the adjusted characteristics in Table 1. I feel confused too after learning more statistic knowledge. I learned a lot from your careful explanation and I will read that helpful post.
I agree with Frank that adjusted table 1 is unconventional and plausibly misleading.
But let’s separate the two issues - first presenting the adjusted descriptions of covariates, and second the stratification over an outcome (e.g., diabetes).
Commonly, Table 1’s main purpose is to describe the sample you analyzed in the study.
It’s a descriptive tool to get a sense of who is in this study, anyway? to assess the generalizability of its findings.
Presenting (age and sex) adjusted covariates slightly shifts the table’s task from a descriptive one to an inferential one, and it is advised to avoid mixing the two.
Furthermore, it also obscures the information of the baseline covariates you adjusted for, which are undoubtedly important or otherwise you wouldn’t have adjusted for them in the first place.
This is not to say that presenting adjusted table 1 is always wrong, but if you chose to do unconventional things then the burden of justification is on you.
As for presenting stratified table 1, I’m usually in favor. However, the stratification should be based on a criteria participants enter the study with. Therefore, stratifying on an outcome (which is usually not known on baseline but only at end of follow-up), is not informative and will just surface up prognostic differences (that will probably be accounted for in the outcome modelling the study most-plausibly have anyway).
Note that this rule also accommodate the “exception” of case-control studies, in which participants are enrolled based on their outcomes, and thus making the only reasonable example I can think of that where it might be informative to stratify on an outcome.
For example in prostate cancer research, the most important risk factor is age followed by PSA (prostate-specific antigen) level. PSA is strongly age-related. If you adjust PSA for age you’ll take away much of its prognostic value.
During my PhD, many people recommended me to make an adjusted table 1 and they think it is thoughtful for readers to obtain more information. And most time I learn data analysis by reading previous studies, which have no explanation on why they did that. Now I found how naive I did in previous work. I am very pleased to receive your careful explanation. Thank you very much.