I am a clinician trying to understand the methodological framework behind recent cardiovascular prevention guidelines, specifically the 2026 AHA/ACC Lipid Guidelines and the accompanying AHA Scientific Statement on Clinical Utility.
I have been trying to reconcile how treatment thresholds are set and how new markers are justified for reclassification. I would appreciate the community’s insight on three specific areas:
1. On the use of NNT-based Net Benefit to set thresholds
The guidelines often utilize the Number Needed to Treat (NNT) to conduct a form of net benefit analysis to determine treatment thresholds (e.g., the 3% threshold for statin use as shown below). As a clinician, I’m trying to understand if this is a statistically sound way to define a decision point.
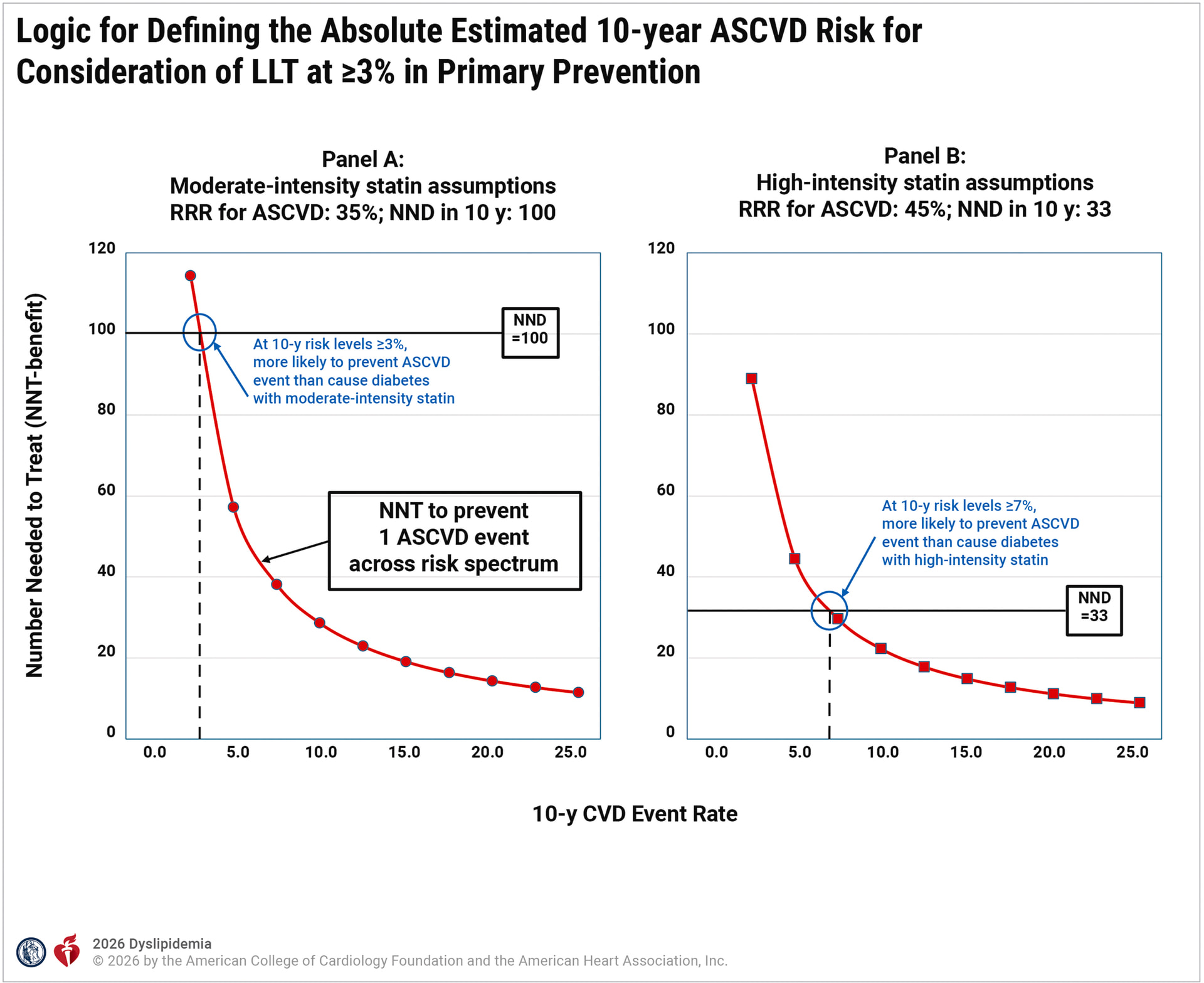
-
I understand that NNT is non-linear and varies with baseline risk. Is it still a reliable “anchor” for population-level guidelines?
-
Are there nuances in the harm/benefit ratio that NNT might overlook compared to a continuous probability-based framework when doing decision analysis curves?
2. On the role of NRI in justifying clinical tools
While the guidelines use the logic above for thresholds, they often pivot to the Net Reclassification Index (NRI) to justify the “added value” of new markers. I am curious about the following:
-
The Weighting of Events: How does NRI “reclassify” an existing decision threshold? Are the non-event and a event still weighted equally? Is this considered a valid approach to “reclassification”?
-
he “Hidden Costs” of the Marker: Unlike a risk score, a physical test like CAC introduces its own harms—radiation, incidentalomas, and downstream testing (stress tests, etc.). If a tool achieves a 20% NRI but triggers a cascade of low-value downstream procedures, how is that “tax” accounted for?
3. On the compatibility of these frameworks
Can these two approaches be used together consistently? We seem to use a decision-analytic framework (Net Benefit/NNT) to establish the threshold, but then evaluate a marker’s utility using a different framework (NRI) that does not appear to incorporate those same clinical weights.
-
Are these frameworks fundamentally incompatible for guideline development?
-
Would a consistent Decision Curve Analysis—applying the same weighting of harms and benefits to both the threshold selection and the marker evaluation—be a more appropriate standard?
Any thoughts, comments, or useful references on this would be appreciated. Ultimately, I want to help clinicians like myself work with patients to make informed decisions, and find the best ways to do this.