For some pragmatic trials, electronic health record system (e.g., Epic) generates random number that is used to randomize initially eligible patients to treatment arms. After the randomization is performed, some patients are excluded if they meet predefined exclusion criteria (based on baseline data - e.g., baseline lab values), and the remaining patients will be enrolled. All these process is automatic and the assigned arms will not be revealed during the exclusion until each patient is enrolled. Thus, no bias due to human factors is expected. Can this final cohort be considered as the intention-to-treat (ITT) set? It is not a standard ITT set, but it may not be a standard modified ITT set either. What would be the best terminology to call this type of analysis set?
Another related to question is that as more than 10 exclusion criteria (which are not completely random and independent) will be applied after the randomization, could this increase chance of imbalance, which may yield bias?
This question may be simplified as follows. Let’s say it is a traditional trial. The randomization to treatment arms is done first, and then some subjects are excluded based on predefined exclusion criteria. However, the randomization will not be revealed during the exclusion until the final cohort is obtained. Should this cohort be called ITT Set? If this is not called as ITT Set, what would be the reasons?
This is a pretty cool causal inference question that I have not encountered before and would love to hear what others think about this too.
From a terminology perspective, neither ITT nor mITT seem appropriate as they are typically used in studies where the exclusion criteria are applied prior to randomization. Here we have a process that excludes patients before they even start treatment, based on predefined criteria. Given the unique nature of this scenario, it might be best to describe it in clear terms such as “pre-” and “post-” randomization exclusion analysis sets etc. Curious to see if there is literature providing definitions.
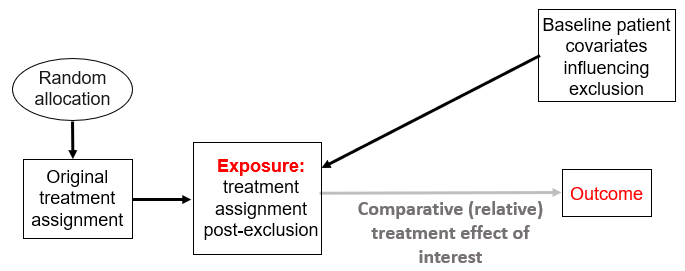
From an analysis perspective, this is certainly a causal inference problem whereby the predefined exclusion criteria will allow patient covariates to change their propensity score to something different than 0.5. Using the graphical approach we adopted here to interrogate RCT designs, we can see that at minimum there will be this causal structure:
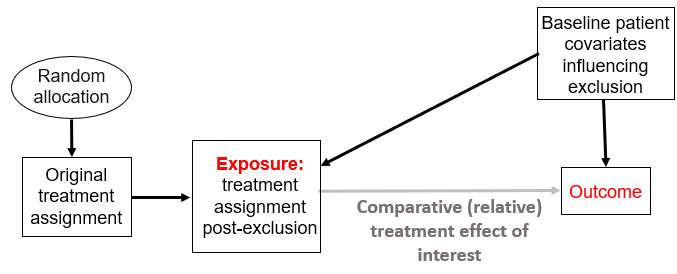
Which on its own does not require matching or other covariate adjustment method as this can reduce power and precision without improving bias (see Figure 6 here). And this takes us to the question on bias, which will happen if these covariates can also influence the outcome as shown here:
This is classic confounding bias and definitely merits adjustment. Note how the original treatment assignment here may act as an instrumental variable if our assumptions above are correct.
yes, it can, but i think the terminology is ‘full analysis set’, ie itt is the principle that leads to fas, ie itt is not an analysis set, even though many refer to it this way. They made this distinction because it is sometimes impossible to satisfy itt, examples are given in ich-e9 eg no post-baseline data. I don’t like the terminology ‘modified itt’, i don’t think it ever made sense and few still use it
Pavlos- your diagrams are really helpful. Is this a situation that highlights the difference between confounding “in expectation” and confounding “in measure” Counfounding and effect modification “in expectation” versus “in measure” (?) Since there is no human involvement in the post-randomization exclusion process described in the original post, we would have no reason to expect that baseline patient covariates would be associated with exposure, yet we might observe/notice, following randomization that certain covariates ended up being associated (statistically) with exposure…
I have never been involved in designing an RCT and have no idea how an EMR system might be involved in randomizing patients in a pragmatic trial. I assume that the EMR could be used initially to identify a pool of potentially eligible patients based on the inclusion criteria (e.g., identify patients with the disease in question). But why couldn’t the EMR then be used to identify exclusion criteria among those in the initial pool, thereby generating a “final” pool of patients who will subsequently be randomized? Wouldn’t this process circumvent the concerns about confounding you are describing?
I think the use of “ITT” in practice confuses people because I see it used to describe things at two different levels:
who should be included in the analysis
what “group” they should be analyzed in
IMO some people learn/internalize the idea of “ITT” to mean “everyone who was randomized should be in the analysis set” while others learn/internalize the idea as “everyone who is analyzed should be analyzed according to their assigned treatment” and this creates some confusion.
The decisions about “who should be in the analysis set” and “what group should they be analyzed in” are, in my opinion, separate - yet I often see these bundled into a single statement e.g. “the ITT set” or “the per-protocol set” etc.
From my perspective…the purpose of doing an “intention-to-treat analysis” is to preserve benefits of randomization and avoid biases introduced by any systematic factors that would result in people not receiving the treatment they were assigned (e.g. clinicians making decisions to use the “active treatment” rather than “control” in the sickest patients, thereby diluting the apparent benefit of the “active treatment” arm).
So in your specific case, the fact that a larger population is first “randomized” and then some people subsequently excluded because they did not meet inclusion criteria is kind of irrelevant to your actual question. Were you to put this in the estimands framework, I think you could argue that these people are never in the target population and therefore irrelevant to the final question of interest anyway.
IMO, you are still following the “intention to treat” principle if you analyze the remaining subjects according to their “assigned” arm (regardless of whether they received the full dose of intervention, crossed over, etc) and the fact that some of the randomized people are subsequently deemed ineligible (before “enrollment” or treatment is initiated) is essentially irrelevant to your scientific question. TBH I do not see how their exclusion (since it is presumably made on a purely objective / automated bases from what you have said) would increase chance of imbalance or yield bias, but maybe I am misunderstanding something.
Thank you for sharing your thoughts. That is exactly the first question I asked, which will solve any potential issues down the road, but they said it is not feasible at this point or do not want to make efforts to change it (presumably it would take substantial efforts to change although it could be changed in future).
Great question as usual. As we discuss in Section 22. “Systematic and Random Biases” here the above diagrams focus on confounding “in expectation” as opposed to what we call there “realized” confounding (also known as “in measure”). To better interrogate confounding “in measure” the graphs can be modified, e.g., into single-world intervention graphs (SWIGs). There is a cool Statistics in Medicinearticle we cite that nicely introduces SWIGs for interrogating trial designs.
We will have a clinician joining our faculty group who did his PhD directly under the group that developed SWIGs. He will certainly be eager to popularize these ideas more, but if other clinicians or applied statisticians / data scientists take the lead then this can make all our lives easier
I believe @choileena is thinking of confounding “in expectation” and the above graphs suggest that the scenario where the patient covariates that influence the exclusion also influence the outcome would cause such confounding.
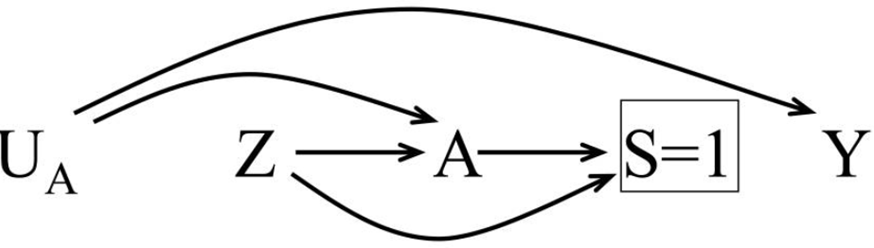
I believe that @choileena’s design first automatically randomizes among a group of patients, then automatically excludes some of them based on predefined exclusion criteria, and then the excluded patients do not receive the predefined intervention. If that understanding is correct then the above diagrams / considerations apply. The original randomization could be used as an instrumental variable as long as it does not directly affect the outcome of interest (exclusion restriction for instrumental variables, see causal diagrams in Box 2 here).
There are a few parts of the original question that I don’t understand, probably because I’m not familiar with pragmatic trial design.
Here’s a hypothetical clinical scenario that corresponds to the pragmatic trial design outlined in the original post:
Let’s pretend that we’re designing a pragmatic trial to assess the “real world” effectiveness of a new analgesic drug against the standard of care drug for knee osteoarthritis.
Step 1: We ask our EMR system to generate a potential pool of patients to enrol in our trial. The EMR identifies all the patients in the hospital database who have knee osteoarthritis;
Step 2: The EMR “randomizes” the identified patients to the new drug or the standard of care drug;
Step 3 (according to the design presented in the original post): The EMR takes a “second look” at the patients who have been randomized and then automatically applies certain pre-defined exclusion criteria.
Questions:
I’m assuming that consent isn’t needed for participation in a “pragmatic” trial, since such trials are usually assessing “real-world” effectiveness of an already-approved treatment (?) This must be the case, otherwise I don’t understand how you could arrive at the point of randomizing patients to a treatment before you obtain consent for their participation (?) In turn, if you must still seek consent before randomizing, even in a pragmatic trial, I don’t understand why you would even offer to randomize patients before checking for exclusion criteria (see below);
Assuming that consent is not needed for enrolment in a pragmatic trial, what types of exclusion criteria would we be applying in such a setting that we would also expect to be prognostically important (vs simple contraindications to treatment), and therefore potentially biasing? I thought that the whole point of doing a pragmatic trial was to test the clinical effectiveness of a therapy (i.e., how it behaves “in the real world”). In a pivotal efficacy trial being used to support drug approval (i.e., a “non-pragmatic” setting), we might want to exclude patients with cognitive impairment. We might expect cognitive impairment to be a prognostic factor, in the sense that these patients might be sub optimally adherent to the new treatment, thereby potentially obscuring its efficacy signal. In contrast, I wouldn’t expect that a pragmatic trial would seek to exclude such patients- otherwise, it wouldn’t be called “pragmatic”… On the other hand, if the drug in question contained a sulpha moiety, maybe I would want my pragmatic trial to exclude patients with a known sulpha allergy. But I wouldn’t expect sulpha allergy to be a prognostically important covariate…
Thank you so much to all for sharing your thoughts and suggestions. Those are all great! I will take time and think through them before replying any of your comments.
@f2harrell posted this question in twitter and there was a request to share their twitters here. See the following twitter post:
Your assumption is correct. No consent is necessary (minimum risk for the intervention - the treatment is intervention and not efficacy trial).
Let’s just call “drug” for the drug of interest for the intervention
Some examples of exclusion criteria in general terms
Already on the drug of interest
Pregnant or lactating
Palliative care
Allergy or adverse effect related to the drug of interest
Rhabdomyolysis
Drug contraindicated due to liver disease, defined as 1) Decompensated liver disease, 2) AST or ALK >5 times the upper limit of normal, or 3) Total bilirubin > 1.5 mg/dL.
Drug contraindicated due to kidney disease, defined as 1) Dialysis or 2) Estimated glomerular filtration rate < 15 ml/min/1.73 m2.
A lot, but not all, of these exclusion criteria could influence commonly used clinical outcomes, i.e., they are prognostic factors. These include “already being on the drug of interest”, “palliative care”, and “liver disease”. I just realized that Mansournia et al. have described a related situation in Figure 1c here whereby the decision to adhere to the assigned treatment is influenced by prognostic factors:
Take a look at the paper and let us know if this, or other scenarios described there, indeed describes your design. The DAG is more accurate than the ones I used above because they encode nicely via the S node (S=1) the information that the final sample of patients used is different than the one originally randomized. But the conclusion is the same: the prognostic factors leading to selection via the exclusion criteria act as confounders “in expectation” that need to be accounted for.
From a terminology perspective (following also what we describe in Section 16 and Figure 9 here) you could describe the original randomized patient cohort (prior to applying the exclusion criteria) as the “ITT” cohort (which you will not analyze), the ones assigned to the treatment after the protocol-specified exclusion are the “per protocol” cohort and then the ones who actually took what they were assigned to will be the “as-treated” analysis, which would require further adjustment. But again, your scenario is unique enough to merit more tailored terminologies as needed. Pick and choose
After skimming the Mansournia paper, I’m not sure that this pragmatic trial scenario corresponds to Figure 1c in the paper, since there is no opportunity for patients to “adhere” to therapy if they aren’t even given the opportunity to be exposed to the treatments being tested (due to post-randomization application of exclusion criteria).
At first I thought that the scenario might better reflect “Attrition Bias,” which is described in the paper as:
“…the result of systematic differences between groups in withdrawals from a study. The source of bias is differential loss-to-follow-up (e.g., drop out) or other forms of exclusions from the analysis.”
I’m slightly confused about this definition though, since it feels like exclusions from a trial should not be treated the same way as withdrawals (?) In my mind, the term “withdrawal” implies some element of choice among patients who have been offered a treatment, whereas choice doesn’t come into play in a scenario in which the patient is excluded before they have any chance to take the treatment to which they have been randomized.
This is hurting my brain, so I’ll end by articulating the question that the study seems to be trying to address (?): “Among patients in a real-world setting who are considered eligible for either one of two treatment options for condition X, which treatment seems to be superior?”
I agree with you that this is a very interesting problem.
Yup. It is a unique scenario but it may actually be easier than the standard “per protocol” described by Mansournia et al for the following reasons:
We know exactly the confounders influencing the “per protocol” treatment.
There are no time-dependent effects. The impact of these confounders is instantaneous.
For @choileena’s design, this “per protocol” analysis is the primary goal. If we want to analyze the scenario whereby the treatment does not follow the “per protocol” assignment due to patient choices or other unforeseen events, that analysis can be called the “As treated” one. Anchoring to such established concepts may be preferable at least as a starting point. At least until we find they are completely wrong
All this brings back the trauma (or was it fun?) of unpacking and analyzing for years upon years the transition states of a complex dynamic treatment regime RCT in kidney cancer. We still have not published it. Hopefully in 2024!!
Have you spoken with other researchers who have run pragmatic trials using EMRs? How did they go about applying exclusion criteria i.e., are there any published pragmatic trials where exclusion criteria were applied post-randomization? If so, how did those researchers address concerns about potential biases?
If you can’t find any other studies with a similar design to yours, it seems that you would be justified in asking your research team why they are insisting on applying the exclusion criteria after randomization (rather than before randomization) (?)
Finally, I’ll note that your list of potential exclusion criteria includes a number of conditions that might not be very easy to identify reliably without a detailed chart review and/or patient interview (as compared with allowing the EMR to search for relevant diagnostic codes or lab test results). For example, how would the EMR be able to tell whether a woman 1 year postpartum is still breastfeeding? What criteria would be used to “automatically” identify patients who are in palliative care? How would an EMR automatically be able to distinguish between patients with compensated versus decompensated cirrhosis?
Maybe EMRs are able to do all these tasks reliably without human input/chart review- but somehow I doubt it (?)…And if the EMR can’t apply exclusion criteria reliably, such that human involvement will be needed for their application, then why not just insert the human involvement prior to randomization, thereby alleviating concerns about introducing bias into the process?