This might sound stupid but if I understand the decision tree correctly, initiation of the treatment does not change the absolute risk for the related outcome:
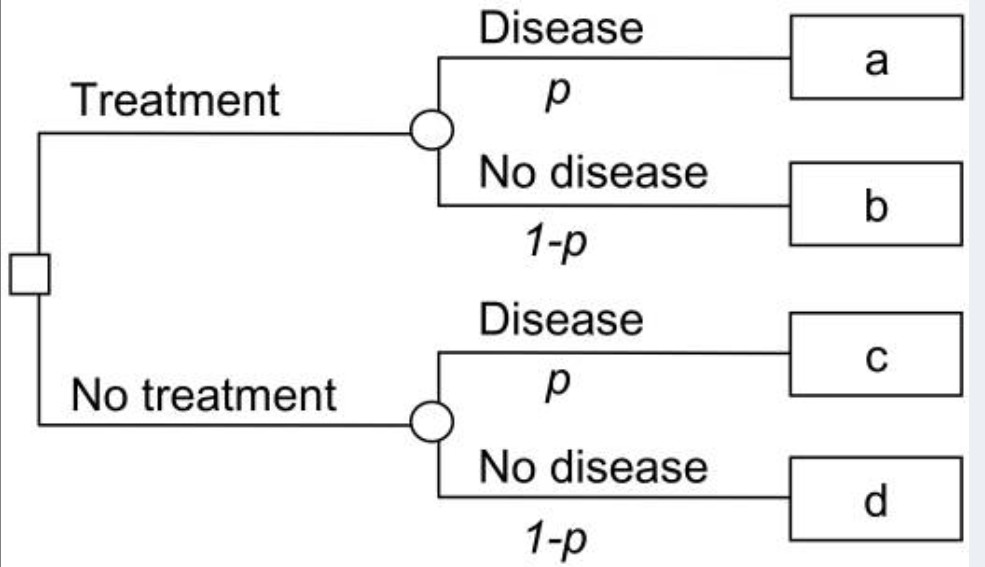
Is that so? @VickersBiostats
This might sound stupid but if I understand the decision tree correctly, initiation of the treatment does not change the absolute risk for the related outcome:
Is that so? @VickersBiostats
This is a misunderstanding of the underlying mathematical basis of decision curve analysis. If treatment changes the absolute risk, this is reflected in the utility (a). To give a trivial example: if “disease” is death, the risk of death is 50% in untreated and 25% in treated, then (assuming no harm of treatment for the sake of simplicity) then d=1, b=1, c=0.5 and a=0.75. Decision curve analysis is based on expected utility: probability x utility. You can modify either probability or utility to get the same expected utility. For instance, a 100% chance of a utility of 0.5 is the same as a 50% chance of a utility of 1 and a 50% chance of a utility of 0.
Maybe my confusion comes from the different possible perspectives for diagnosis and prognosis.
In your original article it seems more like diagnosis to me:
p is the probablity of disease, and a, b, c and d gives the value associated with each outcome in terms of quality-adjuated life-years.
While the disease=death example is more of a prognosis.
I thought about this issue for several days and to be honest I’m still not sure if I understand your interpretation of p in cases of prognosis.
To me it’s much more reasonable to use counterfactual predictions in cases of prognosis and than use the decision tree from your article Method for evaluating prediction models that apply the results of randomized trials to individual patients:
There is no distinction mathematically. In both diagnosis and prognosis, we have information about an X (e.g. PSA level, blood pressure) and want to make inferences about Y (e.g. whether patient has prostate cancer, whether patient will have a heart attack). DCA is completely agnostic as to whether Y is theoretically knowable at current time (e.g. prostate biopsy) or only after follow-up (e.g. heart attack within 5 years)
The math is fine, but the concepts are different and tend to mislead from my own experience:
For Diagnosis (Factual Predictions) Treatment+Disease is a good thing (TP) because we would like to find an undiagnosed present disease, for prognosis (Counterfactual Predictions) the Treatment+Event is the worst path because we tried to prevent the event from happening but we didn’t succeed and paid the price in terms of both treatment harm and event.
For Diagnosis biopsy for someone who has a prostate cancer is a good thing, for prognosis if a patient takes statins and suffer from heart attack in the followup it’s a bad thing.
No, because treatment reduces the risk of the event (which gets reflecting in the utilities). A true positive means “treating a patient destined to have an event”, which is a good thing, it is what you are supposed to do.
I ment worst path not in terms of decision, but in terms of result. Do you agree with that?
In terms of utility:
1 - Event - Treatment < 1 - Event/Treatment < 1
no, worst result is either false negative (if threshold probability < 50%) or false positive (if threshold probability >50%)
