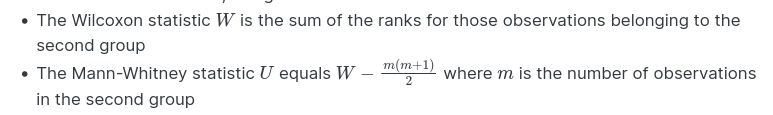I am reading Discovering Statistics using R by Andy Field. In the section about how to calculate the rank statistic in MW, one of the steps is to subtract the mean rank from the sum of ranks.
W = sum of ranks − mean rank
The idea being, that it corrects for the number of people in the group.
But what we are subtracting is not the true mean of the summed ranks, but the minumum mean (there are ten observations, and the sum is [1+2+…+10], whereas the actual ranks are 1,2,3.5,…12, because of ties.
what does this procedure do in this context? I am not a very math-literate, so an intuitive understanding of what is going on would be helpful
As far as I can see, even if this is not done, the conclusion we draw from test would remain the same.
I asked this question on stats.stackexchange and the answer I was given there was it doesn’t matter. Is this correct? context: Subtracting the ideal-rank-mean in Wilcoxon rank-sum, what does it do - Cross Validated
Thank you