An essential aspect of interpreting study results for p-value>0.05 is appropriately looking at confidence interval (CI) end-points. Unfortunately, the current evidence of practice suggests that many clinicians are failing to do this. As an experiment, I evaluated one of the most popular text books for teaching EBM to clinicians, the “JAMA User’s Guide to the Medical Literature, 3E” (https://jamaevidence.mhmedical.com/Book.aspx?bookId=847). I looked at 2 different chapters which used examples of study results with p-values>0.05. I then looked to see if CI were provided with each p-value, and if the CI endpoints supported the claims in the text. This is what I found:
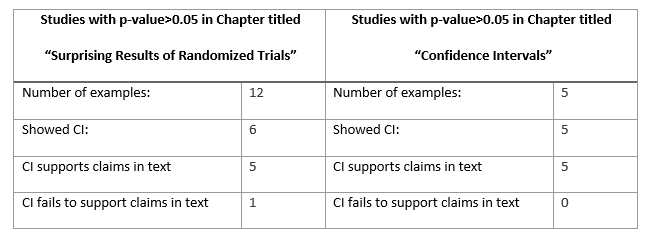
In the chapter titled “Confidence Intervals,” The five examples of study results with p>0.05 all reported CI that correctly supported the claims in the text. In contrast, most of the studies with p>0.05 in the chapter “Surprising Results of Randomized Trials” did not even include a CI. One study with p>0.05 provided CI that contradicted the claims made within the same sentence of text.
Example of RCT results presented without CI

Clinical Question: In cardiac arrest patients, what is the effect of ACD CPR vs standard CPR on mortality?
Reference: https://www.ncbi.nlm.nih.gov/pubmed/8618367
Example of RCT result presented with CI that fail to support claims in text:

Clinical Question: In patients with myocarditis, what is the effect of immunosupportive therapy on mortality?
Reference: https://www.ncbi.nlm.nih.gov/pubmed/7596370/
Consider this from the perspective of the student learner. If most of our examples do not show how to correctly interpret studies with p>0.05, then how is the learner expected to appropriately practice this skill when interpreting actual study results? For that matter, are we as teachers even interpreting these results appropriately? This is not meant as a criticism of any specific book or teaching guide. This is a difficult topic with many nuances and fine distinctions that are challenging to learn and teach. But the limitations within text books serve as a surrogate for limitations seen across the entire breath of how clinicians teach this topic.
There are many other errors that clinicians like myself tend to repeat over and over. I have some theories on why we clinicians tend to gravitate toward certain types of statistical mistakes (related to heuristics biases from day to day practice), but I will have to tackle that in another post.
I would appreciate any feedback, thoughts, or comments on similar educational issues when teaching EBM or critical appraisal to clinicians.
Thanks!