Hello datamethods community,
My colleague, @Pavlos_Msaouel and I have been developing a general framework for quantifying the magnitude of clinical benefit in RCTs, aiming to move beyond some of the limitations of hazard ratios and rigid, threshold-based value frameworks.
Our approach, “BayeScores,” is a Bayesian AFT mixture-cure model. It decomposes efficacy into two interpretable components: the odds of achieving long-term survival (OR for cure) and the survival time-gain among the uncured (Time Ratio, TR). This seems particularly useful for adjuvant or curative-intent studies where non-proportional hazards are common and a “cure” fraction is a key outcome.
A key feature is an identifiability diagnostic (monitoring the posterior correlation of log(OR) and log(TR)). This is coupled with a 3-level prior system (Neutral, Skeptical, Strong Skeptical) on the cure component. This system allows formally encoding clinical belief (e.g., from “cure is plausible” to “very unlikely”) to help regularize the model and stably collapse it to a standard AFT formulation when the data are immature or show no real cure signal.
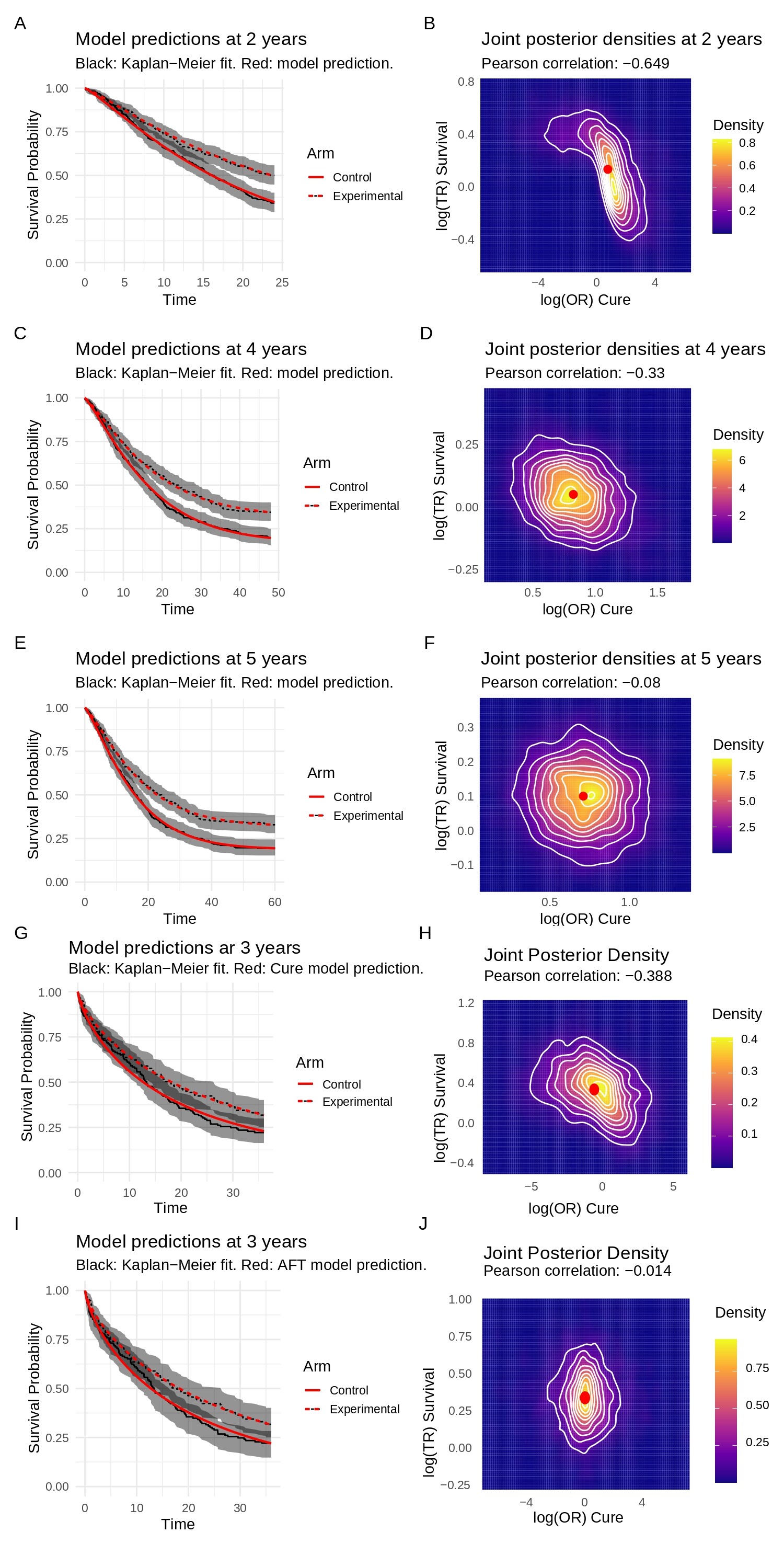
We’ve attached an example figure that shows this in action. Panels A-F visualize how non-identifiability (a strong negative correlation) at 2 years resolves as follow-up increases to 5 years. Panels G-J show how the skeptical prior helps resolve a mis-specified model, collapsing it to a stable AFT-only fit.
Finally, we map these components (OR and TR) to a continuous 0-100 utility score using a concave function to avoid the “cliff effects” of categorical systems and properly encode diminishing returns.
We’ve implemented this in an R package (using Stan) and have put the code and a detailed work example on GitHub: https://github.com/albertocarm/bayescores
We would be extremely grateful for any feedback, critiques, or advice this community might have on the statistical approach, the model specification, or potential pitfalls we may have overlooked.