Hello Everyone,
I am working on a binary classification where I have ~5k records with Label 1 being ~1.5k records and Label 0 being 3.5k records.
When I tried multiple models based on 6,7 and 8 features, I see the below results. Based on the newly added 7th or (7th & 8th) feature, I see improvement only in one of the models (LR scikit shows improvement for 7th feature only whereas Xgboost shows improvement when 7th and 8th features are added).
I came across McNemar's Test but guess that may not be applicable here. I wish to know whether adding this feature really helps. Because I see performance improvement only in one model but not in other models.
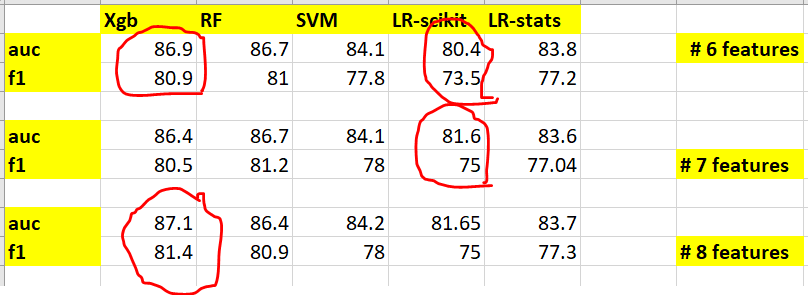
Does this mean that new feature is helping us improve the performance? But it decreases the performance in other models? How should I interpret this?
Please note that I split the data into train and test and did 10 fold CV on train data.
So, how do I know that this newly added features are really helping in improving the model performance? Is there any statistic to find this?
Can help me with this?