Background
Since the beginning of the pandemic, several anecdotal reports of Non-COVID patients presenting to Emergency services (both prehospital and hospital) with more severe disease have been received. The concern is that in an effort to avoid overloading the healthcare system, or due to fear of contracting COVID while at the hospital, patients may be waiting longer to access care for acute medical problems. This may have short-term implications on the successful management of their acute illness (i.e. progression of their disease) that may also impact an already strained healthcare system (i.e. requirement for more intensive therapy and hospitalization).
Objectives
The primary objective of this study is to assess the illness severity among Non-COVID patients.
Secondary objectives include assessing the spectrum of illness of suspected COVID patients presenting to Emergency services over the outbreak.
PICO
Population: All patients presenting to the Emergency Department (ED) directly, or via Emergency Medical Services (EMS) in a single City (Calgary, Alberta, Canada). These patients will be stratified into suspected COVID vs. Non-COVID based on a novel ED code indicating the same. COVID case and mortality statistics available here
Exposure: Period since physical distancing recommendations instituted by Public Health
Comparison: Same period for prior 2 years
Outcome: Critical Illness Prediction Score (CIP)
-
This score uses presenting vital sign measures to quantify a patient’s Illness Severity on a scale from 0-8
-
It has been validated as a general measure of illness severity for predicting hospital mortality among Emergency patients, both trauma medical
Secondary Outcomes:
- Death in ED or per EMS
- This outcome is both clinically relevant and will help overcome one of the limitations of the Critical Illness Prediction score; worse discrimination and calibration for short-term outcomes.
- Emergency Department Disposition
- This will be an ordinal outcome of Death in ED, Admission to Intensive Care, Admission to Hospital, or Discharge Home
Patient Records
EMS and ED records will be used, representing all patients accessing emergency care in the Metropolitan area (including those who are not transported to hospital). These records will be linked using a validated linkage strategy.
Analysis
Visual displays of the mean illness severity score over time (see example from test analysis below), and rates for secondary outcome will be presented.
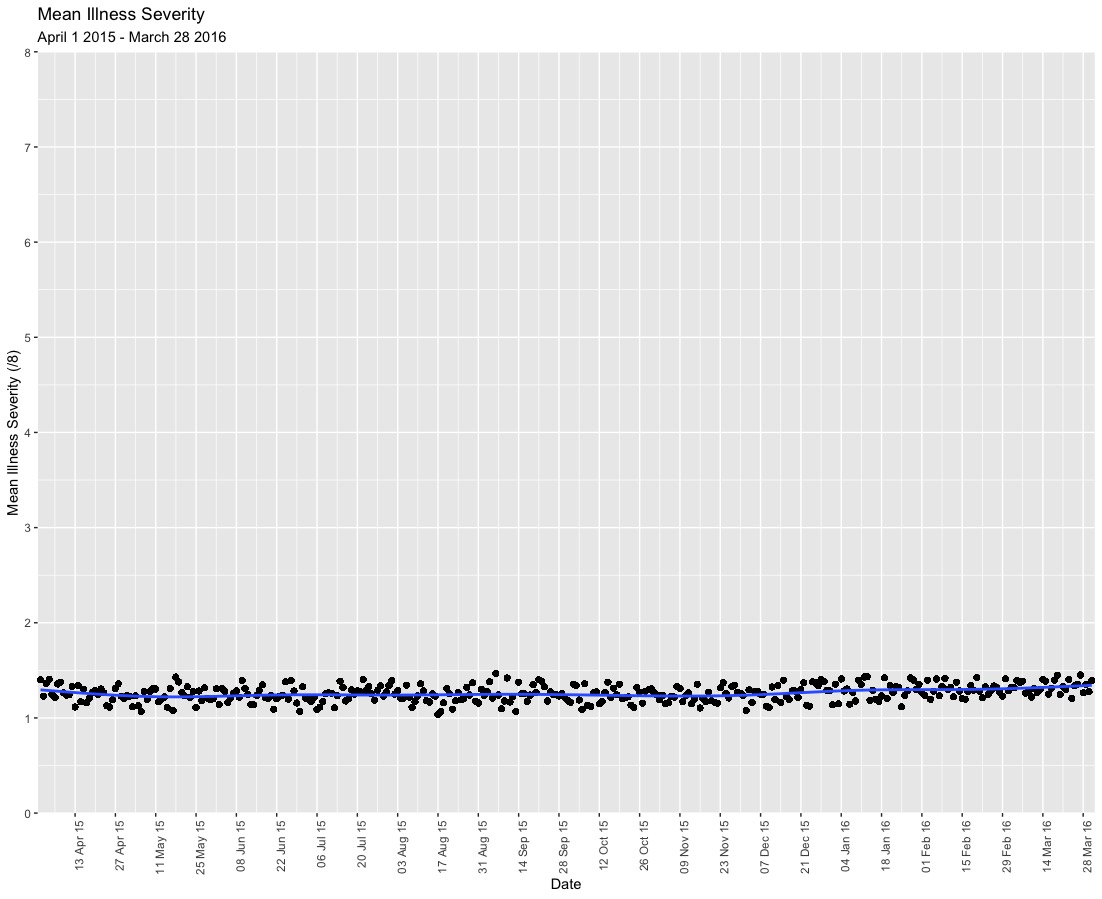
The primary analysis will use a hierarchical Bayesian interrupted time-series to assess change in the ordinal outcome of the illness severity score over time. Patients will be restricted to Non-COVID patients.
Proposed Model
CIP = β°+ β1 * Time (Site) + β2 * COVID (Site,Time) + β3 * Time * COVID
-
CIP is the ordinal outcome score (0-8)
-
β° = the average illness severity at Time = 0
-
β1 = the change in Illness severity. Days will be the unit of time.
-
β2 = change in Illness severity following public health recommendations
-
β3 = any change in illness severity over course of time while recommendations are in place
-
Site = clustering variable for hospital site (There are 4 ED, 1 urgent care centre, and a final cluster for patients not transported by EMS)
-
Time = days over study timeline. Also a random-effect per site.
A cumulative model for the ordinal outcome will be used, which is meant to represent a continuous distribution of illness severity that is informed by the discrete score. Clustering by site will allow us to simultaneously estimate the within-hospital variation and between-hospital variation in the outcomes over time, which may change with the patient illness severity and pandemic response. The use of several years of historical control data will allow for appropriate estimation of baseline rates while accounting for seasonal trends. In preliminary analyses, linearity of time with illness severity was maintained; however, a Bayesian spline function will be use to model non-linearity should any exist. Days will be used as the unit of time to allow for sufficient granularity.
Results will be presented as the probability of a change in illness severity (i.e. Probability β2 > 0). The magnitude of change will be reported as standard deviations on the latent scale of the illness severity measure as this is what the effect estimates represent. Finally we can estimate the change in probability of hospital mortality, associated with any change in illness severity, using coefficients for this association reported previously.
For the secondary outcome of ED mortality we will report the change in probability of mortality , and change in disposition status during the COVID pandemic.
Sensitivity Analyses:
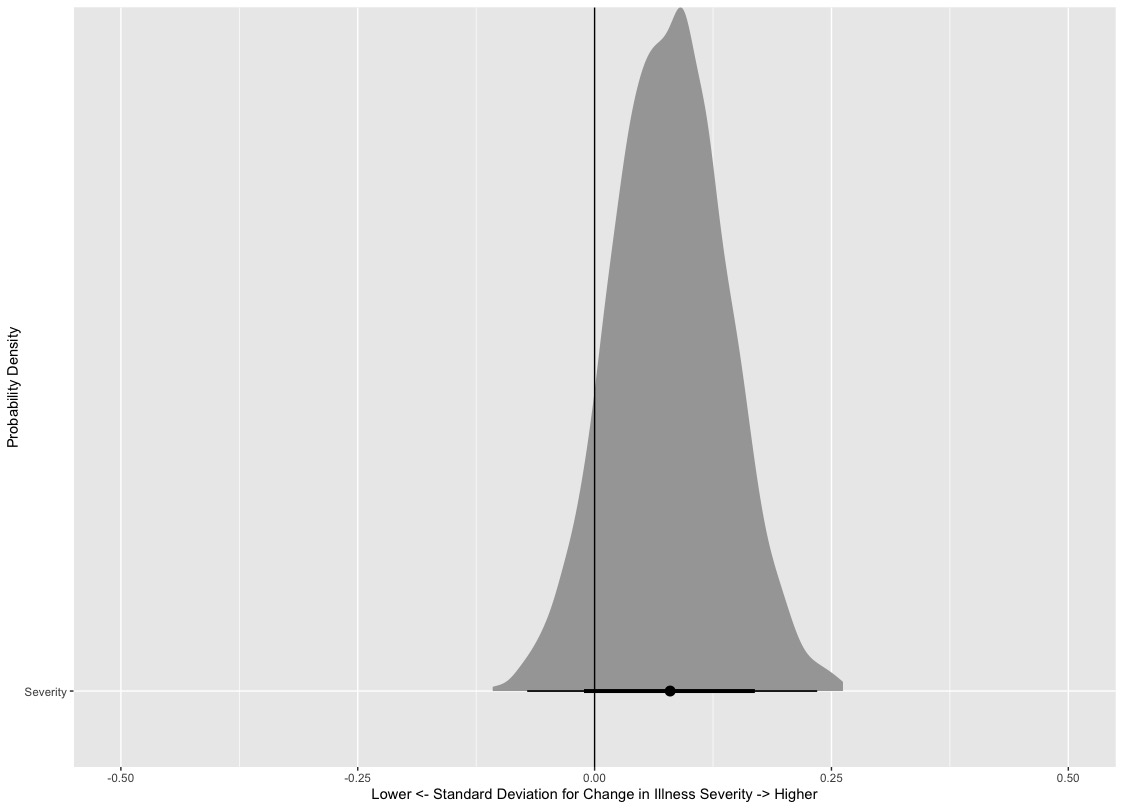
To assess our hypothesis that social pressure may be encouraging patients to delay when they present to Emergency services for acute medical needs, the Illness Severity during the COVID period will be contrasted with Non-COVID events that may present similar (albeit more joyful) social pressure to delay accessing emergency care. These events will include Christmas Eve and Day, New Years Eve and Day, Good Friday and Easter Sunday during the period prior to the COVID-19 Pandemic.
In a test of this Sensitivity Analysis, the probability of Increased Illness Severity on these days compared the the rest of the year was found to be 0.91 (posterior distribution shown below).
This analysis was informed by:
-
Paul-Christian Burkner’s tutorial on Ordinal Regression
-
Solomon Kurz’s blog post on Time-varying covariates in longitudinal analysis