In your excellent paper (Development of a clinical prediction model for an ordinal outcome: the World Health Organization Multicentre Study of Clinical Signs and Etiological Agents of Pneumonia, Sepsis and Meningitis in Young Infants), there is this sentence about the testing of the PO assumption:
To see if the case for this PO model, we computed predicted probabilities of Y = 2 for all infants from the model and compared these with predictions from a binary logistic model derived specifically to predict Pr(Y = 2) (that is, a model with no assumptions connecting different levels of Y)
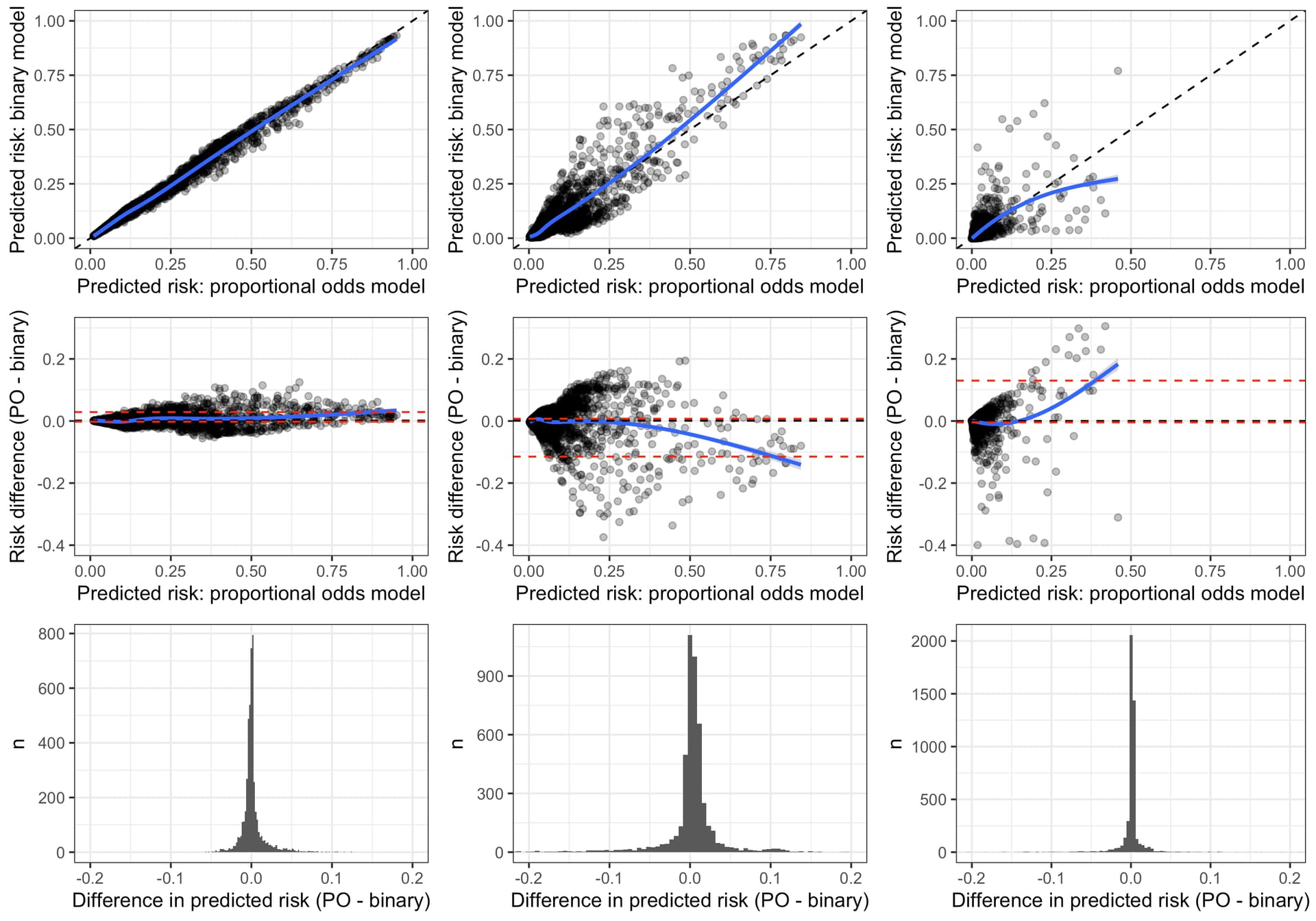
I haven’t seen any papers that specifically address this approach in testing the PO assumption but it seems intuitive. I tried to explore this graphically. Here we see an example in which each column of figures represents on of the three ordinal outcome events of a fully specified proportional odds model.
I wonder if you could comment on the merits and pitfalls of using this approach to judge the PO assumption? It almost seems to me that when one category dominates, such as in the figure above, one can imagine PO model as regularising the smaller outcome events.
Excellent work. I think this is very useful. It is a quicker version of using the partial proportional odds model and looking for non-constant effects over different levels of Y. It is related to https://onlinelibrary.wiley.com/doi/full/10.1002/sim.9281
We do need to go beyond any of the methods to do something akin to estimating root mean squared prediction error in linear models. RMSE gives equal weight to bias and precision, i.e., the variance-bias tradeoff. There are many cases where non-proportional odds is completely OK because allowing all effects to be customized over all levels of Y leads to estimates having variance that is too high.
1 Like
That seems to me what is happening in the examples above and what prompted me to think of the “regularising” analogy.
I think that practical method papers for proportional odds prediction models are sorely needed. You, Steyerberg, Riley, Collins, van Calster, van Smeden, Edlinger, and more have published great work on logistic prediction models, and more recently multinomial logistic models, but anecdotally, I have had a hard time developing a proportional odds model. There is little published guidance about sample size calculations, the optimal way to access the proportional odds assumption (and its importance or lack thereof), and pearls and pitfalls regarding how to assess discrimination and calibration.
These have been covered in RMS for a while including detailed case studies .
2 Likes