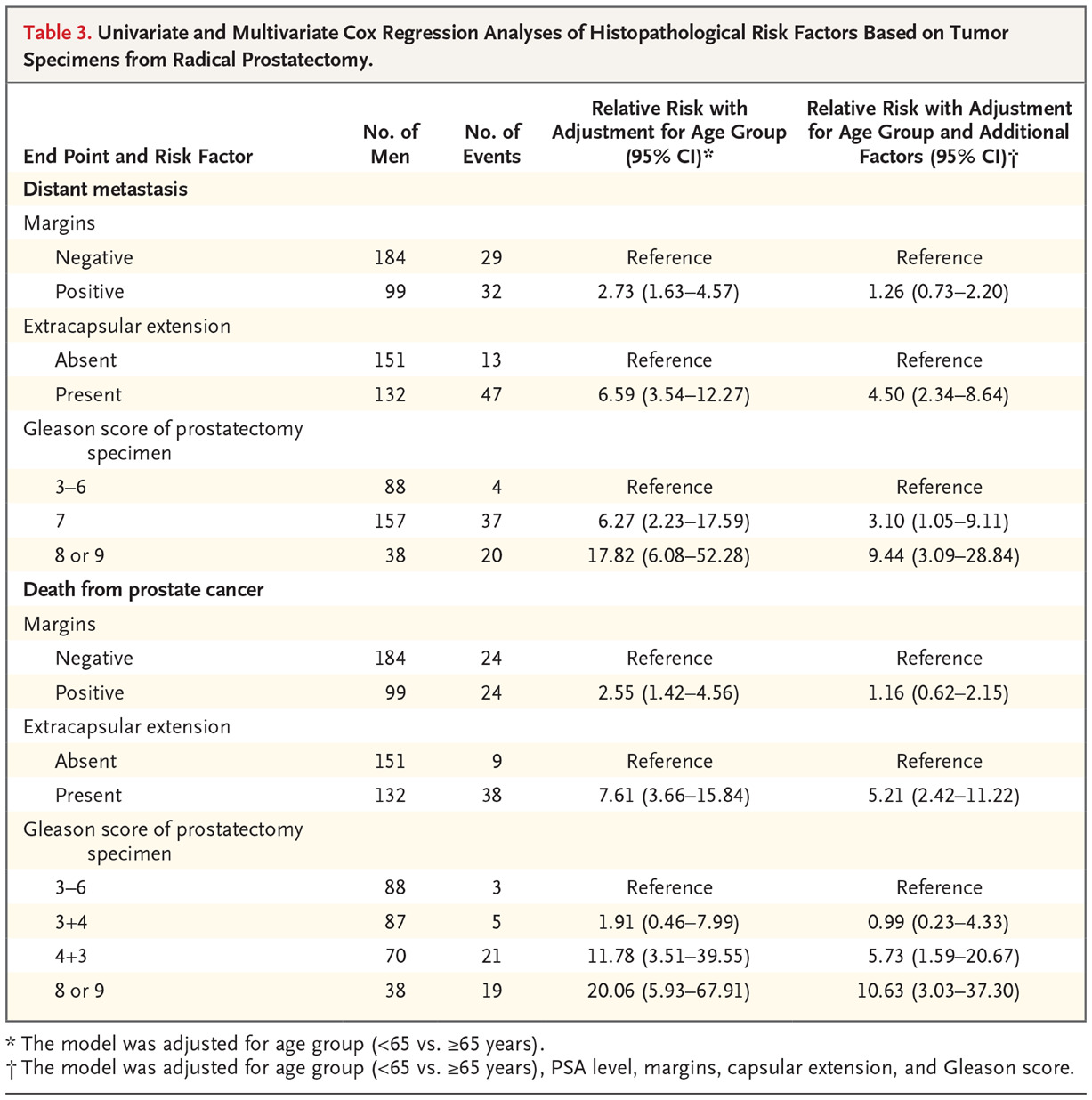
Some prognostic factor studies show results for both univariate and multivariable models. An example of this practice can be found in Bill-Axelson et al where they evaluate prognostic factors for prostate cancer. Table 3 shows results from univariate Cox models and an adjusted model with multiple factors
What is the usefulness of the univariate Cox results? It’s my understanding that univariate results don’t provide meaningful information due to confounding from other prognostic factors. Without analyzing the prognostic factors together in a full, adjusted model, we can’t really make any conclusions from the univariate analysis.
Assuming my understanding is correct, why do studies even include univariate regression results? Is any information learned from viewing the univariate results?
I’m also aware that to truly prove the importance of a new prognostic factor we’d need to show improvements in model performance through methods like the Likelihood Ratio Test, improved R squared, Harrell’s adequacy index, etc - I’m more curious to learn if I’ve been underestimating the importance of univariate results.
I believe that the univariate analyses not only are not helpful. They actually have negative information. You can’t interpret these marginal estimates without knowing the distribution of important covariates that they are not adjusted for. The univariate and multivariable estimates should differ, and the univariate estimates do not help. You’ll also find that the proportional hazards assumption is violated more with unadjusted estimates than with adjusted ones.
Thanks for the answer! Are there any good papers or texts you’d recommend to help convince colleagues that univariate prognostic factor results are uninformative?
I’m sure that such a paper exists, and hope that others can point us to it. One general comment: In randomized studies, even with perfect covariate balance, unadjusted odds and hazard ratios are hurt by the non-collapsibility of effect ratios, making them not estimate the same quantity as conditional (adjusted) ratios. When the outcome is continuous and the study is randomized, unadjusted differences in means at least estimate the same quantity as adjusted differences, so there is slightly more of a reason to show raw means in that case (but still not advised). Adjustment in the normal continuous Y case gains significant precision (narrows confidence intervals) but does not systematically shift the difference in means as happens with odds and hazard ratios.
The MANOVA example was especially helpful. This discussion cites your MANOVA example and has more examples showing why we need multivariable models to account for covariate dependence.
It’s proving more difficult to find papers about univariate analyses that aren’t in a variable selection context.
The answer to this question depends on what is the goal of the study. If the study is aimed to estimate causal effects, then you are right: crude (univariate) estimates are very likely biased (confounded) and, therefore, are not useful for causal inferences. On the other hand, if you have two patients with the same age, selected at random from the population in this study, one of a Gleason score of 4+3 and the other one with a Gleason score of 3-6, you would expect the risk in the one with the highest score to be 12 times higher than the one with the lowest score. This may lead you to further evaluate or treat the patient with the higher score, particularly if you don’t have information on other risk factors. Thus, the crude estimate in not completely uninformative.
Although not really the same problem as we are dealing with here, maybe these papers are of interest to you as well. They discuss another issue of interpreting multiple/all coefficients in one multivariable model (which is mostly an issue when we deal with etiological/causal research):