Consider the hypothetical dataset where a number of study participants have no change over time in a particular outcome, but their probability to drop out of the study is related to the baseline value of the outcome. How can I make sure that this dropout doesn’t bias my mixed model to incorrectly fit an effect of time? Can I include an indicator for whether a subject dropped out as a covariate? Or is that problematic in a way I’m not realizing?
I’m open to more general solutions, in addition to getting an answer to the main question. I have already done some reading to figure this out, and found some possible leads such as inverse probability weighting and doubly robust generalized estimating equations. However, I tried one R package for the latter (wgeesel), and it doesn’t seem to be doing what I expected. It’s also a completely new framework for me - I would prefer to stick with mixed models if possible.
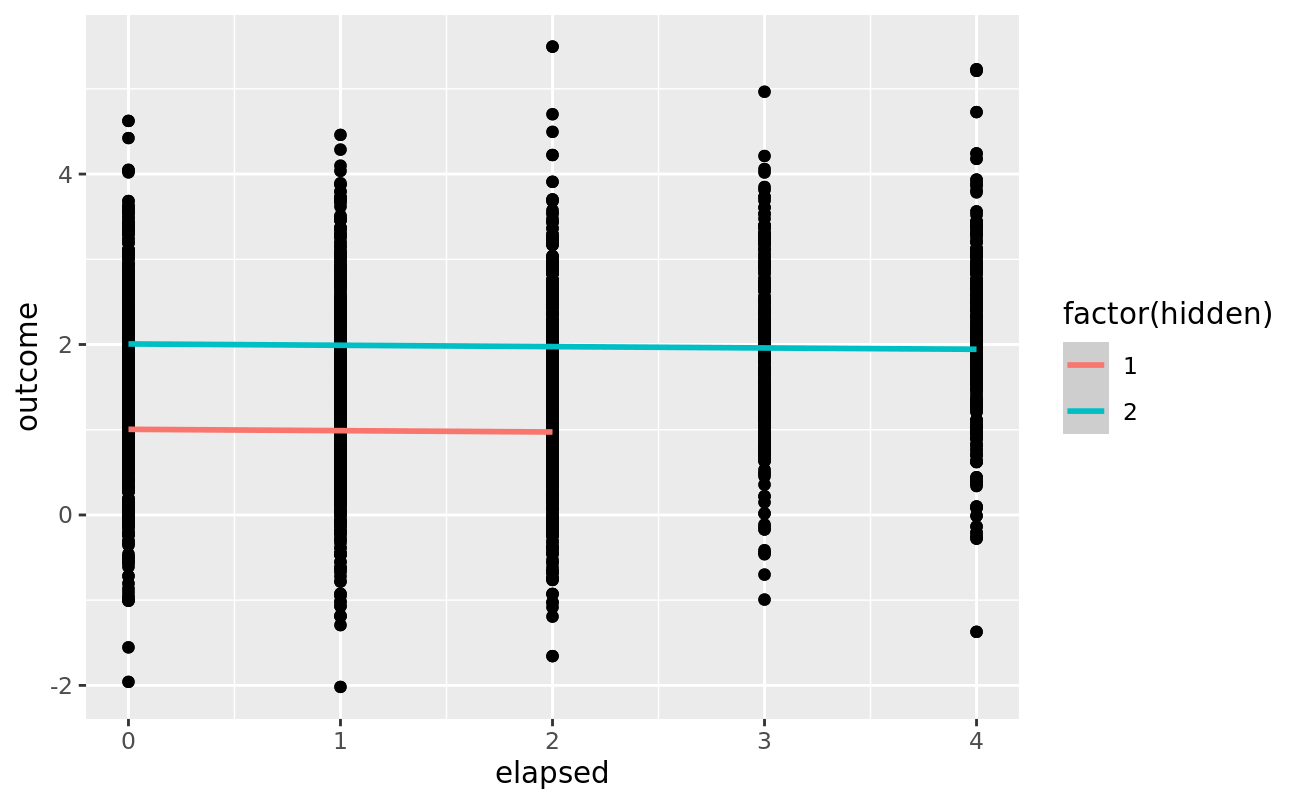
Here is some code & plots that illustrates the issue (omitting model summaries):
library(nlme)
library(tidyverse)
n.participants = 1000
max.fu = 4
set.seed(42)
df = tidyr::crossing(
subjid = 1:n.participants,
elapsed = 0:max.fu
) %>%
dplyr::mutate(
hidden = dplyr::case_when(
subjid < n.participants/2 ~ 1,
subjid >= n.participants/2 ~ 2
),
outcome = hidden + rnorm(n.participants)
) %>%
dplyr::filter(
elapsed <= max.fu*hidden/2
)
df %>%
ggplot(aes(x = elapsed, y = outcome, color = factor(hidden))) +
geom_point() +
geom_smooth(method = "lm", formula = "y ~ x")
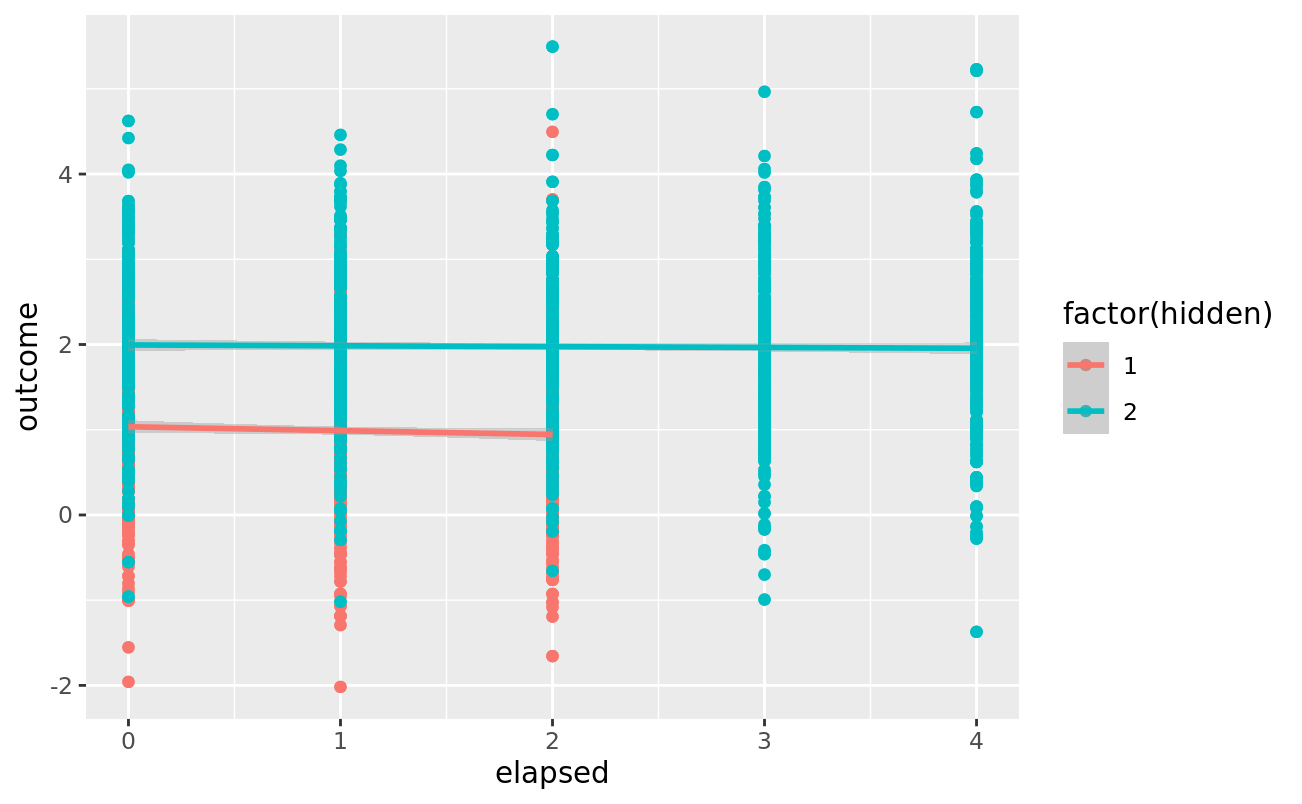
When this is fit without the “hidden” variable which dictates baseline & dropout, I get an effect of time:
model1 = df %>%
nlme::lme(
outcome ~ elapsed,
random = ~1 | subjid,
data = .
)
df$fit1 = predict(model1)
df %>%
ggplot(aes(x = elapsed, y = outcome)) +
geom_point() +
geom_smooth(
aes(y=fit1, color = hidden),
method = "lm", formula = "y ~ x"
)
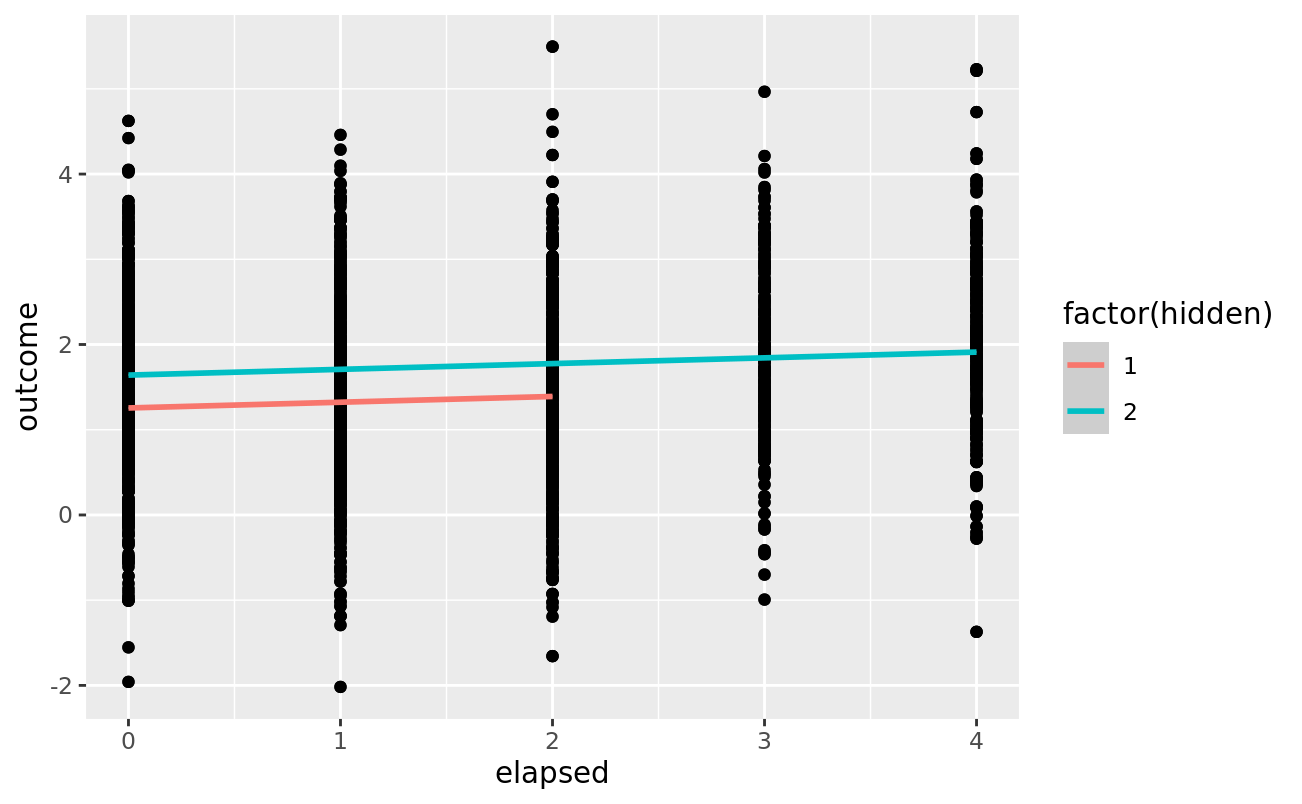
Including the “hidden” covariate, the effect goes away:
model2 = df %>%
nlme::lme(
outcome ~ elapsed + hidden,
random = ~1 | subjid,
data = .
)
df$fit2 = predict(model2)
df %>%
ggplot(aes(x = elapsed, y = outcome)) +
geom_point() +
geom_smooth(
aes(y=fit2, color = factor(hidden)),
method = "lm", formula = "y ~ x"
)