There seems to be an artificial distinction between odds ratios and diagnostic likelihood ratios
In the calculation of post test probability by means of pre test probability and likelihood ratio, we first convert to pretest odds to establish post test odds
Pretest odds * LR = post test odds
Algebra says LR is a ratio of odds.
But it is not discussed this way anywhere. Am I missing something fundamental?
Tony Lachenbruch had a paper years ago that I wish I could find, where he pointed out that the odds ratio is the product of the likelihood ratio + and the likelihood ratio -.
This is because the pre-test odds is not the “baseline” odds!
It is the ‘prior’ odds, i.e. before test information is considered at all. This odds estimate comes from a model that does not have a parameter to represent the test.
The post-test odds is the posterior odds, i.e., after test information is known. It comes from the “posterior” model that has an extra parameter to represent the test.
Said another way, pre-test odds does not mean odds given a negative test. It means odds before you even know the test result.
Well put. The odds ratio is the effect of going from “knowing the test negative” to “knowing it’s positive” whereas the likelihood ratio + is the effect of going from an unknown state to knowing the test is +. “Unknown state” is not always well defined so I stick to logistic regression for the diagnostic problem.
This article discusses what is sometimes called the DOR - diagnostic odds ratio - in more detail.
The DOR reflects the odds of positivity in disease versus the odds of positivity in the non-diseased or, alternatively, the odds of disease in test positives versus the odds of disease in test negatives.
Like all other single indicators of test performance, the DOR is less useful for clinical decision making, or for indicating the informativeness of a single result from a quantitative test.
Glas AS, Lijmer JG, Prins MH, Bonsel GJ, Bossuyt PM.
The diagnostic odds ratio: a single indicator of test performance.
J Clin Epidemiol. 2003 Nov;56(11):1129-35.
doi: 10.1016/s0895-4356(03)00177-x.
(we were not aware of the Lachenbruch letter at the time…)
This means that a logistic regression model routinely provides the best estimate (from the data) for the likelihood ratio for a binary exposure that will take us from the prior non-exposure odds to the expected posterior odds under exposure (assuming the exposure effect is consistent).
Thus, in a clinical trial, where exposure is drug A vs drug B, the OR from logistic regression uses Bayes’ rule to tell us expected change in odds of the outcome when we switch from A to B. Now it becomes very clear why the ratio of risks (B/A) cannot be correct - it violates Bayes’ rule!
I think the logistic regression model provides the OR comparing odds of event in the presence of exposure to odds of event in the absence of exposure (i.e. baseline odds). The presence or absence of exposure is already known.
For the likelihood ratio, the pre-test odds is in the context where the exposure status is not yet known. This is not the same as the baseline (i.e. pre-exposure or absent exposure) odds.
I agree with you - I did not mean that the OR was equivalent to the LRs used in diagnostic testing. The point I was trying to make is that the OR is itself a likelihood ratio connecting two different odds - the ones that you indicated. What logically follows is that posterior risks need to be derived through odds ratios from baseline risk after conversion from the odds scale. What then follows is that a simple ratio of risks (intervention/no-intervention) does not mean much because such a ratio does not have the properties of a likelihood ratio and therefore this alone should have raised the red flag for the RR. The LR+ and LR- used in diagnostic testing are different likelihood ratios from the classical OR and as you have pointed out connect unconditional prior odds to a posterior odds. But all three (LR+, LR- and the OR) are “likelihood ratios”. This has been discussed by Patrick in his paper cited in this thread.
I agree, its incredible that we are still allowing the RR to dominate the research scene after knowing all this!
Lets take an example:
We have two independent tests for a disease - test A and test B and both have a sensitivity = specificity = 60%
The pLR for each test is therefore 1.5 and nLR is 0.66667 and the DOR is 1.5/0.66667 = 2.25
Prevalence of disease in the population is 50% (pre-test odds =1)
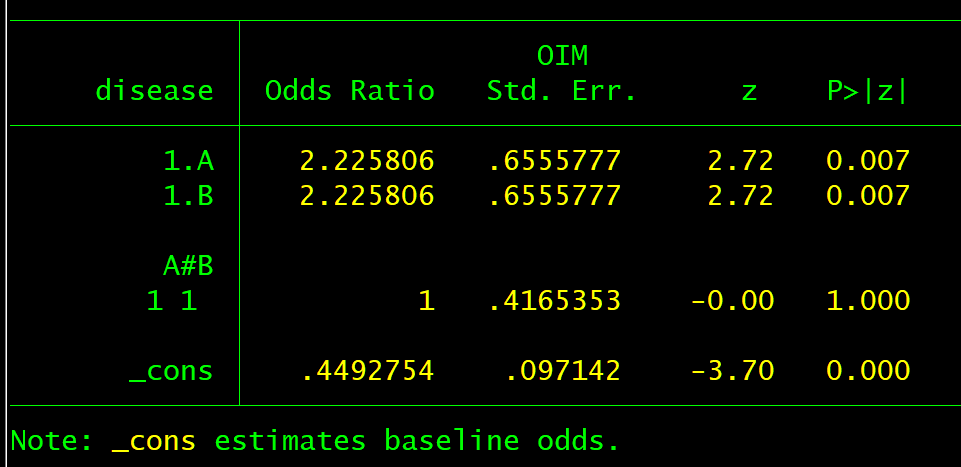
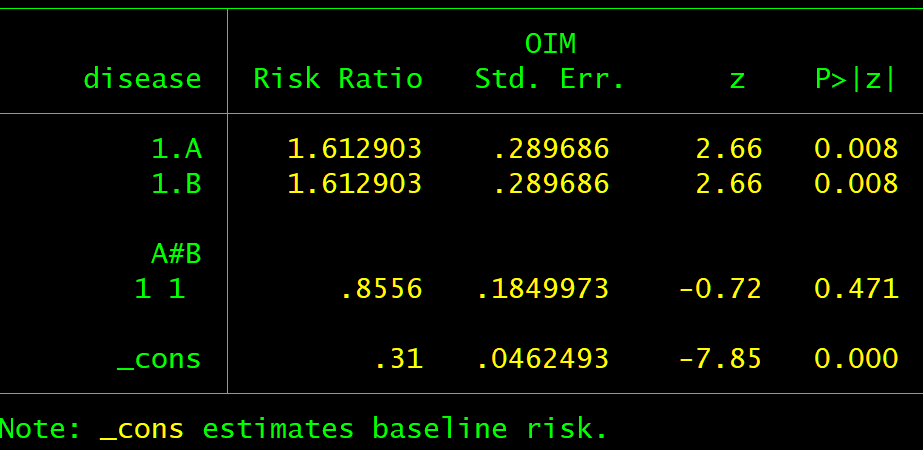
We can now create our regression data-set with an expected risk of 31%(odds 0.45) with both tests negative, with either test positive an expected risk of 50% (odds 1) and with both tests positive an expected risk of 69% (odds 2.25).
With a logit link (OR) we get what we expect under both tests positive:
If we now think about this - no one can deny the fact that the RR misleads in the diagnostic test scenario so why should this be any different with clinical trials? Does this not indicate that the RR is not therefore a parameter of interest in causal inference?
The way I read it, Dr. Lachenbruch states that OR is PPV/(1-PPV)*(NPV/1-NPV), which is the same as (prior+ * LR+) * (prior- LR-), but isn’t the same as LR+*LR-.
You are correct, what the Lachenbruch paper does is to specify that the gold standard will be positive when we are looking at the positive results of the test and thus prior+ = 1, and the gold standard will be negative when we are looking at the negative results of the test and thus prior- = 1. This, I believe, is how LR+*LR- is derived.
Interesting point raised by @Kalil-Manara and what Lachenbruch actually said was this (he did not use logs but I added those for clarity)
lnOR = logit(PPV) + logit(NPV) = logit(Sp) + logit(Se)
We can therefore infer that
OR = LR+ / LR- (rather than LR+ * LR-)
NB We use PPV and NPV based on sample prevalence so they individually will vary across samples but regardless of sample prevalence the Od(PPV) x Od(NPV) will remain somewhat independent of prevalence - I never thought about it this way so this is very interesting
In the context of Lachenbruch’s example, LR+ would be 0.75(1-0.8823) = 6.375 and LR- would be (1-0.75)/0.8823 = 0.2834. LR+/LR- would be 22,49, which is (approximately) the OR stated by professor Lechenbruch.
We have figured this out in this paper.
In summary, the LR is both a ratio of risks and ratio of odds and the diagnostic test community only uses it as a ratio of odds but the clinical trials community uses it as a ratio of risks - the paper above explains the distinction and what this means moving forwards.