I previously discussed critical care summation score of the APACHE class the discussion on CITRIS-ALI. I you missed the discussion I present some of the basics of APACHE class scoring in sections 18-20. I was in training when they were introduced.
Prior to the 80s threshold thinking was widely discouraged as simplistic. Paulker embellished this approach with some goid concepts but the use of thresholds was too seductive. The growth of threshokd science (the use of guessed thresholds as gold standards in RCT emerged despite the fact that Paulker never advocate this expansive use of arbitrary thresholds.
Tiday I was in a fiscussion with a mathematician and I asked her why statiticians would think they could apply states to render an output statistically defining highly variable sets of guessed threshold combinations.
She said that mathematicians use tools which have been defined by proofs. So they may not think to explore the tool such as a SOFA score because they assume that it has been mathematically validated, that it is a sound tool mathematically.
So the introduction of the use of something as fluidic as SOFA as a primary endpoint in medical research pivotal to the survival of patients should be a wake up call.
The lesson is that it is not enough to do the math in the middle and leave the math at the two ends (the proximal gold standard and distal primary output) to the Pi.
If the gold standard or primary endpoint is presented as a function investigate the origin, validity reproducibility. and graphical behavior of the perceived function. If thresholds are used what was their origin and extent of rigor defining their behavior and reproducibility in the condition under test.
Biologic systems are often so complex that in the 20th century clinicians resorted to gross and often hierarchal averaging to get a signal. They were a little like a hiker with a cell phone wandering up the hill to get a signal. However the math derived from such wanderings must be considered with the signal and part of the equations defining probabilities not separate from them.
In the final analysis, If you haven’t studied these 20th century sores of the APACHE class then its probably best to start there first because yhose scores are not simply in the clinical domain (like an adverse occurance such as desth or a sibjective vlinical event such as a stroke). No these scores are in a continuum with the math which defines the clinical probability of efficacy which the PI is seeking to learn.
I may have sounded condescending here. Thats not the intent.
I’m in awe of the stat brain power here. Appreciate the honor of being able to comment. However, our research team operates exdogma, in fact we hunt dogma.
My old mentor at WUStl was a member of the anyidogmatic society so I guve him credit for much of our success as dogma hunters.
Furthermore, we have very advanced dogma hunting software technology for the study of medical time series matrices.
We have studied guessed threshold sets since the 90s in relation to the actual matrices in both the time and frequency domain, and are in a unique position to provide insight.
The comments were a shot across the bow to say, “hold on”, the math of these thresholds and scores have a complex history and derivation so no matter if you are a stat genius or not, dont talk about these scores like you know what they are if you have not studied them.
Second, I’m always hopeful to learn from another dogma hunter with more stat knowledge than I who has also investigated these scores from a math perspective.
Finally I am trying to convince at least one nascent statitician to rise to the need and help dogma trapped clinicians (who have been indoctrinated since the 80s to use these threshold sets as gold standards). Help them see that the guessed threshold summation math does not work to render reasonable reproducibility as gold standards or primary endpoints in RCT.
Your posts above and in the CITRIS-ALI and Phenotyping Clinical Syndromes threads are interesting. You seem to highlight the fact that failure to address clinical heterogeneity among patients enrolled in sepsis trials might be a major contributor to the reproducibility crisis in this field. Also, I think I’m hearing that there are important statistical issues with the clinical severity scores used in ICU trials. These scores seem to require dichotomization of many clinical parameters, a process that results information loss, leading to a requirement for more trial subjects to achieve adequate power (?) So I think you’re saying that efforts to amplify potential signals of benefit in critical care trials need to be ramped up. Unless there is a concerted effort to identify more homogenous groups of sepsis patients and to overcome dichotomization issues inherent in the methods used to assess clinical severity, reproducibility in ICU trials will remain elusive (particularly given the small size of most ICU trials). Hope I didn’t mangle this…
Rather than using the umbrella term “sepsis” to decide who gets enrolled in an ICU trial, are there some trials that only enrol patients who all have a similar etiology for their sepsis (e.g., all patients admitted through the ER with a “urosepsis” diagnosis, or all patients admitted with sepsis from pneumonia)? If not, why not? Does it make sense to lump patients with urosepsis together with patients with pneumococcal sepsis for the purpose of assessing the efficacy of a new ICU intervention? Is it realistic to expect both types of patient to derive benefit from the same intervention(s)?
Perhaps more pressing than the heterogeneity proble, which has always been ubiquitous in critical care as a function of the environment, is the use of consensus guessed, threshold set which induces a range of counterinstances (which clinicians do not understand and instead think are just anomalies). This is why they thought they could use SOFA as if it was a single function.
They really dont understand why this doesnt work. They are not teacable because they have confidence that their dogma must be valid having learned it from the best clinical minds who were themselves indoctrinated by the well meaning, original guessors.
An pure stat or math article which generated simuations showing the variability by assigning mortality to each of the 50+ potential combinations of a single score and how this effects probability as the score increases or decreases as a function of different combinations of breaches would be a landmark and change the thinking of the criticare discipline which has been going on for over 30yrs. The originators of SOFA mention these issues in the link below but those limitations have been forgotten which provides a good first direction for the article.
I am asking for someones help. We need it acutely given that they, in a new twist deeper into the dogma (as shown in Citrus-ALI) are now using the threshold set based summation scores on the distal end as well as the proximal end.
Just a note. To show you how pressing this is, to my knowledge, not a single positive sepsis or septic shock RCT has been reproducible for 30 yrs. Not one! (Please advise if you know one).
It is no coincidence that all these RCT used guessed, nonspecific (multi breach) threshold sets as gold standards.
One more comment because I’m so excited that someone is listening.
Now you are going to read nearly endless ruminations about why Citrus-ALI did not show a linkage between SOFA and mortality when SOFA was “validated” as a mortality score (notice I didnt say “a mortality function” although that’s what they think SOFA is).
They will suggest inadequate N, survivorship bias, heterogeneity, etc. Its the same everytime. Each one if these may be quite valid. However here’s the dogma hunter’s clue, so read closely because this is a VERY important clue which you can use yourself to find dogma.
No one ever questions the use of guessed summation threshold sets as a potential limitation of the trial in the article descibing the RCT. Now they might have in CITRUS -ALI and I missed it. If they did it would be the first time I ever saw it.
Of course it would be natural, even obligatory, to mention and discuss that specific limitation of the study (RCT). However…they dont. Why? This, for the dogma hunter, means that the authors (trialists) considered this portion of the study to be unassailable truth, like the formula for torque. You dont question that, its known.
Find things like that in trials and you have found gold.
Now that you understand, you can watch the ruminations. Actually it’s kind of a hoot, if you are a dogma hunter.
I’m a family physician with remote and limited statistical training but a keen interest in critical appraisal. So apologies in advance that I’m not going to be the person who solves any of these longstanding problems in critical care research. But maybe my blundering attempt to restate in layman’s terms what you seem to be saying could be useful to someone.
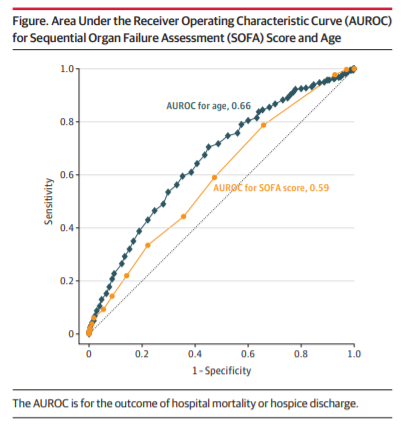
I see that the “SOFA score” mentioned in the CITRIS-ALI trial is calculated by assigning a “score” (maximum 4 points) to indicate the degree of dysfunction of each of 6 “organ systems” (e.g., lung, liver brain, kidney…)- the higher the score for each organ system, the worse the function of that system. So the maximum SOFA score for any patient at any time would be 24 points (max 4 points from each of 6 organ systems).
I think what I’m hearing you say is that if critical care trials are going to use clinical prediction scores like SOFA as primary endpoints going forward, then it’s important to characterize their prognostic value in a more granular way than has been done to date.
Specifically, I think you might be saying that there could be a fair bit of variability in prognosis for two patients with identical total SOFA scores and that studies are urgently needed to find out whether this is the case (?) . For example, even though a group of patients with a SOFA score of 16 may be more likely to fare worse (e.g, with regard to ICU mortality) than a group of patients with a SOFA score of 8, maybe there’s actually a fair bit of variability in prognosis when we compare two patients with SOFA scores of 16. Maybe a patient who gets his 16 SOFA points as follows: 4 points for the LUNG category+4 for coagulation +4 for cardiovascular +4 for kidney will tend to do worse than a patient who gets his 20 SOFA points from a different constellation of subset scores (e.g, 4 LIVER (rather than LUNG) +4 coagulation +4 cardiovascular +4 brain), though on average, patients with scores of 16 would be expected to do worse than patients with SOFA scores of 8.
When we look at signal mortality there are some we call “mortal signals” because they have a high first delta mortality/delta signal others are not. The differences ard dramatic with and with narrow vonfidence intervals.
One look at these curves and its clear.
Signals with high delta mort include for example bilirubin as liver dysfunction/injury is highly mortal, esp in sepsis.
Some are volatile signals such as the lung signal which can be high one hour and much leaa another wheres others like the liver and kidney signals are much less volatile this creats a potentially unstabe time series of SOFA over the hospital course as one set of organs (eg platelets, PaO2) rapidly improve while anothers set (eg bilirubin, creatinine) more slowly worsen. It may even appear, by SOFA that such a mortal case is improving.
So ThresholScience with an APACHE class score like SOFA gets ever more complicated.
Heres an article where they conclude that Procalcitonin guided therapy would not be useful if SOFA score is greater than 8 and discuss a metanalysis using a range of cutoffs of the SOFA score 0-6, 7-10, 10-24 to determine the “effectness” of procalcitonin"
Here you can see layers of thresholds first in SOFA and then in the sum (SOFA score) itself to determine the PPV of a threshold of a marker of inflammation (procalcitonin).
Now you see why I say “#ThresholdScience is like turtles” … its thresholds all the way way down.
This situation is getting worse. SOFA cuttoffs are becoming ubiquitous parts of critical care statistics used with p values to determine efficacy of a drug (as in CITRUS-ALI) and utility to other thresholds (as with procalcitonin), The potential list is endless. There is even a metanalysis looking at “tertile like” distributions of SOFA which are not even valid tertiles. The idea of SOFA tertiles as a metric for the application of complex statistical analysis makes my skin crawl.
This is something that has to be stopped because it is a rapidly expanding methodology of crit care RCT and only the statiticians can stop this because (like many scientific groups) the clinicians trust the math of their predecessors and feel no reason to question such “gold standard” metrics.
So this 2017 paper discusses some of these issues:
The stats go over my head, but I’m wondering why one of the conclusions in the abstract is that “Treatment effects on Delta SOFA appear to be reliably and consistently associated with mortality in RCTs” when the results say that delta SOFA explained only “32% of the overall mortality effect.” Is this a good result? Does it actually support using delta SOFA as a trial endpoint going forward?
Thank you for providing this. Hats off to these authors for trying to find the best derivative of SOFA.
This work shows agonized, almost tortured efforts to find a derivative of SOFA which is a valid surrogate. Read the SIX caveats to see the extent to which the authors seek to bail out this tortured but “gold” threshold summation score. This is the act of treating counterinstances as anomalies which I mentioned (after Dr. Kuhn).
Note within the study they treat SOFA as a single function. The authors fail to critically examine SOFAs original derivation and simply cite the source of SOFA as prestigious. In essence, they anoint SOFA.
This is typical of all trials that use SOFA.
This is the “known formula for torque” assumption. The sentinal event the dogma hunter is looking for in any trial to detect dogma.
All of these derivatives are rumination analogs. In other words the lesson is that researchers simply have to choose the right SOFA derivative and be very careful in implementation.
I hope a stat expert will comment after reading this paper.
“…It is unclear how the SOFA score changes in response to a treatment that changes the mortality risk within a specific timeframe. Second, the consistency of the SOFA score to reflect changes in underlying mortality risk has not been quantified. Even if true mortality-modifying treatments effects are reflected in the SOFA score on average, the validity of the SOFA score as an endpoint is doubtful if this relationship is inconsistent. Third, it is unclear which derivative of the SOFA score is the most appropriate endpoint.”
Even if the authors did not dissect the dogma, this is a truely courageous study. Of course it does not resolve these issues but it does reveal an interesting feature. The possibilites for RCT using these scores and for ruminations and statistical analysis are endless as are the stat opportunities to contrast and compare as in this study. If publication rather than discovery and reproducibility is the primary goal, SOFA is perfect.
So I was once a threshold scientist. I would have thought SOFA was a valid endpoint. You might ask why no expert pugnacious ecperts still holding that view make comments or criticize my analysis with the usual vigor. The answer is that they know what I saying is true.
The problem is the young. still beleiving the dogma, mistake the silence of the experts as an indication that the arguments are without merit and do not rise to the level warrenting expert discussion or dissent. This maintains the indoctrination, when in fact, the thought leaders just dont know what to say.
For this reason it is important to be vocal about this. We dont want the young to make the same mistakes we did. The public expect us to be couragous not comfortable, in the interest of their health, and the health of their precious little ones.
To the extent we can make their recoveries more likely, the science of their health is our responsibility There is no back up.
Prediction models with scores (Apache, Sofa) were created to predict patient decline and eventual mortality. They were calibrated/valudated on mostly observational data, but like many other prediction models they may fail in actual use due to over-fitting and differences in patient characteristics. More worryingly, these prediction models also suffer from measurement error in their predictor variables, most commonly in measuring time to event. This leads to even more calibration issues, and attempts to validate or re-calibrate on new data sets will have mixed results unless the underlying measurement error in the predictors is addressed.
Also the number of potential combinations of thresholds renders many permutations which have different mortality correlations but are hidden by generating a final unifying sum of different things which is perceive to be, and treated as, a single mortality function…