I wish to model blood metals concentration as an outcome, however the complication is that it was measured with a limit of detection - i.e. the lab equipment used is unable to determine concentrations below a certain threshold. So below that value all readings are the same (i.e. 0, or in my case the data was entered as the l.o.d. threshold value), and above the threshold that data is continuous. I’ve read that hurdle models could be used to model this kind of data structure, and as I plan to work in Stan via the brms R package, there are several hurdle models available: hurdle_poisson, hurdle_negbinomial, hurdle_gamma, hurdle_lognormal. The first two are obviously for count data so not appropriate to my data, but I understand that the gamma or lognormal options could be used for continuous data. However I don’t really know which one of those is appropriate in what circumstances or how to choose between them, and I was hoping some of the kind datamethods experts could advise ? Or do others have experience of different approaches to modelling such data ?
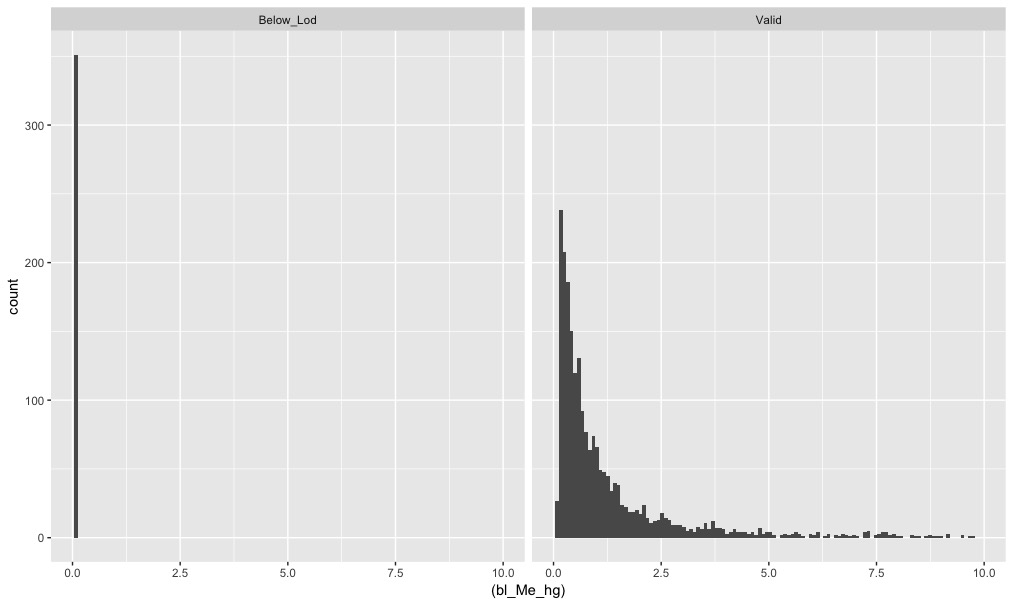
To illustrate the issue - this plot shows a histogram of methyl mercury blood concentration from NHANES data, facetted by whether the reading was below the l.o.d. or a valid reading. About 13% don’t meet the threshold:
This seems to be an ideal case for an ordinal semiparametric regression model (e.g., proportional odds or proportional hazard models). There will be many ties at the lower detection limit, but this presents no challenge to these models. Note that with ordinal models no binning of Y is required.
I don’t think a hurdle model is appropriate. If you are interested in estimating means in various groups, those censored values are going to be an issue – the more censored values the group has the more inaccurate the estimate of the mean.
One useful assumption is that there are no true zeros. This is in line with the now overwhelming evidence of contamination worldwide. Whats more likely is that the distribution that you can see is continued into the censored zone. So censored or interval regression would be more in line with the accumulated evidence. I’m agnostic about using Poisson models in non-count data, by the way. It is a more generally useful tool than most people thing, so long as you can model the inevitable overdispersion. Silva JMCS, Tenreyro S. The Log of Gravity. The Review of Economics and Statistics. 2006 Nov;88(4):641–58. And this blog post from Bill Gould
Yes that is my working assumption for same reasons - practically nobody is completely unexposed. But my understanding was that hurdle was useful for this situation - i.e. no true zeroes ? Have I got that wrong? Groups are not an issue, I’m regressing versus other continuous variables, no categoricals involved.
Concerning what is estimable without extrapolation assumptions (e.g., without assuming normality or log-normality), ordinal models allow you to estimate everything other than the mean without making distributional shape assumptions. You can estimate quantiles (as long as they don’t out into the left tail) and very easily estimate exceedance probabilities, e.g. P(Y > c | X) as long as c >= lower detection limit.
I think that the quantile approach has a lot to commend it.
But another concern hit me almost instantly, which was that means or medians are not relevant here. Health and safety is the concern, and that should dictate the statistics we’re interested in.
What are the biological cutpoints for some/too much (dangerous)/far too much (toxic)? These are the categories of interest and the factors that affect their frequency are the ones to be going after in your analysis.
If you don’t have such categories, maybe the analysis should be using health states to define unacceptable and totally unacceptable levels.
Ronan I’m not seeing how the ultimate goal really changes the choice of the statistical model. To me the statistical model should
use the data efficiently
have a good chance of fitting the data patterns
lend itself to interpretations and clinical restatements
On the last point, you point seems to translate to the choice of c in using a cumulative probability ordinal model to estimate Prob(Y > c | X), or in the choice of quantiles to compute from the model estimates.
From clinical research, acronyms worth googling are LLOQ and BLQ for data that is Below the Limit of Quantification (LLOQ=Lower Limit of Quantification). (An upper limit is also possible, ULOQ.)
And the SAS, R, GenStat and NONMEM code for a MLE method M3 is in a paper that should be useful:
Statist. Med. 2012, 31 4280–4295
The ghosts of departed quantities: approaches to dealing with observations below the limit of quantitation
Stephen Senn, Nick Holford and Hans Hockey
Hi @f2harrell. Yes I agree with you that this would be the best solution if this were all I was doing. However, I intend to use this as a sub-model within a larger stan model, and so losing the natural scale of the outcome variable would be a problem. I didn’t go into the extra details because I was still thinking out the larger problem and didnt’ want other elements of the problem to distract, and because I was finding it hard to find literature on hurdle models in this application. However in the mean time, I found some interesting papers on it:
I hear ya. Note that Stan works quite well with semiparametric models. We mainly use rstanarm for those as the intercept priors used by the brms package have been problematic for us.
Ah ok. I did some tests of ordinal models in Stan and was having problems all right. I’m no really fmailiar with rstanarm but perhaps I will take a look. Thanks Frank.
@f2harrell your semi-parametric ordinal solution seems to come up a lot here and I (perhaps naively) assumed the only pre-canned approaches available were frequentist based. Can you give an example of the rstanarm code you would use for this type of analysis?
I’m working with our Vanderbilt Biostatistics PhD candidate Nathan James who has done a lot of work with the R brms and rstanarm approaches and has tested whether it’s feasible (computation-time-wise) to have hundreds of intercepts (yes, it mainly is) so that you can handle continuous Y with these models. If he has time perhaps he can give some software pointers here. Note that Richard McElreath covers Bayesian ordinal models in his terrific book Statistical Rethinking.
what if less than 5% of the observations are below LLOD.LLOQ, does it make sense to treat the data as a truncated normal, assuming the 95% of the truncated part approximately looks like a normal distribution ? could we just trim(exclude) the 5% observations below LLOD and treat the rest as a regular normal distribution ?