I am trying to find the most appropriate modeling strategy for my case. The dependent variable is a ordinal one, which is the result of summing up the responses of some individuals to a series of questions. Each question can be answered with “Never”, “Sometimes”, “Often”, etc… This ordinal variable can then take discrete values between 0 and 14, with 0 being the case of a subject who answered “Never” to each question.
In my field of research, neurodevelopment, it is common practice to take the square root of the variable so that linear regression can be used. This is in theory correct since it is assumed that these scores have a underlying continuous distribution. I believe a ordinal model would be a better fit since, when taking the square root, the distance between 0 and 1 remains the same, but not bewteen say 0 and 3.
What is probematic about a ordinal model, is that for very high values of this variable I have very few subjects:
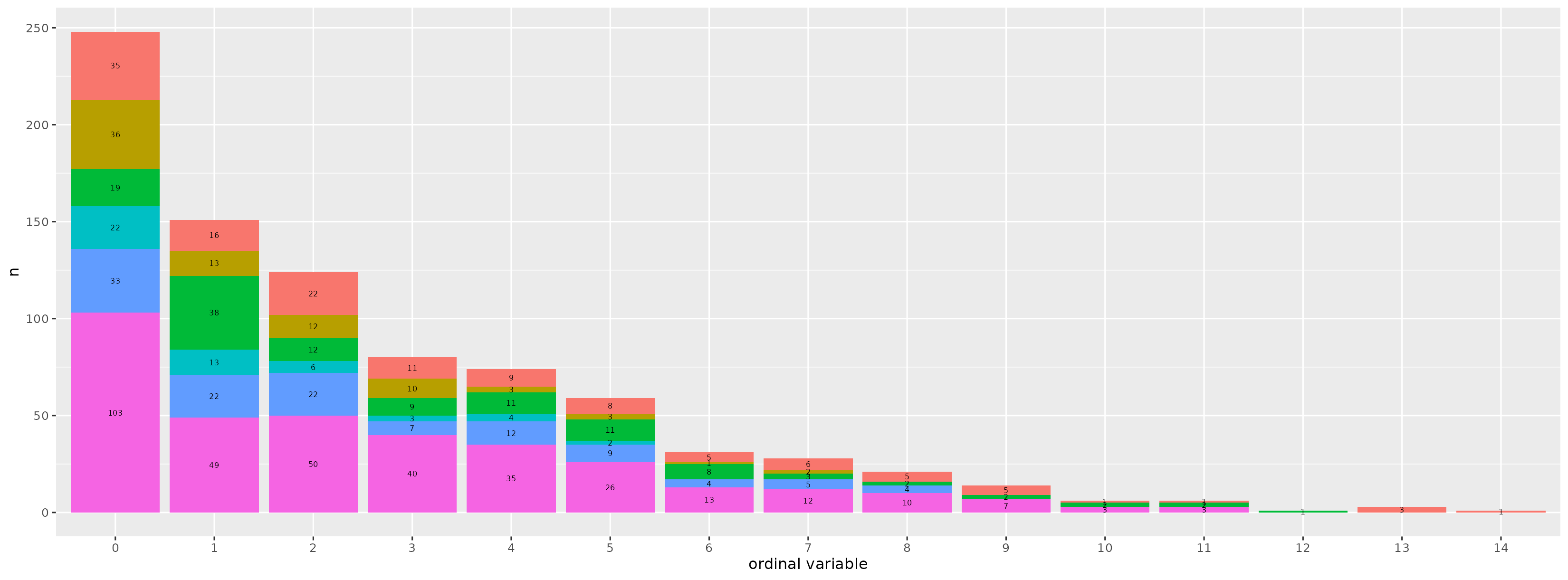
In this plot you have the values of the raw variable on the x axis, and the frequencies on the y axis. Each bar is color-coded since the subjects of my sample belong to different sites. As you can see, for values of Y greater than say 8, few data points are available.
What options do I have? Some ideas:
- Lumping the more extreme values together (e.g., if
Y>6thenY=6). But this reminds me a little of the selection of arbitrary cut offs to make continuous variables binary. - Leave everything as is and fit a ordinal models.
- Take the square root and forget about the impossibility to mantain the same distance between values.