
Kiani, A., Uyumazturk, B., Rajpurkar, P. et al. Impact of a deep learning assistant on the histopathologic classification of liver cancer. npj Digit. Med. 3 , 23 (2020). https://doi.org/10.1038/s41746-020-0232-8
Hi all,
I would like to understand how the above study had performed it’s mixed effects model. The outcome Y, is a diagnostic accuracy, which is binary (1/0). Then they have 3 fixed effects: (1) Assistance (Yes/No), (2) Tumor Grade (G1/G2/G3/G4) and (3) Pathologist Experience (GI subspecialty
pathologists/non-GI subspecialty pathologists/pathology trainees/pathologists, not otherwise
classified). They have 2 random effects: (1) Pathologists (x11) and (2) Slides (x80).
All 11 pathologists assess all the 80 slides on 2 occasions (1 with assistance and another without assistance).
So, I would think that they have used the following formula:
Diagnostic Accuracy = Assistance + Tumor Grade + Pathologist Experience + (1|Pathologist) + (1|Slides)
And this is design that I have thought of is:
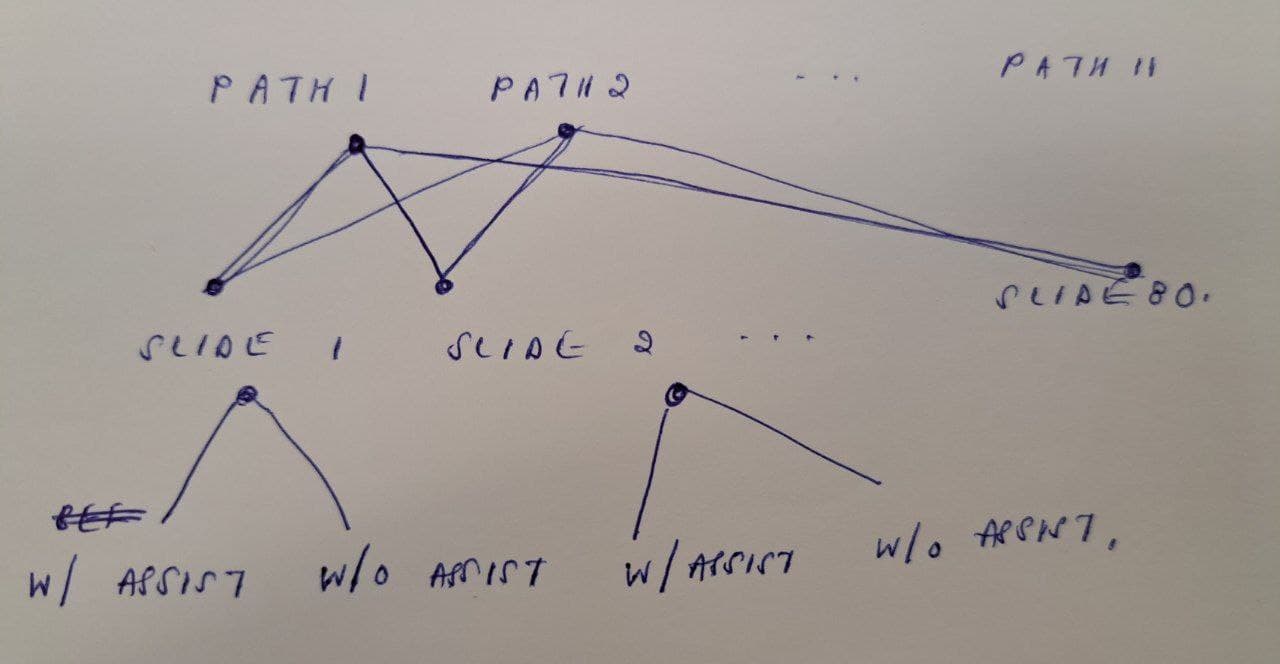
Where Pathologist and Slides are crossed random effects. Given this, should “Assistance” have been nested within each slide (i.e. replace with the term (1|Slide/Assistance)) or crossed (i.e. add a new term (1|Assistance))? Or should it just be considered a fixed effects?
Thanks!