We are developing a prognostic model for cognitive development in very preterm infants using advanced MRI scans. To achieve this, we used three types of MRI information: functional connectivity (FC), structural connectivity (SC), and morphometry. Additionally, we incorporated clinical data to enrich the model. This resulted in high-dimensional data with more than 1,000 features for each subject, making model development challenging. Therefore, we needed to perform data dimension reduction.
We selected non-negative matrix factorization (NMF) for feature extraction because it facilitates the identification of statistically redundant subgraphs, allowing for overlapping and flexible co-occurrence of components. NMF’s non-negative constraints also ease the interpretability of the subgraphs as additive, positively contributing elements. We applied NMF separately to the SC and FC graph measures. Prior to modeling with NMF, the morphometry data (which included some variables with negative values) were logarithmically transformed and subsequently subjected to Min-Max scaling to meet the algorithmic assumptions of NMF.
After applying NMF to the SC, FC, and morphometry data separately, the dimensions were reduced to 31 for SC variables, 29 for FC variables, and 26 for morphometry variables. We then added 6 clinical biomarkers, 1 cMRI injury, and age at scan (a total of 94 variables).
To develop and evaluate the models, we used bootstrap optimism correction validation and kernel-based SVM. For this model, we used the ANOVA kernel. The bootstrap optimism correction evaluation involved the following steps:
1. Develop the model M1 using whole data
2. Evaluate the performance of M1 using whole data and ascertain the apparent performance (AppPerf).
3. Generate a bootstrapped dataset with replacement
4. Develop model M2 using bootstrapped dataset (applying the same modeling and predictor selection methods, as in step 1).
5. Evaluate M2 using bootstrapped dataset and determine the bootstrap performance (BootPerf).
6. Evaluate M2 using whole data and determine the test performance (TestPerf).
7. Calculate the optimism (Op) as the difference between the bootstrap performance and test performance: ( Op=BootPerf-TestPerf) .
8. Repeat Steps 3 through 7 for nboot times (n=500 ).
Average the estimates of optimism in step 8 and subtract the value from the apparent performance (step 1) to calculate the optimism-corrected performance estimate for all relevant prognostic test properties.
After evaluating the model, we plotted the calibration plot as below, and figured it out, the calibration of our cognitive model is suboptimal while the performance values were high.
If we recalibrated this model, would a new cohort be required to internally validate the model? If so, it may not be worth recalibration this model unless there was a way to do so without losing the ability to internally validate the model. If we recalibrate the model after the apparent performance step but before test performance (i.e., during the bootstrap performance), would the model remain internally valid?
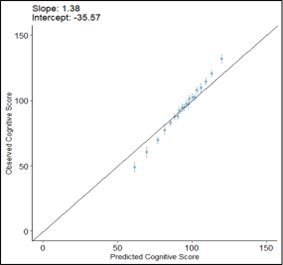
Figure 1. Calibration plot of prognostic model for cognitive development