Hi all,
I would very much appreciate your thoughts on an idea before diving into the technical details and potentially getting stuck in tunnel vision. The idea is based on several points, so I’ll set the context first:
-
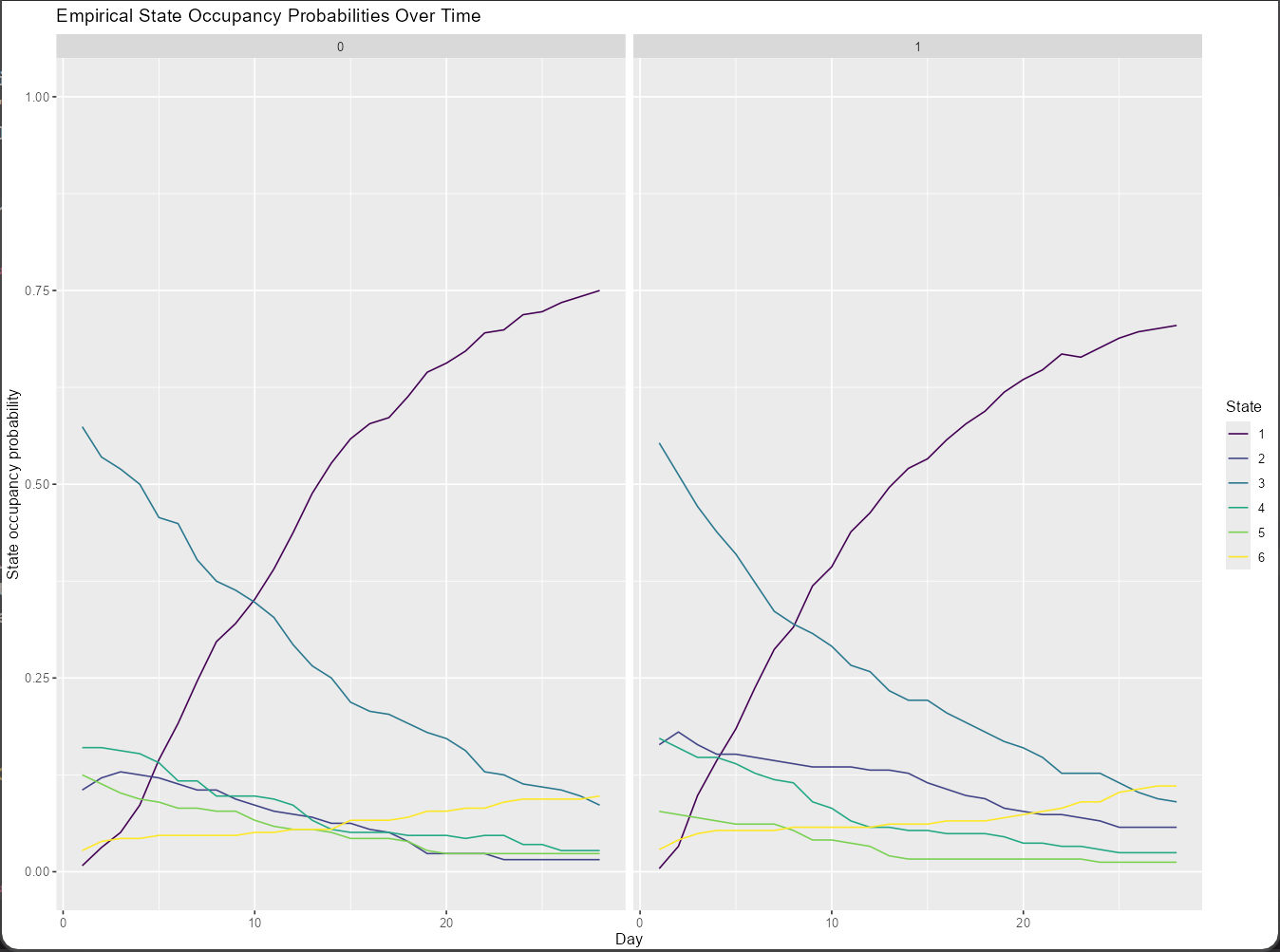
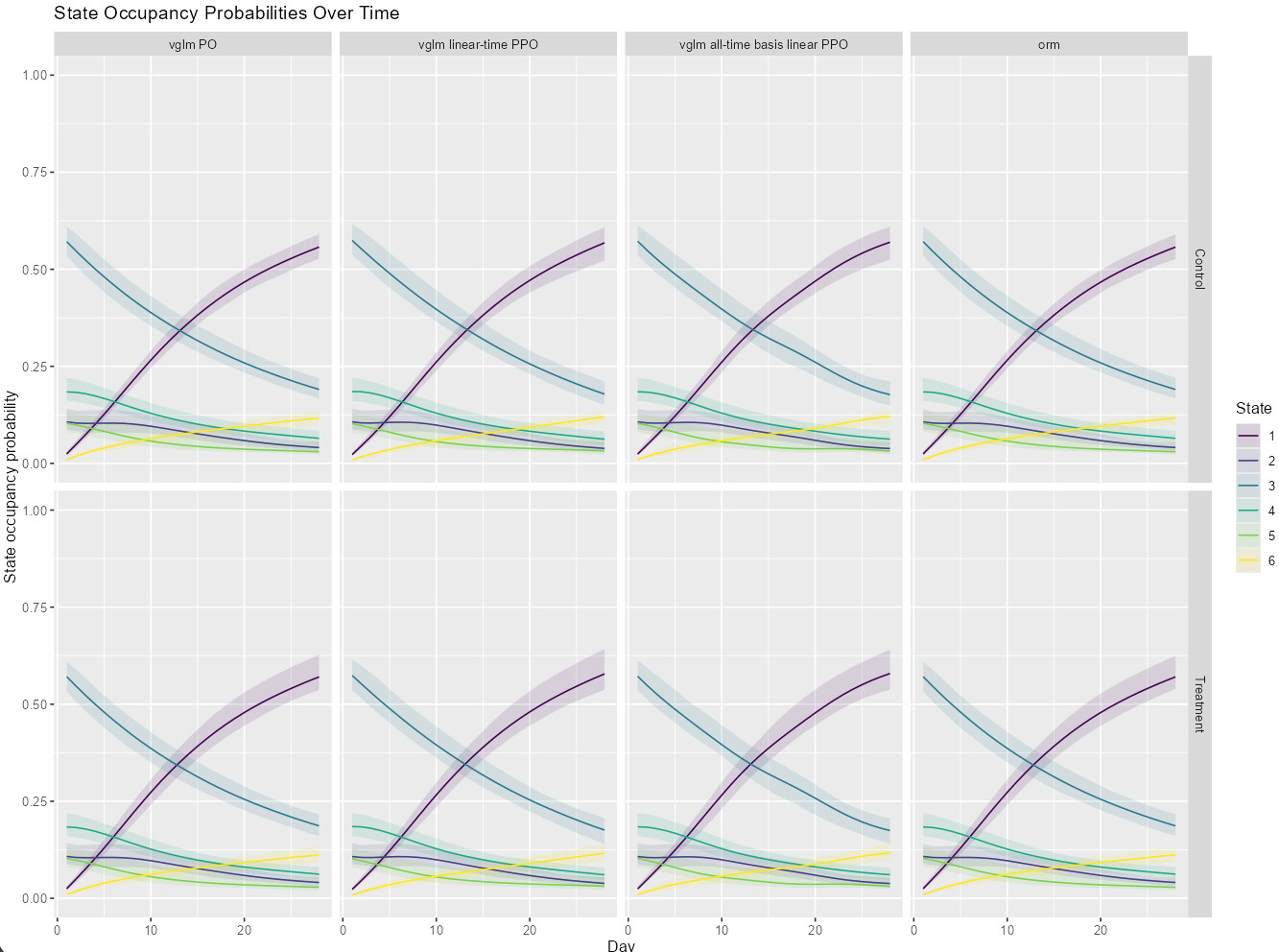
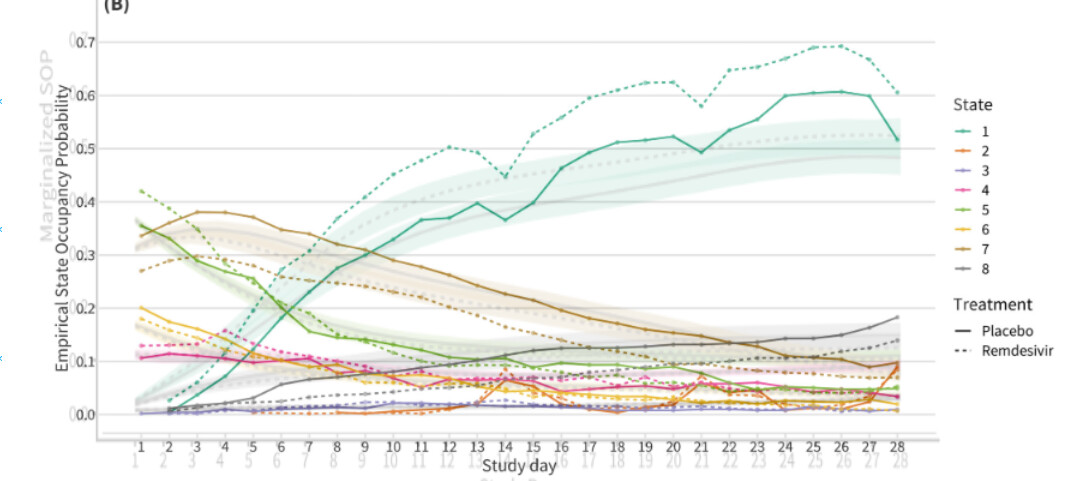
I have a background in Generalized Pairwise Comparisons (Win Ratio and alike). I recently submitted a paper with Prof. Harrell and colleagues on the contrast between GPC, DOOR and MOST (Markov Ordinal State Transition model - discussed here RMS Semiparametric Ordinal Longitudinal Model - data analysis / models - Datamethods Discussion Forum). All that to say that I tend to think of Y in RCTs (what happens to patients) as inherently multi-component.
-
I am drawn to MOST as the most faithful way of capturing Y (setting aside cases where ordering is not meaningful over short intervals). Two aspects appeal to me in particular: it retains more information than approaches such as the Win Ratio, and it does not impose a specific estimand.
-
I have also recently spent some time on the baseline covariate adjustment literature, including TMLE. My question is not about TMLE per se, but rather about borrowing its philosophy. In my understanding, this consists of two steps:
-
first, modeling a component as flexibly and accurately as possible (in TMLE, the outcome regression for which they allow crazy ML methods if one thinks that helps),
-
then, a “targeting” step, which brings that flexible model back into a framework that yields valid inference for the estimand of interest. It essentially tweaks the initial model as little as possible but in order to be back on the objective (usually the ATE in this literature)
-
Usually, that literature focuses solely on the X, trying to be “the best” on that part without discussing anywhere the Y.
- In practice, I operate in an environment where change has to be incremental. A pragmatic first step, as I see it, is to leave the standard estimands unchanged (e.g., a risk difference at a given time point). I am also working within a frequentist context, with its associated constraints such as multiplicity. While I am aware of Bayesians’ views on this, I am trying to move things forward gradually.
Against that background, here is the idea I would like to explore:
-
First, represent the data using MOST, to capture the patient trajectories as faithfully as possible. The components would be the ones that allow me to go back to primary and secondary in usual trials (along all relevant intercurrent events).
-
Second, fit an intermediate (“parent”) model that is optimized for these trajectories as a whole, and thus naturally introduces structural assumptions that allow information to be borrowed across time points and outcome levels.
-
Third, starting from that parent model, introduce an estimand-specific adjustment: one parent model, but different estimands (primary, secondary, etc.).
The key point is that I would like this adjustment to remain small: not a complete re-specification, but rather a minimal modification that nudges the model toward the estimand of interest. Conceptually, I imagine this as optimizing something akin to an MSE criterion: accepting a small increase in bias in exchange for a larger reduction in variance due to the structure imposed by the parent model.
There are two motivations behind this:
-
The assumptions that work well globally (e.g., proportional odds) may not be optimal for a specific estimand. For instance, if the estimand is tied to a cutoff, one might want to relax proportional odds except locally around that cutoff, so that behaviors far from it do not introduce unnecessary bias.
-
At the same time, maintaining a shared parent model and constraining how much it can vary across estimands could offer gains from a multiplicity perspective (which, again, reflects the practical constraints of my setting).
Lastly, an imperfect analogy that comes to mind is subgroup analysis: rather than analyzing each subgroup independently or pooling everything, the best approach is often somewhere in between. Here, I see a similar trade-off between a fully unbiased but inefficient approach, and a “targeted” version of MOST that introduces structure and accepts a small bias.
Stepping back, the ambition would be to say:
i. I aim to represent Y as faithfully as possible, what actually happens to patients.
ii. I aim to make full use of what is known at baseline (X).
iii. I aim to preserve the estimands that stakeholders are used to, even if more informative alternatives may be possible in the future.
iv. The statistical machinery required to achieve this sits on my side.
Before taking this further, I would be very interested in your view: does this overall strategy make sense to you, or do you see fundamental issues that would make it untenable?
Many thanks in advance!