Dear community, dear Professor, thank you for your help.
I might be posting in the wrong topic.
I am focusing on a Cox regression model with a time to event outcome (relapse) and a set of predictors.
My question is how to retrieve the baseline hazard after multiple impution via areg imput (i I’ve followed the case study in chapter 20 plus validation and calibration of chapter 12).
This is a big problem with multiple imputation. Once you’ve done traditional multiple imputation I’d use stacking of all the filled-in datasets for a final analysis where you derive coefficients and the underlying survival curve, since that analysis, though it has the wroing denominator, will be efficient and will not see any missing values.
Thank you Professor for the imput. In case this strategy goes beyond my limited R skills, an approximation with transcan freezing one dataset would be terribly wrong for the sake of the baseline hazard? I would still get confidence interval via multiple imputation.
Not clear about ‘freezing one dataset’. the underlying challenge is keeping the vector of distinct failure times the same for all imputations. If there are no missing failure times or event indicators maybe that’s not a problem.
Sorry for the poor wording I was referring to the procedure of the case study on Cox regression where we use transcan and only one imputation. Amazingly, I have no missing in time to event and in the indicator!
Let’s put a question about variable importance in Cox models under this category.
Hi there,
I want to asses the variable importance of a dataset that will be fitted with Cox PHM model.
The RMS book (section 5.4) shows a way to do that by bootstrapping the ranks of predictors with regards of the partial χ2 minus its degrees of freedom.
When fitting later the Cox models, it would be possible that some of them do not fit properly the Cox assumptions (e.g. linearity, proportionality), so, maybe later we would remove a variable from the moedl or stratify it by any of them.
It could happen that although a variable is important it may not meet the assumptions of the Cox models. One question is whether the importance test we have done is still valid for these variables or not. So, we can say that this variable could be important but it does not meet the Cox assumptions?
The second question is how we can decide whether to incorporate an ‘important’ variable into the model if it does not meet the Cox assumptions. In other words, can we balance the option of considering a variable that does not meet exactly the assumptions but which has a high relative contribution?
Thank you!
Professor Harrell answer:
This raises a lot of interesting issues. I wish this topic had been put under the existing Cox model page so that others would more easily find it.
Dropping a variable or stratifying on it can be a worse solution than not satisfying PH in some situations. A coherent solution with more linear thinking is to fit a Bayesian proportional hazards model with non-PH for most of the variables, with non-PH handled by interacting covariates with time. Prior distributions would restrict how much non-PH you want to allow especially for small samples. Variable importance measures would combine the importance of PH and non-PH components for a covariate.
Thank you for your quick reply.
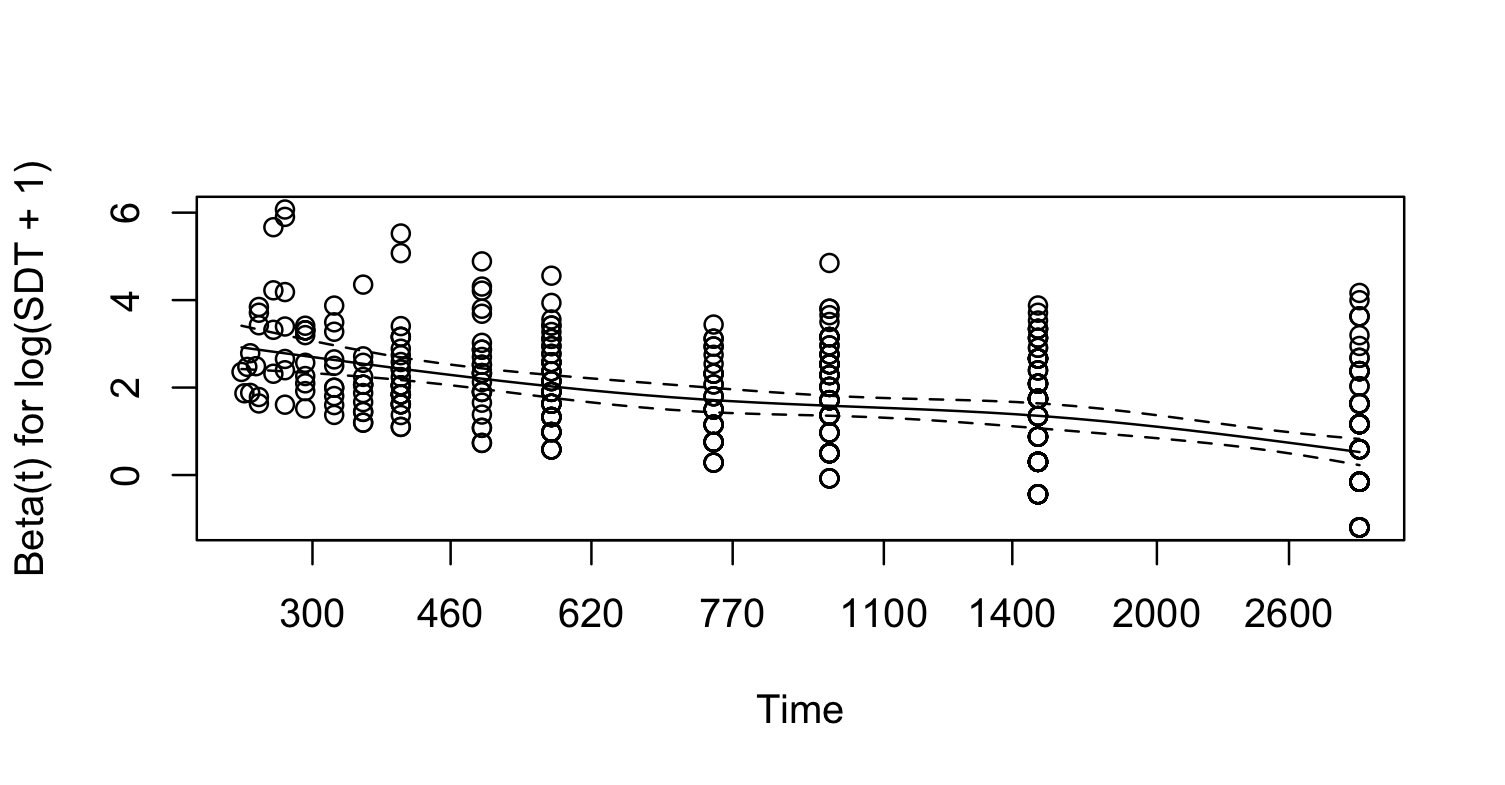
In my specific case, I have a very important variable (SDT), which I parameterised with log to relax linearity. The residuals plot is like this:
cph_cox_model ← cph(Surv(MTBR, STATUS) ~ log(SDT+1), data = g, time.inc=1500, surv = TRUE, x=TRUE,y=TRUE, tol=1e-13, ties = ‘efron’, id = id)
cox.zph(cph_cox_model)
chisq df p
log(SDT + 1) 82.5 1 <2e-16
GLOBAL 82.5 1 <2e-16
Do you have suggestions about which transformation could help me to relax the negative slope? I tried different ones (srt, 1/log(), ^2 and restricted cubic splines) and I did not improve it.
If it 's not possible, do you think that the bayesian approach would be a choice? I guess there would be a way to assess how this assumption violation could affect the performance of the model, either using only this variable or using all the others together with it. but I’m still looking for it.
\beta(t) vs t is a plot of the changing effect of one \beta over time. This may inform you about how to transform t in a time-dependent covariate but is sort of unrelated to the transformation of X on the right hand side of the model.
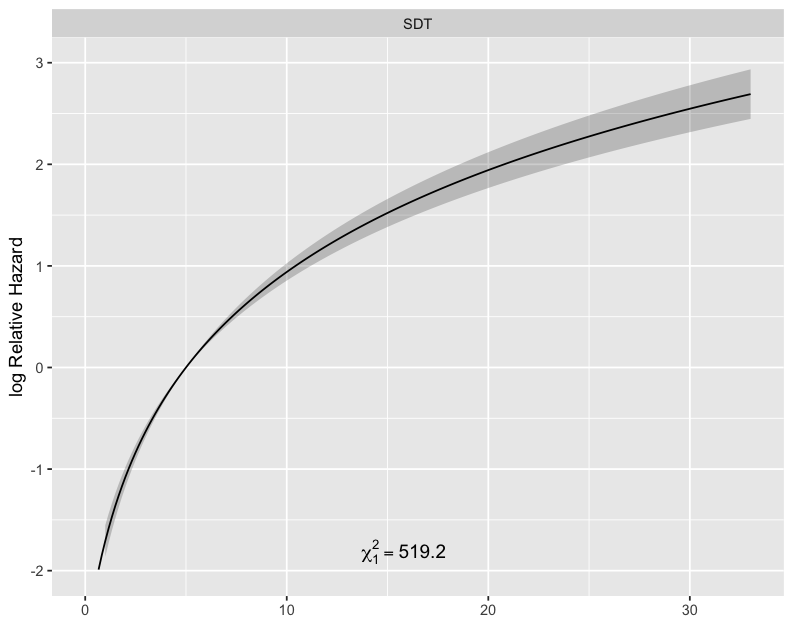
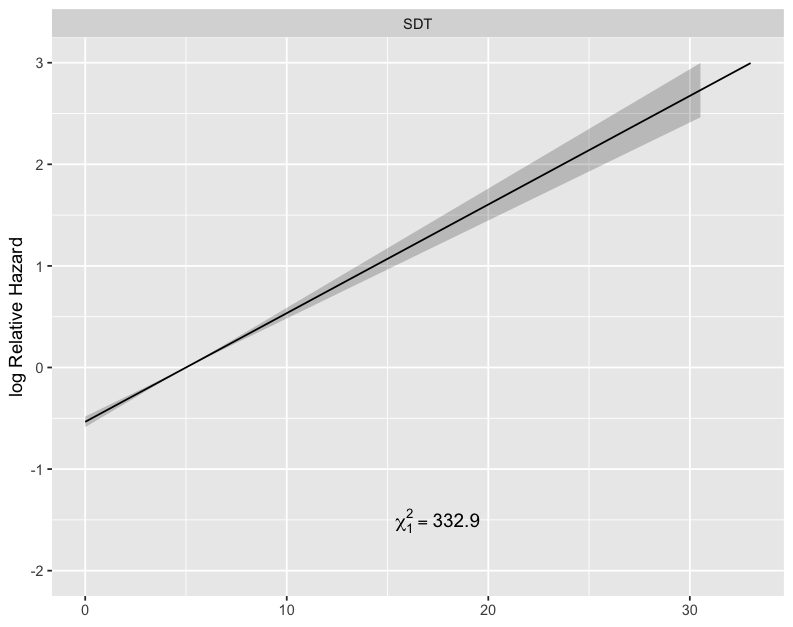
My log parameterisation allowed to maximise the relative chi2 in the model:
increasing what i got with linear approach:
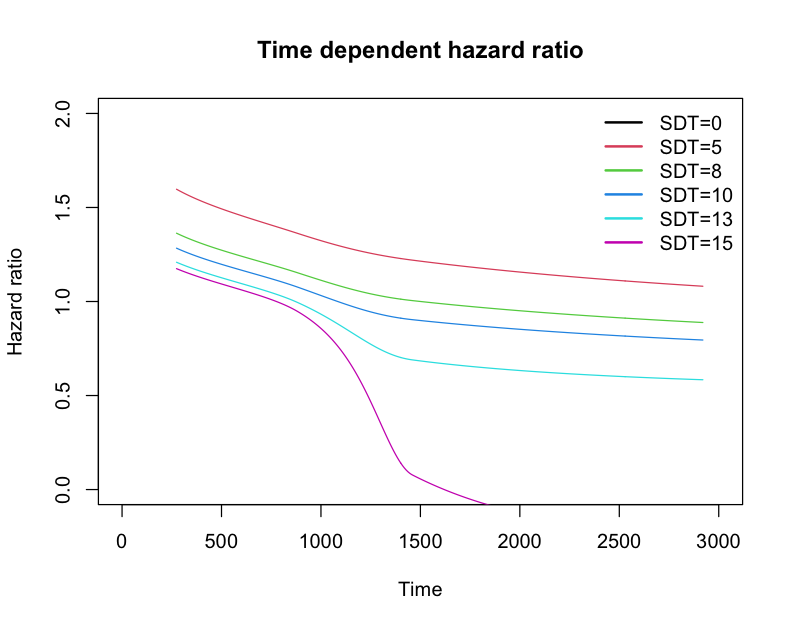
This the hazard ratio vs time that I get with different values of SDT:
The model fitted with log approximation leads good calibration and overfitting results, but I have a concern with the shape of the residuals and the possible time-dependency of the hazard ratio of the variable SDT.
Stratify SDT into 5-10 equal-sized groups depending on the overall N. Compute stratified K-M curves. Make plots of g(t) vs. t for g= log-log, logit, normal inverse. See if a link other than log-log (assumed by PH) works better, i.e., see if an accelerated failure time model provides a better fit. More here.
Hi,
with regards: “A coherent solution with more linear thinking is to fit a Bayesian proportional hazards model with non-PH for most of the variables, with non-PH handled by interacting covariates with time. Prior distributions would restrict how much non-PH you want to allow especially for small samples. Variable importance measures would combine the importance of PH and non-PH components for a covariate.”
→ Which RStudio package/s would you reccomend to fit bayesian proportional hazards model with RStudio to address the above-mentioned issues?
RStudio is a graphical user interface and integrated development platform for R. So I assume you meant to say R instead of RStudio.
For the types of survival models I’m alluding to, the best best is flexible parametric proportional hazards models. These are beautifully implemented in the rstanarm survival system in R: https://arxiv.org/pdf/2002.09633 . This is not available from CRAN but there are installation instructions in the paper.