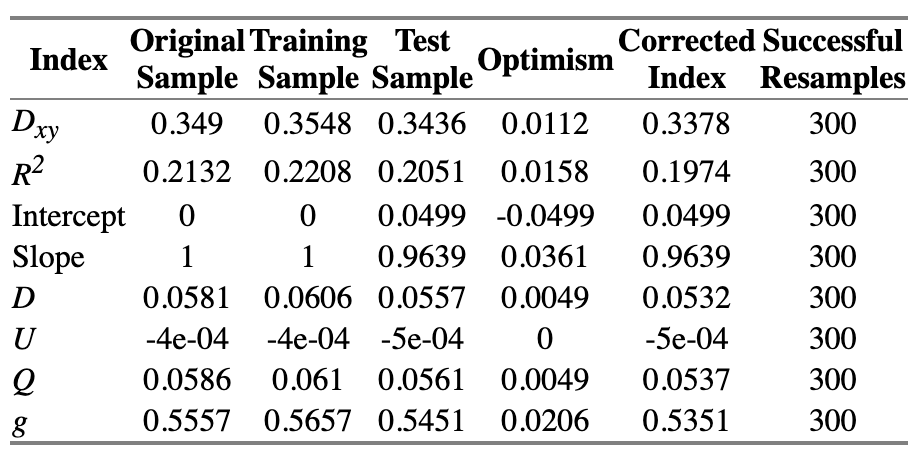
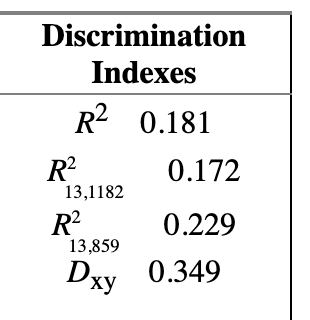
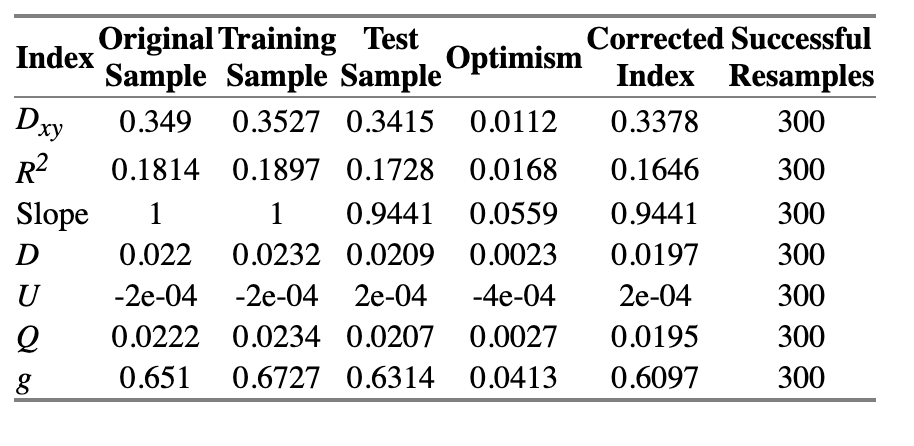
Hi everyone, here is my attempt to summarize the main idea from rms course. I have not seen a coherent philosophical/logical write-up out there yet, would love to have Frank’s correction on this and everyone thoughts and contributions to this write-up.
The course seems to (day 1 and 2) ben centered around relaxing the regression assumptions so that our models would be closer to nature.
These assumptions are:
- Linearity of effect and additivity (absence of interaction)
- Distributional assumption: like assuming a normal or gamma distribution for the outcome (associated with parametric methods), and relative distributional assumptions (like equal variance or proportional odds)
Linearity of effect and additivity
Additivity
What everyone should be careful here is the “phantom degree of freedom” (really like this term), that is, testing variables in a stepwise fashion.
If you fit a model with multiple terms (parameters) and then remove terms that appear insignificant (e.g., if a coefficient’s p-value is not below a certain threshold), and subsequently calculate standard errors or conduct further tests using only the remaining variables, the resulting standard errors will be too small.
Simulating this process shows that even though you test what appears to be a smaller number of parameters, your effective alpha (false positive rate) is inflated compared to the nominal level (e.g., 0.05)The omitted parameters are “haunting the analysis” - hence a phantom.
For example, if you tested a quadratic term for significance and then removed it, testing the linear term afterward leads to an inflated alpha because you had two “opportunities to be not flat” (one via the quadratic, one via the linear term)
=> Solution: chunk test - A chunk test is a multiple degree of freedom test designed to assess the joint association or importance of a group of parameters or variables simultaneously
Linearity
I will paraphrase what Drew said: very seldom there is a linear relationship in nature
=> Solution: restricted cubic spline (rcs)
The technical note on why we should use rcs instead of other forms of spline is quite fascinating. Just a note on practice and connect things back to the the phantom degree of freedom/multiplicity, when using splines for continuous predictors, assessing the overall association of that variable with the outcome requires testing all the parameters associated with it (the linear term and all spline terms) simultaneously.
Distributional assumptions
The course seems to favor ordinal model because of the following:
- A primary reason for favoring these models is their semiparametric nature, meaning they do not make absolute distributional assumptions about the outcome variable. This is a significant advantage over parametric models like linear regression, which require assumptions about the distribution of residuals (e.g., normality). While ordinal models do make relative distributional assumptions (like proportional odds), these are generally less stringent and can often be chosen for better fit (e.g., using a log-log link instead of logit)
- Versatility and Handling Non-Ideal Outcomes: Ordinal models are highlighted as being robust to outliers on the outcome and naturally handle ties and detection limits ( I actually have not grasped the technicality on this). Crucially, they are also advocated for analyzing continuous outcomes, especially when those outcomes have ties, non-normal distributions, or floor/ceiling effects, offering advantages over assuming normality with linear models. (also, I have not grasped this technicality of this). Apparently, this is the feature of the proportional odd assumption where we only need to estimate computationally the intercept for each level of the continuous variables, which is an easier task than estimating the coefficient
- From 2, an ordinal model can provide a variety of useful predictions, including the probability of exceeding various thresholds (exceedance probabilities), predicted means, and predicted quantiles (such as the median). This allows for a more complete understanding of the predicted outcome distribution than just estimating a mean or single probability.
There are also a lot of gems in graphical method, to communicate and interpret model, that Frank showed us, here are my attempts to summary them:
- Partial Effect Plots: These are a primary graphical tool for interpretation. They allow you to vary one predictor continuously (or across its categories) while holding other predictors constant (often at their median or mode) and plot the predicted outcome (e.g., linear predictor, probability, mean, median)
Frank advocate for this as an alternative to the interpretation that “changing by one unit while keeping other variable constant”
- Nomograms: Presented as a powerful and transparent tool, nomograms integrate the effects of all predictors in the model into a single diagram
◦ For each predictor, they show how its values contribute to a “points” scale or directly to the linear predictor (like log odds or log hazard)
◦ These points/linear predictor can then be mapped to the final predicted outcome, such as the probability of an event, predicted mean, median, or other quantiles.
◦ Nomograms are described as the “antithesis of a black box” because they make the model completely visible and allow for manual calculation of predictions
- Contrasts and Plotting Contrast Results: While “contrast” itself is a way to define specific comparisons between predictor settings (e.g., comparing the predicted outcome for a 30-year-old male vs. a 60-year-old female), the results of multiple contrasts can be plotted to visualize the effect of a variable relative to a reference value. My understanding of this is that you can make a plot with your reference as a constant ( a straight line on the x-axis) and plot the change of the exposure/compared group.
4.. Relative Explained Variation (REV) Plots: Derived from concepts like likelihood ratio chi-squares, REV is a measure of variable importance – specifically, the proportion of the model’s explained variation that is attributable to a subset of terms or a specific variable
Plotting REV allows for a graphical comparison of the relative contributions of different variables to the model’s predictive power.
Confidence intervals for REV can also be plotted, which are called “honesty inducing intervals” because they show the uncertainty in estimating variable importance, especially with limited sample sizes.
Thank you Frank and Drew for the first 2-day of the course! I hope this write up would be beneficial for people.