I am curious about the differences between assuming a negative binomial distribution vs a truncated normal distribution, for my outcome variable(y) . Here’s the context:
An assessment test is administered , aiming to evaluate participants’ restlessness. The responses to these questions are aggregated, resulting in a continuous total score ranging from 0 to 150. Subsequently, this total score is transformed into a population-level t-score, with a presumed mean of 50 and standard deviation of 10. This t-score, is my outcome (y),
The distribution of this t-score, assumed to follow a normal distribution, is skewed, ranging from 27 to 100. A considerable number of participants exhibit lower scores, with fewer participants achieving higher scores. Lower scores are good, this means the participants are not restless.
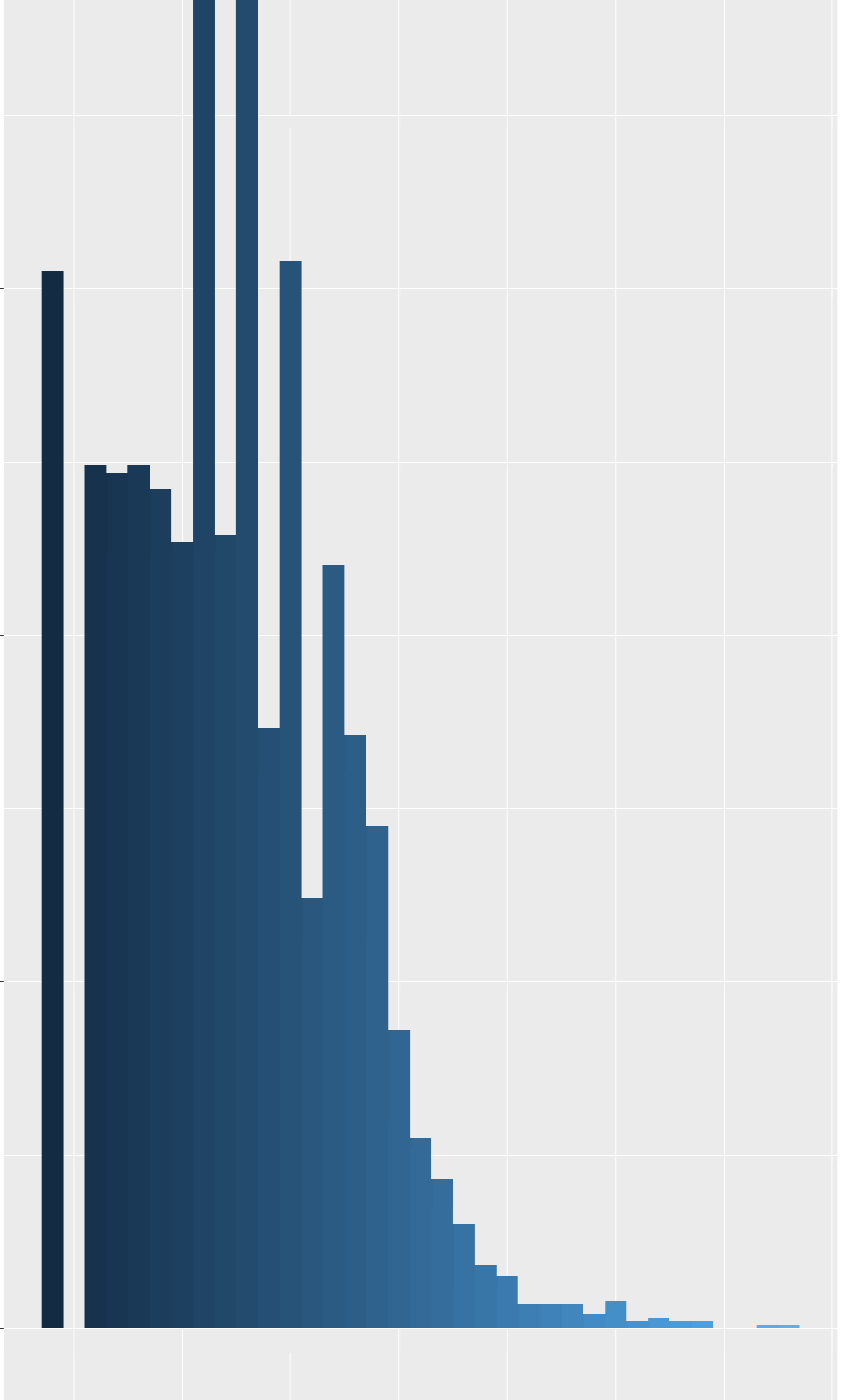
My question is what are the trade offs when I assume my outcome follows a truncated normal distribution versus a negative binomial distribution. This is a repeated measure data. There are 1000 participants and I have repeated observations (2 or 3) for 400 and only single measure for 600 participants. Your advice is greatly appreciated. Thanks in advance.