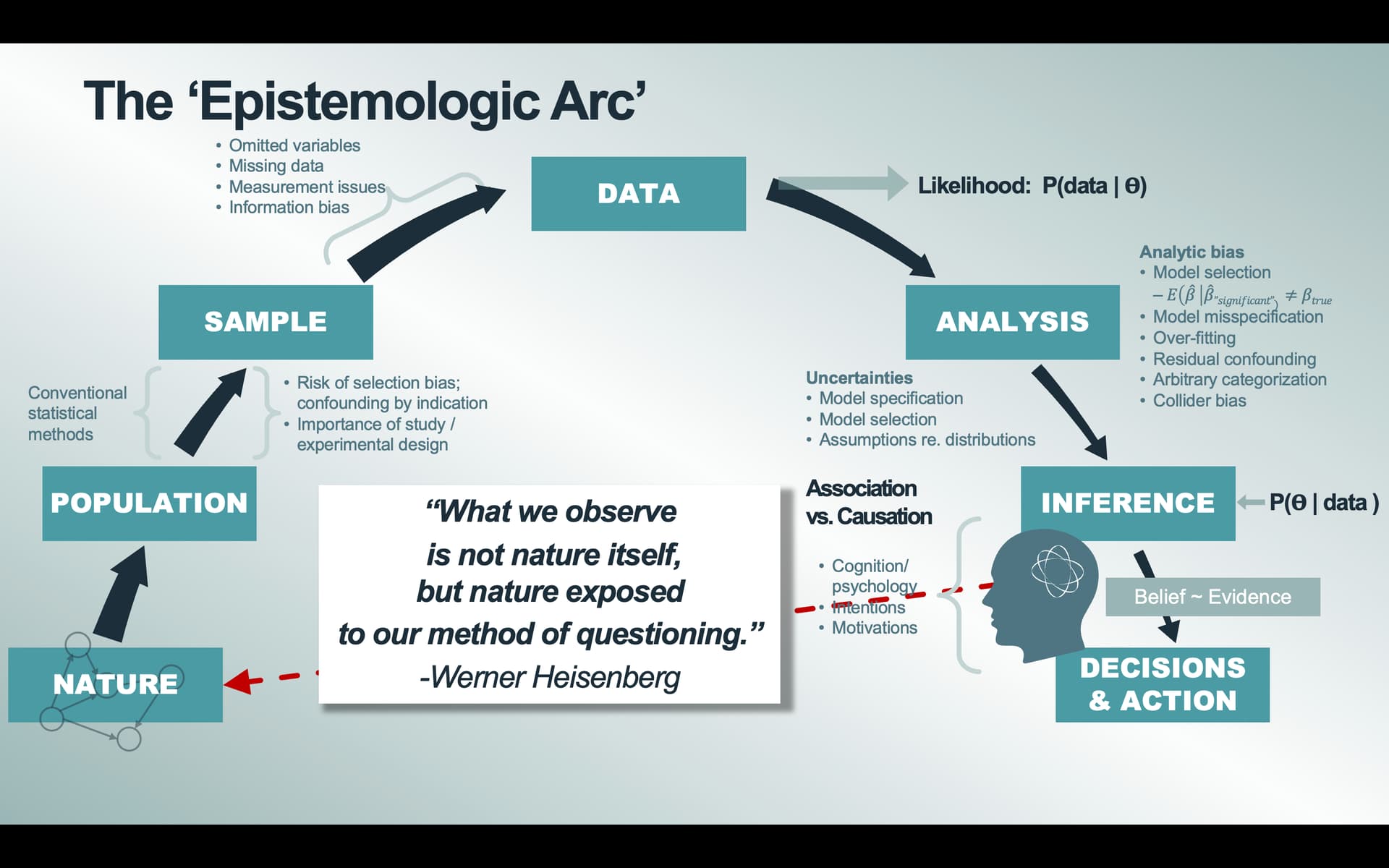
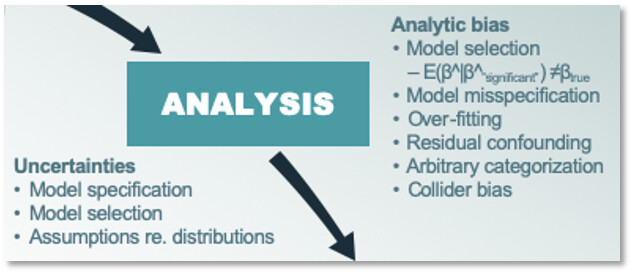
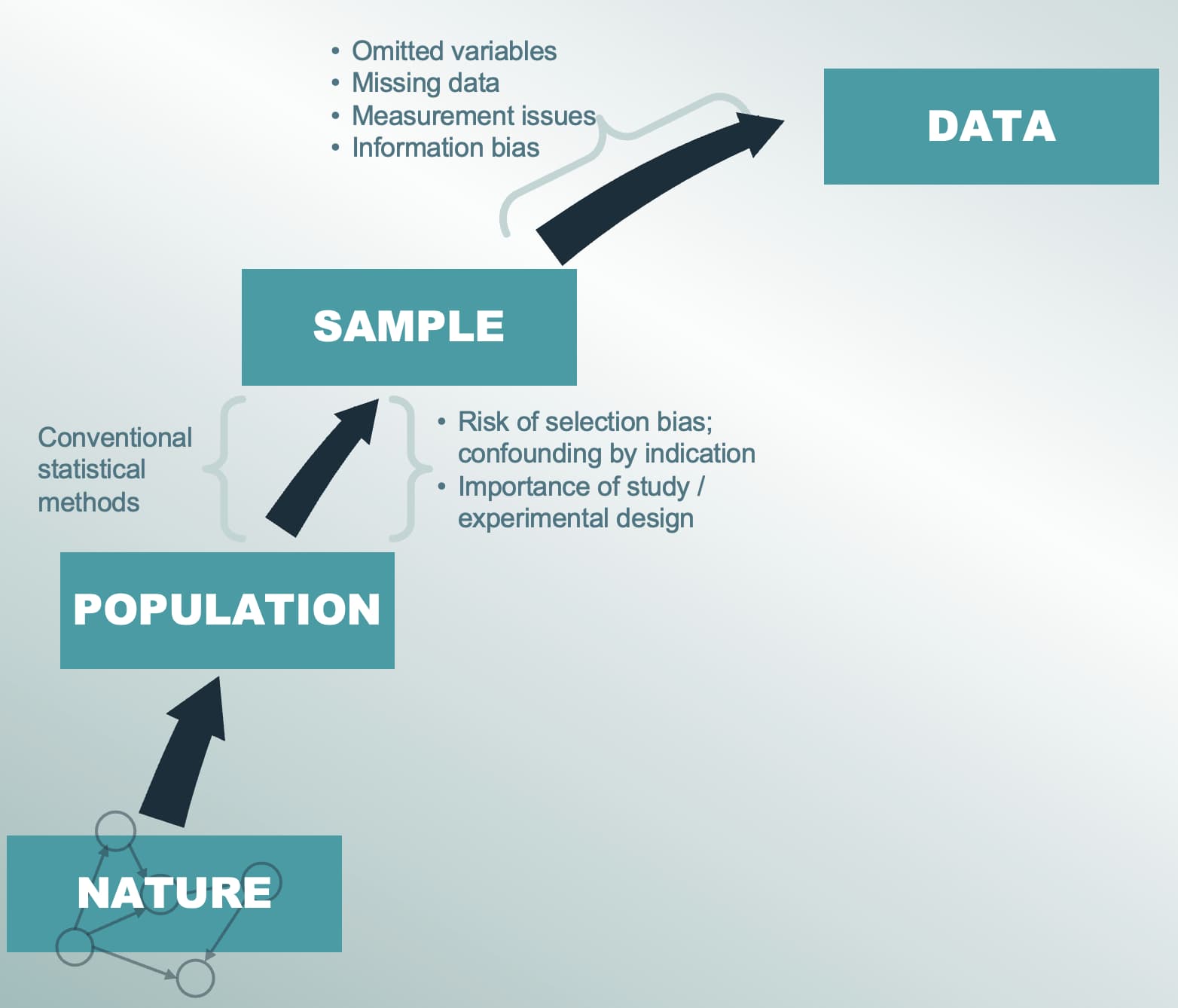
This is the first of several connected topics organized around chapters in Regression Modeling Strategies. The purposes of these topics are to introduce key concepts in the chapter and to provide a place for questions, answers, and discussion around the chapter’s topics.
The regression modeling framework for statistical analysis accommodates all the fundamental statistical interests of estimation, hypothesis testing, description, bias mitigation, and prediction;
The ultimate measure of statistical veridicality is “accurate prediction of responses for future observations”—so all inferential statistical objectives are optimized in as much as model predictions are performant;
Every hypothesis test implies a model—and models, moreover, make many of the underlying assumptions of hypothesis tests explicit;
It is advantageous to approach effect estimation from a model as differences in predicted values;
For comparison of responses or outcomes among groups, multivariable models are important—even for randomized designs;
Development of the most accurate and reliable predictive model will enhance any/all of an analysts’ research interests;
There are many ways and reasons that developing a model which will yield accurate and reliable predictions can go awry, but a principle-based approach guiding empirical model development can be felicitous;
A principal-principle is, for an efficient and valid analysis, thoughtful selection of a response variable that is faithful to the nature of—and information in—the problem is crucial (see BBR notes 3.4.1. Proper Response Variables);
And, finally, ‘friends don’t let friends’ categorize continuous response variables!
? (dgl) for the class: Anything important about Chapter 1 missing from Comment-1? Anything mis-stated or ill-expressed?
With FH’s recent emphasis on Bayesian perspectives, how would the precepts in Chapter 1 from RMS (2015) be amended or revised? What, if anything, would you now put differently? FH: Great question. I can think of two changes: (1) When Bayes is at its best, hypothesis testing plays no role IMHO, so I would de-emphasize hypothesis testing and add decision making/playing the odds. (2) The Bayesian approach has a lot to say about model choice, i.e., in some cases it avoids the need to choose a model by having traditional model components (and non-shrinkage priors for them) supplemented by extensions of the model, with priors that require these extensions to be convincing, i.e., shrinkage priors that wear off as n gets large. A simple example of this is the Bayesian t-test that favors normality with equal variances but has priors for the log variance ratio and the amount of non-normality.
JM: I noted in the pre-course material that “Subgroup analysis is virtually worthless for learning about treatment effects” Why is this true? Nice post from Harrell regarding this topic Statistical Errors in the Medical Literature – Statistical Thinking FH: Some of the issues are imprecision from the smaller sample size, lack of covariate adjustment, and failure to demonstrate interaction.
In line with question 3 I would be interested in whether predicting treatment effects using it as a dependent variable in a regression model makes sense? What would be a good approach to predict treatment effects? FH: Can only estimate a patient’s treatment effect in a cross-over study.
Comment: I fear that the rumor of the death of ML is greatly exaggerated, having just participated in the statistics judging for the ASA Special Award in Statistics at the International Science and Engineering Fair 2021. These are high school students, and over half of the projects used some form of ML, mostly without careful thought. And, sadly, several of the statistics judges recommended many of the worst for the ASA Award for “best use of statistics”. Sigh.
Do you have more information or can you talk about the issue of omitting time in the Probability of Ever having Cancer in 5 years model? FH: The idea is to model time to event as a continuous variable, with proper handling of censoring.
Frank, there is a statement that survival model are essentially binary counting process, is that a true statement? Can we dichotomize the events at certain time point? Say if you have a 10-year survival, you can estimate the model by 1, 2, 4…. Year binary models? FH: Yes there is a counting process formulation but this doesn’t amount to using binary Y. The binary models would each be ineffective but you could combine them in some way to get over some of that problem were there to be no censoring.
Can you explain some real world scenarios to choose between Cox model and accelerated faillure model? FH: We’ll get to that in a case study.
Frank’s objections to stepwise regression are well-known. But, in ecological journals now, investigators are fitting a suite of regression models—even non-hierarchical models—presenting the table of AICs, and selecting for discussion & interpretation the model with the lowest AIC (or lowest group of regression models within 2 AIC units). Isn’t this as bad as stepwise or other automatic selection routines? Yes that’s just stepwise in disguise, but if you only compare 2-3 AICs things work pretty much OK.
1.3. We discussed how ROC analysis is misleading. In the context of survival analysis, we have the option to report Harrell’s C-statistic or IAUC (Integrated Area Under the Curve). Could you please comment on whether reporting IAUC is appropriate? FH: I don’t have enough experience with IAUC. The ordinary c-index is pretty simple to interpret so I stick to it.
You discussed in this section that in a RCT adjusting by baseline covariates improves efficiency (and would lead to lower sample sizes needed to detect a given effect). How would you factor that adjustment in sample size calculation (since the calculators available that I know do not allow for that)? FH: For linear models it’s not hard. For other models people tend to use simulation. But need to have pilot data for that.
Hello @f2harrell and @Drew_Levy. I’m taking the RMS short course right now (May 2023). In the online RMS book Section 1.6 Model uncertainty / Data-driven Model Specification, the audio recording refers to Peter Austin’s bootstrap method for stepwise regression that involves something like assigning zero for variance when the variables were not selected. Could you please give me the full reference to this? I have a stepwise regression project (which I will post about in a separate message) and I would like to learn to do things properly.
Stepwise variable section with bootstrapping
What is the reference to Peter Austin’s bootstrap method of assigning zero for variance when the variables were not selected?
Hello @f2harrell and @Drew_Levy. Please excuse the long preamble, but I think it is necessary so that you can detect the risks of my study design and hopefully guide me towards an appropriate design.
I am a business professor. I have a project where I am trying to use discover relationships between variables that represent national culture and other socioeconomic variables such as national corruption levels (e.g., bribes). Each line of data is a country, so each regression analysis has anywhere from 50 to 100 lines of data each. I have several sets of culture variables that go together each time (around twenty different sets of around 5 to 10 variables each). Each of these sets come from a different major study in the literature that represents national culture in multiple dimensions. For example, one famous study conceptualizes national culture in four main dimensions for around 80 countries: individualism-collectivism; uncertainty avoidance; power distance; masculinity-feminiity. This would represent one set of dimensions d1, d2, d3, d4. I have around 20 such sets, each with different dimensions and for a different number of (mostly overlapping) countries.
I do not have any specific hypothesis other than that certain dimensions of national culture are related to national corruption. The goal of the study is to inductively discover such dimensions in a rigorous and reliable way, statistically taking into account the exploratory nature of the study without prespecified specific hypotheses.
My current study design has two main steps.
First, I need to identify non-cultural control variables that are also related to national corruption (e.g., GDP, political freedom, etc.). I have identified 10 to 15 such variables from the literature. However, I want reduce this list to a minimally parsimonious list, so I want to apply feature selection with all of them together and only include those that are strongly related to corruption when all these control variables are put together (without any culture variables). For this, I apply AIC-based stepwise regression. This reduces the control variables to a set of five to seven rather than 10 to 15. Then for the final selection, I run this control variable model regressed on corruption with 2000 bootstraps and then I finally select only those control variables that are statistically significant with a 95% bootstrapped confidence interval. Let’s call this final set c1, c2, c3.
Second, for each set of culture dimensions, I create a model to estimate corruption with inputs as all the culture dimensions in that set plus the reduced set of control variables. For example, with the example above, I would set up a model like Corruption ~ c1 + c2 + c3 + d1 + d2 + d3 + d4. However, there is typically high multicolinearity between some control variables and some cultural dimensions. Thus, some cultural dimensions have non-significant coefficients which cannot be interpreted, not because these dimensions are irrelevant to corruption but because they are so highly correlated with some control variables that their effects are masked. To resolve this issue, I use stepwise regression to reduce this model to a more parsimonious form; it might become something like Corruption ~ c1 + c3 + d1 + d2 + d4. Then I run this reduced model with 2000 bootstraps which might yield that, of the cultural dimensions, only d1 and d4 are statistically significant with a 95% bootstrapped confidence interval. I then proceed to interpret the coefficients of d1 and d4.
Note that I rerun the second step around 20 times for each of the 20 or so sets of cultural dimensions. I do not attempt to run all cultural variables in a single model because:
Each of the sets of variables go together and have already been optimized by their respective studies to maximize orthogonality (that is, minimizes overlap across each other). To lump variables across different studies would involve massive multicolinearity.
Each of the studies covers a different set of countries. If I studied all sets together, I would not have more than ten countries that are covered by all studies.
I know that stepwise regression is heavily frowned upon, but I feel that I need some sort of legitimate feature reduction procedure for the two steps above (parsimonious set of control variables and then parsimonious set of control + culture variables to maximize the chances that the final set of selected cultural dimensions can be statistically significant).
So my question:
Is there a legitimate feature reduction procedure that can give me parsimonious models that can yield interpretable cultural dimensions?
Is there a way that I could use bootstrapping or some other procedure to incorporate the correct degrees of freedoms in my standard errors that take into account the feature reduction that was done prior to my final models? As I hinted in my other post, I wonder if an adjusted procedure might make stepwise regression more robust
Austin’s method is to assign a regression coefficient of 0 for bootstrap iterations in which a variable is not selected. At the end you’ll compute the variance of the bootstrap \hat{\beta} a sample of which may look like [0.1, 0.15, 0, 0.7, 0.9, 0]. Including the zeros increases the variance in comparison to omitting them and just computing the variance from the samples in which the variable was selected. This accounts for model uncertainty, and also begs the question of why force a variable to have exactly zero impact just because the p-value is larger than some arbitrary cutoff?
I’m going give the class a link to a library of articles related to the course. From that look for Austin’s paper under the bootstrap folder, file aus07boo.pdf.
The use of feature selection in this context, like most others, is fairly dangerous and prone to overinterpretation. When using AIC for feature selection this is just setting a larger-than-usual threshold for a p-value. That’s a good thing but the best threshold goes far above that, i.e., does not remove many variables.
I think that undersupervised learning should be emphasized for this project, whereby you stop trying to let variables, especially collinear ones, compete with each other.
Thanks very much. I’ve obtained the Austin article now. Your course has given me very much to consider deeply as I redesign this study. I might post follow-up questions in the appropriate threads in the future.
I would like to thank the RMS-short course 2023 students for their engagement, their curiosity, their good questions, and for sharing their knowledge with others.
Two very apt quotes from students appropriated from the course Zoom chat (possibly somewhat adulterated) are worth reiterating:
‘The more you we learn, the more we learn that there is more to learn.’
“It may not be what I want to hear, but maybe it is what I need to hear.”
Unlike Sir R.A. Fisher, who invented the statistical thinking we were all inculcated with and which persistently remains as prevalent practice, we are rarely analyzing designed experiments with tidy complete data. We have to adapt (upgrade) our methods and rigor to meet the challenges of modern research problems and respect the full data generating process.
The spending-of-information concept —and the ‘df-spending’ concept —is so important; cannot be over-emphasized.
A basic RMS ethos: Models that reliably predict future observations is a fundamental objective of analysis for research (for valid estimation, hypothesis assessment, etc.) as well as for prediction purposes.
A general principle from RMS is iterative ‘tinkering’ to optimize a model involves phantom df’s, and creates validity issues and unreliability in predicting future observations. Whether is it with p-hacking, stepwise, pre-screening bivariate relationships, or AIC tuning or anything else, the tinkering to optimize leads to problems. Careful pre-specification with commitment to the ‘least-worst’ model in general does better. Pragmatically, something in-between is frequently done: but this should be done judiciously, carefully and with honesty (and transparency).
Getting really good at understanding how to handle prevalent ‘missing-ness’ should be recognized as basic competence and/or celebrated as an indicator of sophistication.
The data, per se, cannot tell you what the model should be.
The options for model selection and specification include guidance from extrinsic causal models based on subject matter understanding; or if subject matter agnostic, using data reduction or shrinkage methods. The material in BBR 17 Modeling for Observational Treatment Comparisons is relevant and should be studied as well.
Analysis is a craft that requires informed, educated judgment and benefits from experience. We cultivate our own experience; but in the meantime we draw on Frank’s experience and insight.
Some of the things we do are subjective, but that subjectivity should be informed by experience and principles: especially a principled choice of statistical methods (see Chapters 2,3 and 4 of the book).
The quality of the dependent variable is a crucial determinant of the performance of the model and the quality of the analysis overall. Give thorough consideration to the information content of the dependent variable, and seek ‘high-information’ Y’s wherever possible.