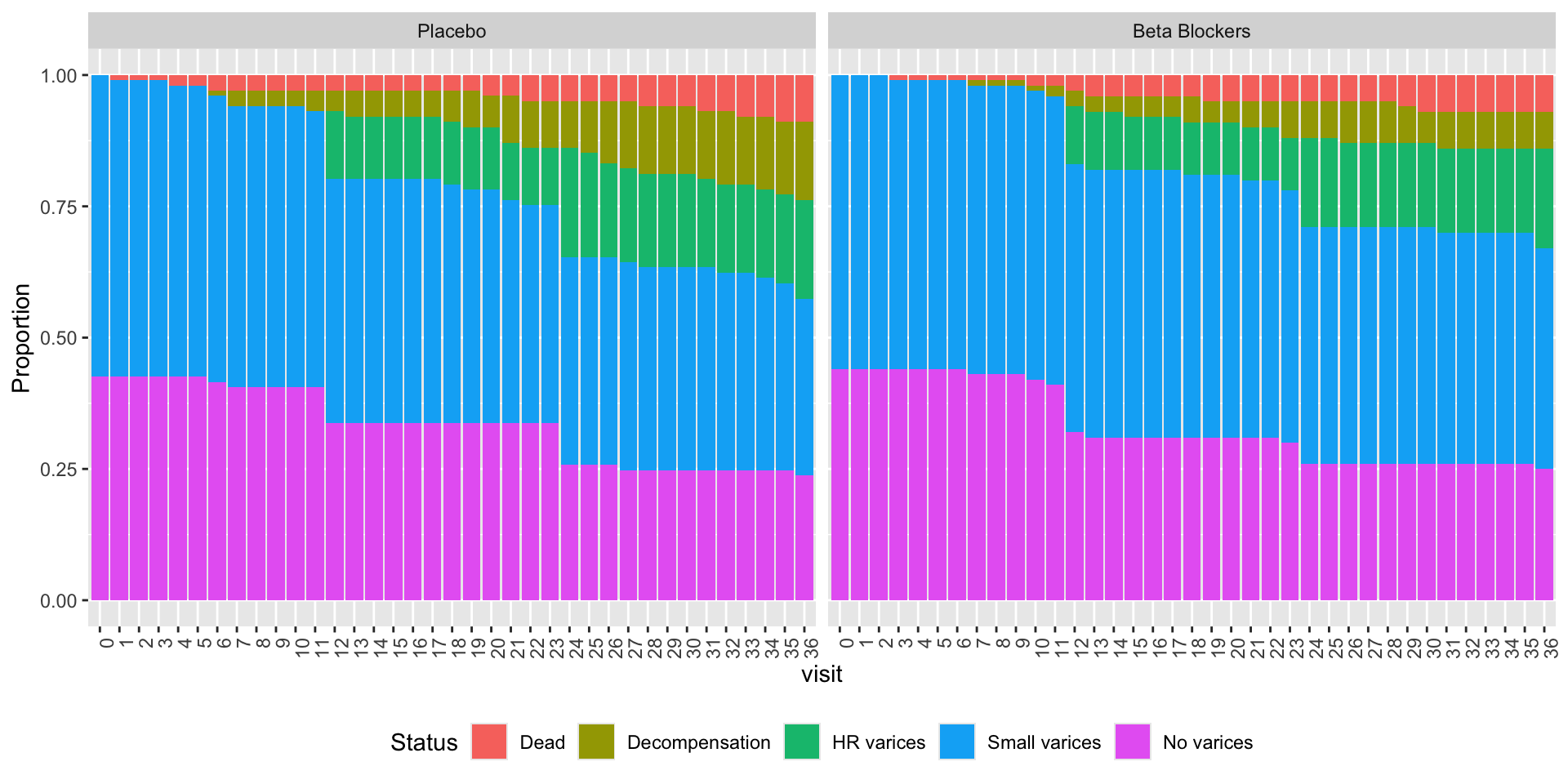
Yes, I was thinking along those lines! (Though this is just based on some vague ‘intuition’ rather than any theory, at which I’m pretty bad…)
I didn’t have time to get robust SEs to work with VGAM, but I did run some simulations as you suggested, just with naive SEs.
- All effects are proportional and linear
- 5 categories of Y
- Intercepts : -6, -3, -2.5, -2 → (category 1 (reverse coded) is by far the most common initially)
- 28 time points (1:28)
- Proportional effect of time log(0.95) on logodds scale
- Effects of yprev similar to my historic data:
yprev=2 = log(10),
yprev=3 = log(3),
yprev=4 = log(40)- Effect of omitted covariate X ranging from -4 to 4
Code:
Data Generation
Setup
library(tidyverse)
library(VGAM)
library(arrow)
Simulate baseline data
N <- 250000
x_effects <- seq(-4, 4, by = 0.5)
times <- 1:28
# intercept and parameters
ints <- c(-6, -3, -2.5, -2)
# treatment effect
parameter <- 0
Simulation Function
g <- function(yprev, t, tx_val, x_val, parameter = 0, extra_params) {
# 1. Treatment Effect
tx_effect <- parameter * tx_val
# 2. Effect of covariate X
cov_effect <- extra_params["X"] * x_val
# 3. Effect of time
time_effect <- extra_params["week"] * t
# 4. Previous state effect
yprev_effect <- 0
# Create the name to look up in the 'extra' vector, e.g., "yprev=2"
yprev_coef_name <- paste0('yprev=', yprev)
if (yprev_coef_name %in% names(extra_params)) {
yprev_effect <- extra_params[[yprev_coef_name]]
}
# Sum all effects to get the linear predictor
lp <- as.numeric(tx_effect + cov_effect + time_effect + yprev_effect)
return(lp)
}
Apply simulation function
Create baseline data
X_base <- data.frame(
tx = sample(c(0, 1), size = N, replace = TRUE),
X = rnorm(N),
yprev = sample(c("1", "2", "3", "4"), N, replace = TRUE, prob = c(0.8, 0.1, 0.05, 0.05))
) |>
mutate(patient_id = row_number())
Generate datasets
for (current_x_effect in x_effects) {
cat(paste0("--- Starting simulation for X effect = ", current_x_effect, " ---\n"))
# a. Set the model parameters for the current scenario.
extra <- c(
`yprev=2` = log(10),
`yprev=3` = log(3),
`yprev=4` = log(40),
week = log(0.95)
)
extra["X"] <- current_x_effect
# b. Initialize the matrix to store patient states over time.
state_matrix <- matrix(
as.numeric(X_base$yprev),
nrow = N,
ncol = length(times) + 1,
dimnames = list(X_base$patient_id, 0:28)
)
# c. Run the simulation over the time points.
for (t in times) {
yprev <- state_matrix[, t]
active_idx <- which(yprev != 5)
if (length(active_idx) == 0) {
if (t <= max(times)) {
state_matrix[, (t + 1):ncol(state_matrix)] <- 5
}
break
}
yprev_active <- yprev[active_idx]
X_active <- X_base[active_idx, ]
lp <- mapply(
FUN = g,
yprev = yprev_active,
tx_val = X_active$tx,
x_val = X_active$X,
MoreArgs = list(t = t, parameter = parameter, extra_params = extra)
)
thresholds_matrix <- outer(ints, lp, FUN = "+")
cum_probs <- t(plogis(thresholds_matrix))
prob_matrix <- cbind(cum_probs, 1) - cbind(0, cum_probs)
y_new_active <- apply(prob_matrix, 1, function(p) {
sample(5:1, size = 1, prob = p)
})
state_matrix[, t + 1] <- yprev
state_matrix[active_idx, t + 1] <- y_new_active
}
# d. Format the results into a long data frame.
final_data <- as.data.frame(state_matrix) |>
rownames_to_column(var = "patient_id") |>
pivot_longer(
cols = -patient_id,
names_to = "time",
values_to = "state"
) |>
mutate(
patient_id = as.integer(patient_id),
time = as.integer(time)
) |>
left_join(X_base |> rename(yprev_initial = yprev), by = "patient_id") |>
arrange(patient_id, time) |>
group_by(patient_id) |>
mutate(yprev = lag(state)) |>
ungroup()
# e. Save the final data to a Parquet file.
file_name <- sprintf("simulation_x_effect_%.1f.parquet", current_x_effect)
write_parquet(final_data, file_name)
cat(paste0("Saved data to '", file_name, "'\n\n"))
}
cat("--- All simulations complete. ---\n")
Simulations
Setup
library(arrow)
library(tidyverse)
library(furrr)
library(glue)
library(fs)
library(here)
library(VGAM)
source(here("functions", "jackknife_mcse.R"))
source(here("functions", "check-completed-simulations.R"))
source(here("functions", "bayes-hosp-run-markov-simulation-iteration.R"))
Simulation function
run_simulation_iteration <- function(iter_num, base_path, full_data, model_formula, constraint = NULL, cumulative_arg, seed = 123, sample_size = 250) {
# This function runs one full simulation iteration.
# --- 1. Setup for the current iteration ---
set.seed(seed + iter_num)
# allocation ratio currently harccoded
tx_ids <- full_data |>
distinct(id) |>
pull(id) |> sample(round(0.5* sample_size), replace = FALSE)
soc_ids <- full_data |>
distinct(id) |>
pull(id) |>
setdiff(tx_ids) |>
sample(round(0.5* sample_size), replace = FALSE)
data_for_model <- full_data |>
filter(id %in% c(tx_ids, soc_ids)) |>
mutate(
tx = if_else(id %in% tx_ids, "1", "0"),
tx = factor(tx, levels = c(0, 1)))
rm(full_data)
if (nrow(data_for_model) > 0) {
model <- tryCatch({
vglm(
model_formula,
cumulative_arg,
constraint = constraint,
data = data_for_model)
}, error = function(e) {
message(glue("ERROR in iteration {iter_num}: {e$message}"))
return(NULL)
})
# --- 7. Save the results ONLY if the model ran successfully ---
if (!is.null(model)) {
summary_df <- summary(model)@coef3 |> data.frame() |>
rownames_to_column("term")
return(summary_df)
}
}
return(NULL)
}
Sim Specs
N_SIMULATIONS <- 1000
N_CORES <- 8
future::plan(future.callr::callr, workers = N_CORES)
Run Simulations
OUTPUT_PATH <- here("9-markov-tests", "output")
DATA_PATH <- here("9-markov-tests", "data")
effect_sizes <- seq(-4.0, 4.0, by = 0.5)
# define model specs
main_formula <- ordered(y) ~ tx + time + yprev
cumulative_formula <- cumulative(reverse = TRUE, parallel = TRUE)
# Loop through each effect size, load the corresponding data, and run the simulation
for (effect in effect_sizes) {
effect_str <- sprintf("%.1f", effect)
message(glue("\n--- Running simulation for x_effect = {effect_str} ---\n"))
INPUT_FILE <- path(DATA_PATH, glue("simulation_x_effect_{effect_str}.parquet"))
RESULTS_FILE <- path(OUTPUT_PATH, glue("results_{effect_str}.parquet"))
df_full <- read_parquet(INPUT_FILE) |>
filter(time > 0) |>
filter(yprev != 5) |> #df is with death carried forward, which we need to remove
rename(
id = patient_id,
y = state) |>
mutate(
y = factor(y, ordered = TRUE, levels = 1:5),
yprev = factor(yprev, ordered = FALSE)
)
# --- Run Simulations in Parallel ---
results <- furrr::future_map_dfr(
.x = 1:N_SIMULATIONS,
.f = ~ run_simulation_iteration(
iter_num = .x,
full_data = df_full,
model_formula = main_formula,
cumulative_arg = cumulative_formula,
sample_size = 250,
seed = 123
),
.options = furrr_options(seed = TRUE),
.progress = TRUE,
.id = "iter"
)
write_parquet(results, RESULTS_FILE)
}
Summarise simulations results
result_files <- fs::dir_ls(OUTPUT_PATH, glob = "*.parquet")
process_simulation_results <- function(file_path) {
filename <- fs::path_file(file_path)
# Extract the omitted covariate's effect strength from the filename
x_effect_strength <- as.numeric(stringr::str_extract(filename, "-?\\d+\\.\\d+"))
# Read simulation data for the treatment term
sim_data <- arrow::read_parquet(file_path) |>
filter(term == "tx1")
# Calculate Type I error and its MCSE
type_i_indicators <- sim_data |> pull(`Pr...z..`) < 0.05
type_i_error_rate <- mean(type_i_indicators, na.rm = TRUE)
type_i_error_mcse <- jackknife_mcse(estimates = type_i_indicators)
# Calculate Bias and its MCSE (true effect is 0)
estimates <- sim_data |> pull(Estimate)
bias <- mean(estimates, na.rm = TRUE)
bias_mcse <- jackknife_mcse(estimates = estimates)
# Return a tibble with formatted columns
tibble::tibble(
`X Effect Strength` = x_effect_strength,
`Sample Size` = 250,
`Type I Error (MCSE)` = sprintf("%.3f (%.3f)", type_i_error_rate, type_i_error_mcse),
`Bias (MCSE)` = sprintf("%.3f (%.3f)", bias, bias_mcse),
`Simulations` = nrow(sim_data)
)
}
summary_table <- purrr::map_dfr(result_files, process_simulation_results) |>
arrange(`X Effect Strength`)
knitr::kable(
summary_table,
caption = "Comparison of Type I Error and Bias for Varying Strengths of an Omitted Covariate"
)
Table: Comparison of Type I Error and Bias for Varying Strengths of an Omitted Covariate
| X Effect Strength |
Sample Size |
Type I Error (MCSE) |
Bias (MCSE) |
Simulations |
| -4.0 |
250 |
0.121 (0.010) |
0.001 (0.005) |
1000 |
| -3.5 |
250 |
0.121 (0.010) |
-0.001 (0.005) |
1000 |
| -3.0 |
250 |
0.133 (0.011) |
-0.003 (0.005) |
1000 |
| -2.5 |
250 |
0.116 (0.010) |
0.002 (0.004) |
1000 |
| -2.0 |
250 |
0.133 (0.011) |
-0.000 (0.004) |
1000 |
| -1.5 |
250 |
0.128 (0.011) |
-0.003 (0.004) |
1000 |
| -1.0 |
250 |
0.124 (0.010) |
-0.004 (0.004) |
1000 |
| -0.5 |
250 |
0.078 (0.008) |
-0.003 (0.003) |
1000 |
| 0.0 |
250 |
0.053 (0.007) |
0.010 (0.003) |
1000 |
| 0.5 |
250 |
0.103 (0.010) |
0.004 (0.003) |
1000 |
| 1.0 |
250 |
0.118 (0.010) |
0.003 (0.004) |
1000 |
| 1.5 |
250 |
0.133 (0.011) |
0.002 (0.004) |
1000 |
| 2.0 |
250 |
0.112 (0.010) |
0.004 (0.004) |
1000 |
| 2.5 |
250 |
0.130 (0.011) |
0.005 (0.004) |
1000 |
| 3.0 |
250 |
0.123 (0.010) |
-0.001 (0.004) |
1000 |
| 3.5 |
250 |
0.131 (0.011) |
-0.000 (0.005) |
1000 |
| 4.0 |
250 |
0.137 (0.011) |
0.001 (0.005) |
1000 |
So (if my code is correct) bias does not seem to be the issue, but probably SEs that are too small.
I’ll try to investigate whether random intercepts improve things, probably with the ordinal package (?). Will also try to obtain some robust SEs with the ordinal package.
It would probably also be interesting to look at the range between -1.5 and 1.5 logodds for the omitted covariate with a bit more granularity and more iterations. Seems like a range where most of the action is going on. I’m also interested in whether having no absorbing state changes things (I don’t see why it should).
Totally agree. Anecdotally, I ran some quick comparisons with negative binomial regression with days outside hospital with survival time as logoffset, and this was overly conservative. But nothing systematic so far. I hope to do more comparisons.
Edit: Just realized that as everything is proportional, I could just use rms for easy robust SEs. But will try to get it to work from VGAM as well, because I want to do some simulations with some constrained nonPO as well.