Hi all,
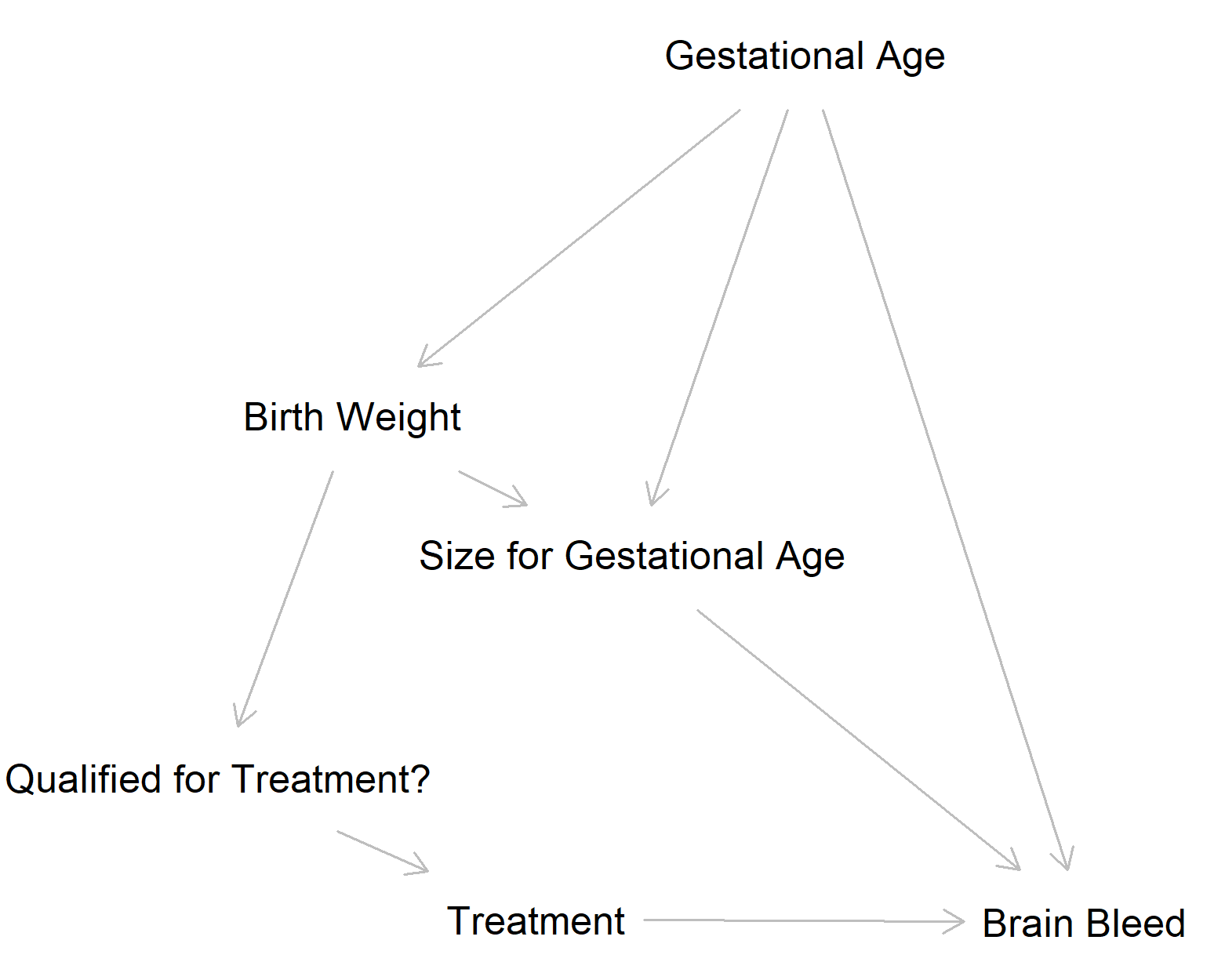
I’m working on a retrospective analysis to determine whether a drug reduces the prevalence of brain bleeds among very premature babies in the NICU. Babies were supposed to receive treatment if they weighed less than 1000 g at birth, but this protocol was not always followed (and I’m not sure why). Based on previous literature, I would expect that I would need to adjust for the effect of gestational age at birth (i.e. level of prematurity) and relative size at birth. Although birth weight is often considered a good predictor of outcomes, it is often a proxy for gestational age – more premature babies weigh less—and what really matters is relative size (e.g. smaller than average for a given gestational age). I analyzed these data using an ordinal regression since brain bleeds are scored from 0 (no bleeding) to 4 (profound bleeding in both hemispheres). After creating a DAG, I decided to include treatment, gestational age, and Fenton Birth Weight Z Score (relative size for level of prematurity) as predictors: lrm(data = d, brain_bleed ~ treatment + gestational_age + birth_weight_z).
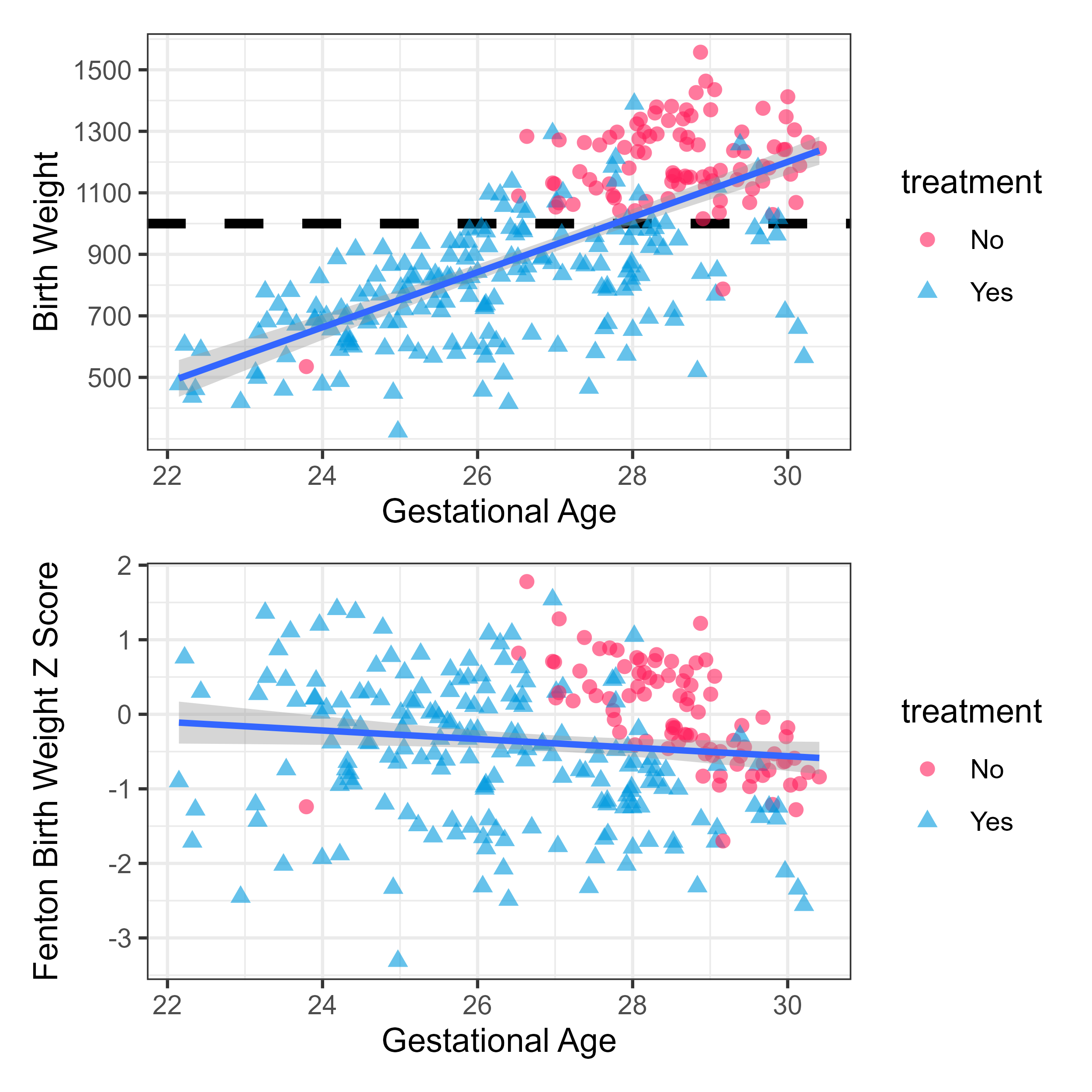
Below is a modified version of the data showing the relationship between gestational age, birth weight, and treatment. You can see that only two individuals born below 1000 g did not received treatment, but many above 1000 g did get treatment. Also, there are only a couple of babies born before 27 weeks who did not receive the treatment, so most of the variability in treatment is occurring in the top right corner. Despite these limitations, I through my approach was a decent way to determine the evidence for the effectiveness of treatment.
A statistician colleague said that I need to remove all babies born below 1000 grams and failing to do so would make this study difficult to publish. My recollection of their rationale is that because all babies born < 1000 g were supposed to get the treatment (and the vast majority did), it does not make sense to include those patients as they would skew the comparison. I think that excluding patients is a bad idea since it would severely reduce the sample size while removing the majority of patients with brain bleeds. Additionally, birth weight is not a factor that needed to be controlled for according to the DAG, so I’m not sure why it would need to be taken into account in the analysis.
Is removing patients < 1000 g as bad of an idea as I think it is? Does the model/approach I used seem reasonable?