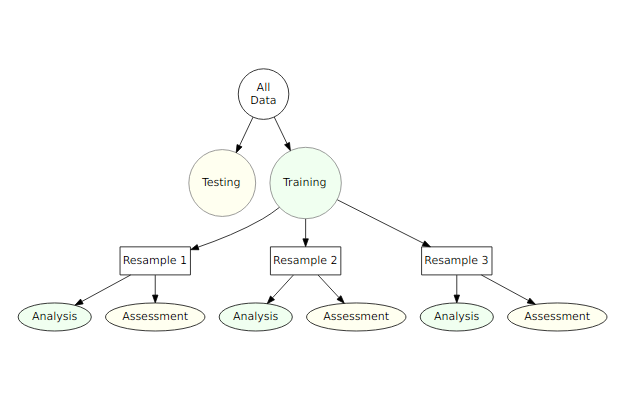
I’m learning the tidymodels suite of R packages, and I have a question about splitting and resampling. From the {rsample} docs:
A typical scheme for splitting the data when developing a predictive model is to create an initial split of the data into a training and test set. If resampling is used, it is executed on the training set. A series of binary splits is created. In rsample , we use the term analysis set for the data that are used to fit the model and the assessment set is used to compute performance:
In this approach, nesting resampling makes a lot of sense to me as a way to avoid optimization bias. You take the average of the assessment sets to tune the final model.
But with this approach, the final model is evaluated against the original testing split, which is just one split of all possible testing/training splits. Is the approach shown in the diagram preferable to not splitting and just using resampling to validate the test set? I think @f2harrell is arguing here for not splitting, but I’m not sure.
Maybe this method works, but it seems quite laborious to do such a double split with resamples and perform development and validation in all splits when just bootstrapping/resampling can do the trick. Also, as you are now doing double splitting the issues in the linked article are probably exacerbated. For example, you are now left with even smaller samples to develop your model in (as data are split twice leaving a quarter of the original sample size instead of half).
I cannot help with the R package since I have been stubbornly putting off learning tidymodels.
The following papers, especially Harrell, Lee, and Mark 1996, should shed some light on the values of bootstrapping over cross-validation.
Efron has shown that cross-validation is relatively inefficient due to high variation of accuracy
estimates when the entire validation process is repeated (and data splitting is much worse).[1]
Bootstrapping has been recommended over cross-validation because it provides nearly unbiased estimates of predictive accuracy that are (relatively) low in variance and with fewer models fits required than cross-validation.
In Harrell, Lee, and Mark’s 1996 Biostatistics Tutorial in Statistics in Medicine [2] they state: “Bootstrapping has an additional advantage that the entire dataset is used for model development. As others have shown, data are too precious to waste. [3-4]”