Another quick doubt, this is the result of anova(fit) from a Cox model with interactions.
I have used a non-linear interaction between the effect of treatment and year.
How should I interpret and report these pvalues?
Is it significant or not?
treat * year (Factor+Higher Order Factors) 5.42 2 0.0665
Nonlinear 4.70 1 0.0301
Nonlinear Interaction : f(A,B) vs. AB 4.70 1 0.0301
You have mild evidence against the presupposition that the treatment effect is constant over time. But rely on confidence intervals no matter what the p-value. Type ?contrast.rms to see examples of how to plot the treatment effect over time using the rms package contrast function. This will look something like:
Yes, I’ve already seen that the contrast function is fabulous. That’s what I like most about rms (also splines). Together with ggplot you can draw very cool graphics. But don’t you like interaction tests in general or just applied to continuous variables such as year? Do you think it makes sense to include them together with contrasts or not?
Sorry, the question is whether you have general objections to interaction tests to evaluate whether the hazard ratio of a therapeutic effect along two levels of a factor is similar or not. For example, right now it appears to me that the effect of DCF in intestinal tumors has hazard ratio 0.80, in diffuse 0.91. The interaction test (associated to the term treat*histology) is not significant. In this case, I also have to rely only on the confidence intervals, or the interaction tests do have value here.
It’s actually a tricky question because the power of interaction tests is low. We tend to trust interaction tests only when they are “significant” which creates a selection/publication bias. The Bayesian approach of the interaction “half in and half out of the model” is much needed. In the frequentist paradigm I would focus on confidence bands for interaction effects (double differences). In your case the interaction test does have a little indirect value—you’re able to say that with the present information/sample size you were unable to contradict the supposition of constant treatment effect.
I apologize in advance to Professor Harrell for my enthusiasm.
I have made my first attempt at Bayesian subgroup analysis and I think it is precious, but let’s see if it is correct.
According to a meta-analysis, the effect of docetaxel on OS is: HR 0.86 (95% CI 0.78 to 0.95).
In our observational study, we found HR 0.84 (95% CI, 0.71-0.99).
However, no one has evaluated the effect in subgroups defined according to histology, and they are really different pathologies that do not have to respond the same. This is of great clinical importance because we are talking about a very toxic therapy, which perhaps not everyone requires.
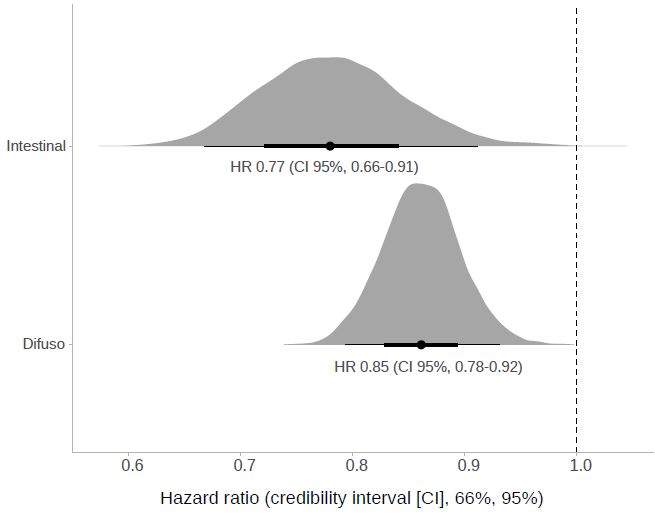
When we evaluate the effect in intestinal histology we get a HR of 0.68 (95% CI, 0.51-0.90), compared to HR of 0.89 (95% CI, 0.91-1.09) in diffuse subtype. However, the interaction test is not significant, p=0.13.
I suppose the usual thing would be to recognize that we have no evidence to say that the therapeutic effect is different in each pathology.
What does Bayesian analysis suggest in this case?
What I have done is feed the model with the prior of Wagner’s meta-analysis assuming that the effect is similar in both subgroups, and I have used a weakly informative prior for the interaction, allowing for some changes. The intervals I get are very similar to the previous ones.
However, what comes out is that the posterior probability of a clinically substantial result (e.g., increase OS >30%) is 70% for the intestinal subtype, but only 6% for the diffuse subtype. When I analyze the posterior probability density for the term treatment*histology interaction, only 19% of the probability mass is within the ROPE, then most likely there is an interaction after all.
Graphs are also awesome.
Is this reasonable?
I hope someone will answer this. In the meantime, if the observational study has a bias in estimating an overall treatment effect, it will not be able to estimate covariate-specific treatment effects.
That’s what I get for writing too long. I’m sorry for importuning… There doesn’t seem to be any bias. Our result is similar to the available meta-analysis (HR 0.84 vs 0.86).
But, a quick, total neophyte doubt about Bayesian interaction terms. Imagine that I make a Bayesian survival model such as: OS ~ a + a*b, where a and b are two dummie variables that can be 0 or 1.
I want to interpret the coefficient of a*b with a Bayesian approach.
Is it a good practice to use the posterior probability density for the coefficient of a*b to decide if there is substantial interaction? For example, could I evaluate the probability that the coefficient is outside the region of practical equivalence (ROPE 0+/- 10%) and decide on the subgroup effect according to this criterion? Thanks.
You can compute the posterior probability that the absolute value of the interaction parameter exceeds some threshold. Or just make the right covariate-dependent treatment contrasts whether the interaction is impressive or not, since you have already committed to putting the interaction term in the Bayesian model.
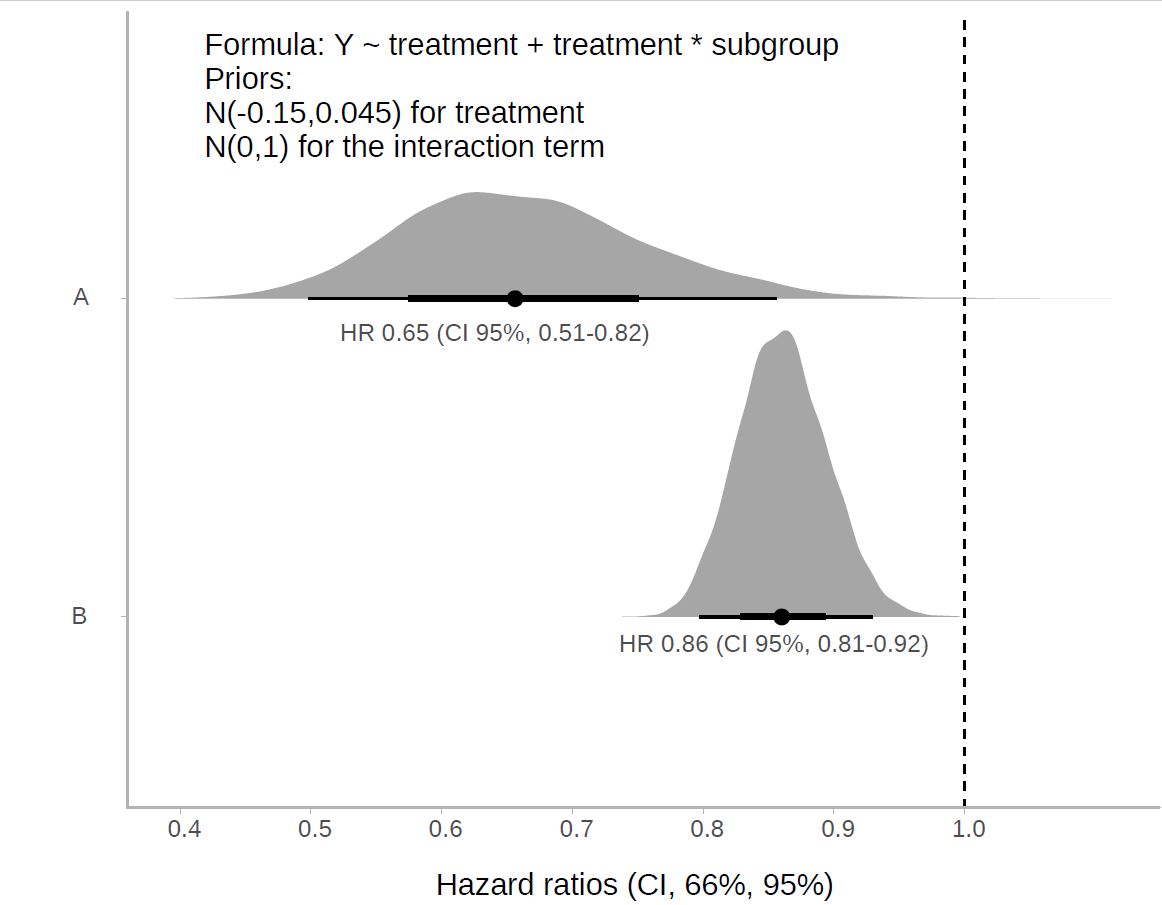
I think one relevant aspect is that there are many subtleties in the choice of priors with interactions. For example, if I use an informative prior for a, for example N(-0.15,0,045) and a weakly informative prior for the interaction a*b, such as N(0,1), the problem is that I am not assuming the same prior for a as a function of each of the b levels.
This could condition the result if 1-a is evaluated instead of a. The question would be what priors do I have to use for interaction terms to assume that both levels of a are under the same prior?
I would think of this as what prior represents the range and relative probabilities of differential treatment effects. The interaction prior induces a correlation between the knowledge of x-specific treatment effects where x is the interacting factor. I would tend to use a skeptical prior for the treatment effect in the reference level of x, and an even more skeptical prior for the double differences.
The formula is simplified, the model is much more complex.
For the interaction I used what Andrew Gelman calls in his blog a generic weakly informative prior: normal(0, 1)…
You now suggest that I should use a prior more skeptical than normal (0,1) for the interaction term.
I think it would be reasonable to consider normal (0,0.1). On the other hand, an even more skeptical prior, such as normal (0,0.05) might suppose to assume too much, for example, to assume that I already know that the modification of the effect is going to be very tiny, when in fact this is not clear.
Isn’t it a little subjective? How do I defend normal(0,0.1) against any other option? Does that seem reasonable to you?
I like your way of thinking. I would just change the metric for choosing the prior from variance to the probability that the differential effect exceeds some meaningful level, and solve for the variance that gives you that probability.
I’ve been trying that. What I thought was to use the meta-analysis main effect estimate as prior when the interaction was null. Then I did what you said, selecting the prior for the interaction term based on plausible values from previous individual studies within the meta-analysis rather than variance. The result better reflects previous knowledge. However, I have realized how important it is to be rigorous, not only in the choice of prior, as it conditions the outcome, but in the interpretation of posterior bayesian results, which are largely due to our decisions. Notice the change with the previous result.