Any recommendations on methods/papers that provide guidance on using weights for a primary composite outcome for a time to event analysis. Such that the weights reflect severity of the endpoint (hospitalization vs. AMI vs. death). Also, are their methods like the joint frailty models that would account for weights and repeated events.
Appreciate any example RCT studies that did this or recommended methods papers on the topic.
I found this paper interesting, but it basically just translates all endpoints into DALYs:
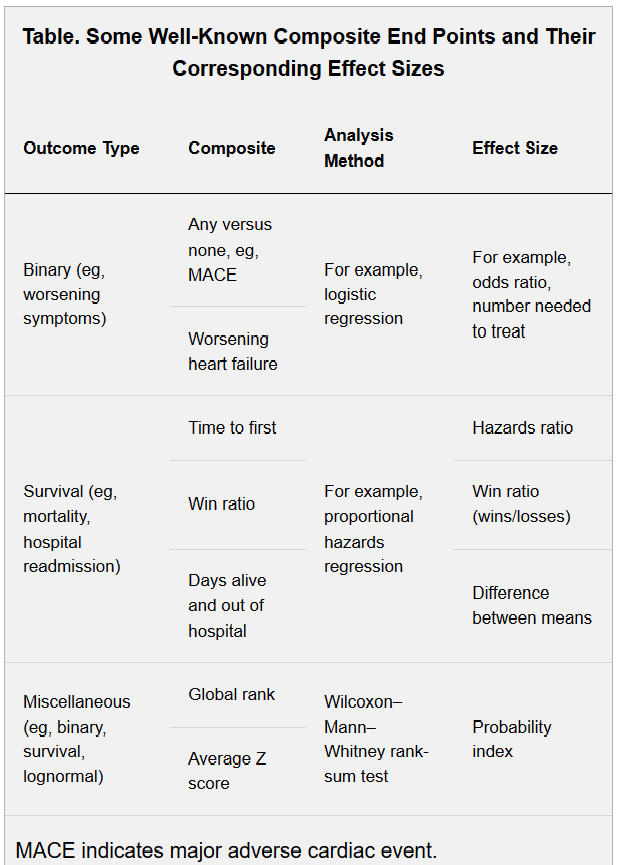
I’m collecting papers on multiple endpoints in RCTs here. In the special case that you are interested in only the time of the first event and the severity of that event, there is one elegant solution here.
@f2harrell listed the two papers i would have mentioned ie the Bakal & Armstrong paper, and pocock’s win-ratio. Just yesterday I reviewed a paper on the topic. I believe it’s open review so my comments will eventually appear somewhere. I have certain opinions about it. I don’t like the Bakal & Armstrong approach; I find it ironic that while we are expressing concern over reproducibility we watch researchers nominate ad hoc, arbitrarily consructed endpoints as the primary outcome of their study.
one issue is that the relative importance weights are often inversely related to incidence eg death. Thus you lean on the weakest outcomes (which makes sense if like Felker & Maisel you are trying to make phase II results look more like phase III results). But power can then become inadvertently sensitive to study duration which is dictated by extraneous factors (we showed this graphically here: Influence).
an interim reassessment of power is surely prudent because composites have so many moving parts. But that presents another problem: someone mentioned this nejm paper on twitter where they did an interim analysis: nejm paper My contention would be that you are not testing the same hypothesis at the interim analysis and study completing, because the Influence of the component outcomes varies across the study period
Re “joint frailty models that account for weight and repeat events”, we did something (Brown & Ezekowitz, among @f2harrell 's list) but weights then become unnecessary because you are not amalgamating outcomes, that’s one of the advantages i see. I cannot see that multivariate modelling will not overtake composites, eventually; complexity usualy wins in the end but simplicity is so compelling.
Are there models where you may model the time to worst event for a composite? So that the most severe event by patient is recorded and weighted higher. Does that make sense?
Currently, if we have a MACE outcome and someone has a small MI but then dies, we ignore the death in the composite. I guess the reporting of secondary outcomes usually covers this issue.
edit: actually, what are you imagining your estimand will look like? because the win-ratio produces a win-rato estimate… not a hazards ratio and you sound interested in time-to-events (although MACE is binary). If you dont want to lose time-to-event, you could do eg a multitype recurrent events analysis ?
Oh, haha yea, the win-ratio basically does what I was asking.
Definitely multiple events would probably be preferred. I was curious about time to most serious event, but unless it’s weighted appropriately there would seem to be strange biases that could come into it.
For time to an event jointly modeled with severity of that same event, see this paper.
I don’t find the win ratio particularly easy to interpret, and have problems with the version of it that excludes data. I’m hoping that a longitudinal ordinal analysis will be a useful option.