yes, that’s what im suggesting. I tried to promote this by recommedning the prob index for all components and then overall composite and then displaying this a forest plot in the way of a meta-analysis, see the figure in this paper: effect size it’s also then possible to visually assess heterogeneity. but i worry such a summary would generate a lot of discussion rather than appease. I dont think it encourages predicting benefit from covariates, it’s likely to generate ambivalence. im secretly trying to undermine composites by recommending displays that betray their inherent problems
i received a phone call saying i was in contact with someone who had corona and i must self isolate. i had all the symptoms, headache, sore throat, shortness of breath etc. i went for the test and it was negative. nocebo effect i guess. that is a partial reason. the bigger reason is that it’s not explicit, that’s all i really have a problem with. I worry all people hear is: “we used a composite of hospitalisation and some other things” and there was an effect, but maybe 10% of the admissions data have contributed to that result, but people read the abstract only, and it moves as away from estimation putting more emphasis on significance testing. we were told as undergrads that estimation is key
enjoying the discussion, cheers
1 Like
Combining the measured features with subjective features converted into numbers to generate a function may or may not be reproducible.
Referring to critical care data, we are replete with objective numbers but there is also the conversion of subjective data (e.g. pain, sedation, coma scale) into ordinal scales. Dyspnea is like pain, very subjective.
Some subjective scales are considered fairly strong for example, the glasgow coma scale (GCS). Others are are considered weak (dyspnea and pain). Reproducibility is the key. I loved the characterization made by Robert Ryley, asking the question…does the feature (as rendered) rise to the statistical level? If it does not it cannot be used.
Consensus itself is a subjective term which does not necessarily convert a feature into something that rises to the statistical level. Consensus may be driven by the alpha male or, now that they are allowed (at long last), the alpha female in the group or affected by the general bias of the group. The use of tools like the Delphi method to deal with the alpha problem does not solve many of the other problems.
The SOFA score is a classic case. It is a perceived “function” which is comprised of the sum of 6 ordinal threshold based values derived from one man or from consensus (who knows) and essentially unchanged for 24 years. The question here is not whether the tool is useful clinically but rather does it rise to the statistical level to be used as a independent variable or a primary or secondary endpoint in RCT.
Here the issue of weights is pivotal. Presently there are no weights responsive to the physiologic systems. The 6 values are from 6 physiologic systems and unlike all people, physiologic systems are not created equal when it comes to mortality risk. Now I pointed out that problem before in this forum. This means the the same score can result in markedly different mortality depending on the perturbed system mix. This means that if the SOFA score is applied as an endpoint in an RCT for a multisystem condition with a typically protean progressive propensity, SOFA will not rise to the statistical level, because it will not render reproducible results as its output is dependent on which physiologic system distortion dominates in each cohort.
Could that be improved with weights determined using a massive dataset optimizing for mortality. Of course, but the weights might still be dependent on the disease mix. The data set (6 static values) is likely a fragment too small.
Here we might ask what rises to the statistical level for “sepsis”. How about a value of the WBC (by itself)? No, that is too small to rise to the statistical level by itself. The WBC is never the only value available so it would always be wrong to interpret its meaning by itself.
I think that is the question to ask. “Does this measure rise to the statistical level?” If there is no evidence that it does then the team may be engaged but can be simply performing another study which renders clicks, and perhaps tenure, but can be thrown on the heap of past studies which do not contribute to the advancement of knowledge in the field, and worse, distracts the young.
4 Likes
Apologies if what I’m about to say doesn’t make sense-I don’t know anything about “machine learning.” I get the impression that your research uses sophisticated computerized methods to examine how constellations of various physiologic markers change in sepsis patients over time (including which constellations tend to predict death)? Presumably, the reason why this is important is that it’s plausible (and even likely?) that certain therapies will only work if administered at a certain point in a septic patient’s clinical trajectory (?) And if the patients enrolled in a given sepsis trial are all at very different points in their clinical trajectory when they receive the treatment being tested, then only a small subset might stand any chance of responding to the therapy (?) In turn, the trial will stand no chance of identifying the therapy’s intrinsic efficacy(?)
So to summarize, what you’d really like to see is statisticians challenge the prevailing view among clinician researchers that SOFA scores are a sufficiently granular tool for identifying patients who are at similar points in their clinical trajectory (?)
Partially. You are correct. Unlike acute coronary syndrome or stroke, patients with “sepsis” arrive at different points along the continuum and there is no way to determine when the condition started. Furthermore the source of the infection, the organism and other factors affect the trajectory. Necrotising fasciitis due to group A streptococcus (GAS) can kill very rapidly as GAS is a human predator which does not often infect animals in nature. We are its protein source and it converts our proteins into weapons. Candida on the other hand lives with us but upon entering the blood can lead to death. The trajectories of these are different. The perturbations may be different.
For example we were reviewing GAS necrotising fasciitis cases today. Most did not have a platelet fall. We need to determine if that is true for a large cohort. If it is SOFA, which uses platelet thresholds as part of its sum will likely be lower in GAS necrotising fasciitis even though the patient is rapidly dying. Failure to include sufficient alternative markers of mortality means that the mortality is not reproducible. It’s like assessing the lethal power of an army by quantifying tanks, troops, and missiles and missing helicopters. With some armies it would work but its not a suitable metric for all armies because it is incomplete.
For example This is a case of profound pneumococcal sepsis yet the platelet count does not fall. (these data are open access from Mimic database)
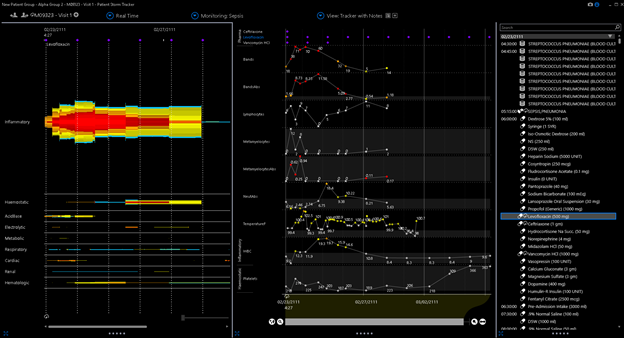
The other problem is the thresholds used to derive the ordinal scale is static. The first point of 1 is obtained at a threshold of 150. Here is an image of profound sepsis due to bowel perforation. Note the platelet fall never reaches the SOFA threshold of 150.
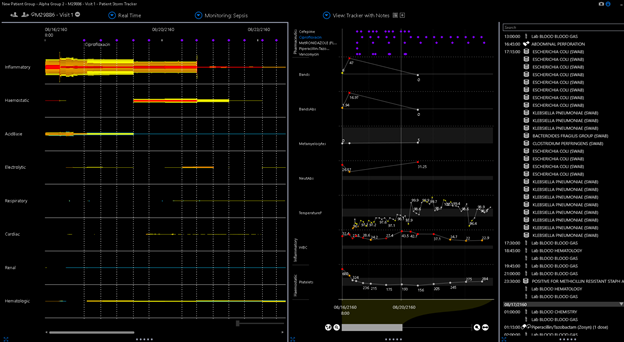
Here is GAS bacteremia.
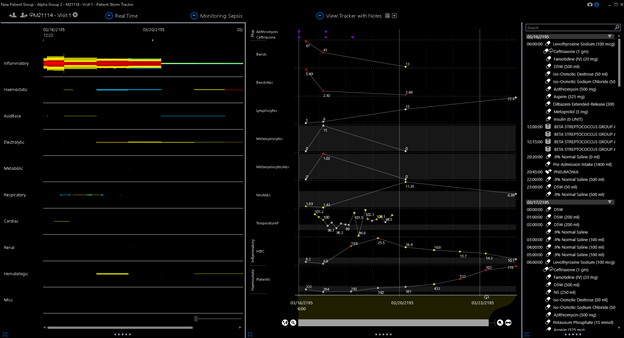
Now in the these cases there were other extant markers for mortality which were not captured by SOFA and in the second case the platelet fall was significant (but not captured by the 150 cutoff of SOFA). Now the platelet count commonly does fall in a large percentage of cases so that’s probably why they chose it but its the mix which will then trip the reproducibility up.
So an ordinal measure is incomplete if there is a lack of validated weights, capricious cutoffs, too few signals, and SOFA meets all those limitations. Such a measure does not rise to the statistical level for broad application in sepsis RCT no matter how many people advocate its use.
I would welcome those in this forum who discussed at length the statistical outputs Citrus-ALI post which used SOFA and an endpoint. A deep debate would be very helpful to advance sepsis science which has been so plagued by non reproducibility that the NIH representative at the recent SCCM questioned whether further funding was warranted until we better understand the condition. Do you support or use the SOFA score in RCT? Will you use it if the PI says she wants to use it? If so, please bring debate. It’s the best way for all of us to learn.
4 Likes
Great discussion. One angle that is missing is quantification of the extent to which scores such as SOFA approximate the “right” score, and the fact that often what happens in clinical trials is that trial leadership replaces a flawed outcome measure with an even more flawed one such as a binary event of the union of a series of binary events, failing to distinguish differing severities of the component events.
1 Like
Displays that exhibit inherent problems with composite endpoints have more do to with exposing the inadequacy of the study’s sample size than anything else. If you want to be able to provide efficacy evidence about components of a composite outcome you need much bigger sample sizes than we are willing to entertain. Short of that, IMHO we should put our energy in to deriving and checking the outcome measure, then stick with it, and definitely not by concentrating on simple statistics for low-power component omparisons.
Just as with meta-analysis we must use Bayesian borrowing across endpoints to make sense of the collection of component outcomes. For example you can put priors on partial proportional odds model components to control the heterogeneity of treatment effect across components, as described in the first link under https://hbiostat.org/proj/covid19.
[quote=“f2harrell, post:27, topic:3955, full:true”]
Short of that, IMHO we should put our energy in to deriving and checking the outcome measure, then stick with it, and definitely not by concentrating on simple statistics for low-power component comparisons.
Agree, In my view the key words of the quote being “deriving and checking” not “guessing and promulgating” that is all I am asking for. No guessed measurements from the 1990s for 2020 RCT.
1 Like
i wish i had more time to think about this, i will have to come back to it. i would just note that identifying sepsis in retrospective analysis seems just as challenging as it is in prospective analysis. i saw this recently: “In two recent papers, the same authors offered contradictory findings on the global incidence of sepsis, outcomes, and temporal changesover the last few decades.” from: Sepsis: the importance of an accurate final diagnosis i guess this is a good place for stato and clinician to work together
2 Likes
Yes the “sepsis” experiment of human science, which probably began in ernest in 1980s, may be THE most illustrative example of failed interaction of statisticians and clinicians.
The 1980s was a simple time. The era of threshold science, the era of the perceived near infalibility of ROC.
It was a time of heady early exuberance for the creation of “syndromes” with simple thresholds sets for RCT (with little or no knowledge of HTE).
In the 1990s the threshold sums (scores) became popular. Guessed by the experts of the time most persist as standards today and are widely used in RCT. When a new pandemic emerges they are there, for the RCT of 2020.
The promise was not fulfilled. Yet despite substantially no positive RCT reproducibilty no general call for reform or reform movement has emerged. The operation, statistics and ruminations of sepsis science is basically unchanged for 30 years as evident from the discussions (eg CITRUS-ali in this forum.
Sepsis is a leafing killer so the lack of a reform movement is one of the great tragedies of the 21st century.
Perhaps ML/AI will come to the rescue. Uneffected by the need to comply with the collective, a weakness shared by human statisticians and scientists. However. if surpervised learning is applied with the mandate to use the present standards (SOFA) for the training sets that will be render another cycle of failure.
Some courageous statistician has an opportunity now for an amazing story an amazing heart stopping review which will make a real difference. I hope she rises soon to be counted as the reformer the world needs.
2 Likes
Is that published anywhere?
No, I wish it were published.
I had to go back to this quote. It is so well stated. Furthermore, I would like to generate discussion of the aspects required of a valid measure that might result from that challenge.
I’ll suggest 3 aspects which I think are required.
- Includes ALL nonduplicative features (independent variables) which are signficantly predictive of mortality. (SOFA has no measure of myeloid signal perturbation so it will fail in cases where that independent variable is dominant).
- Does not include any independent variables which do not rise to the statistical level.
- Must be optimized using a formal method. (SOFA was guessed, like an input vector which was simply promulgated, and never optimized)
Here are a few questions for the group.
- Are these correct?
- What are the other aspects?
- Are there standard mathematical tests statisticians can apply to determine the validity/reproducibility of a measure used in an RCT?
- How might those tests be applied to SOFA or an alternative?
Maybe a blog post? It would be really great to read this.
The issues raised here and in related topics seem very pervasive and crop up all over the place. There is a plethora of these summary scores that are “clinically accepted” (a phrase that has become a red flag for me) as outcome measures but only questionably measure the true outcomes of interest, and have weird mathematical properties that are rarely understood. They are usually just treated as it they were continuous outcomes, which is rarely justified - for a start, it’s common for some scores to be impossible or rare.
Maybe we should try to insist on actual measurements of variables of interest - and use “primary outcomes” of a set of (probably) inter-related phsiological variables, and ditch the summary scores. Maybe?
Stephen Senn had a good journal article on this issue of measurement.
In rehabilitation science, I’m seeing an uncritical acceptance of psychometric procedures to “validate” clinical assessments. I’m having questions about the actual predictive validity of these in the typical clinic. Joel Michell has been making an argument on the ordinal nature of psychological constructs for a long time, with this paper being the best introduction to his outlook.
Similar, independent observations were noted by Norman Cliff, another psychometrician.
Cliff, N (1992) Article Commentary: Abstract Measurement Theory and the Revolution that Never Happened. Psychological Science.
https://journals.sagepub.com/doi/10.1111/j.1467-9280.1992.tb00024.x
Finally, I’ve always appreciated re-reading this paper by David Hand on the intersection of measurement theory with statistics:
Hand, D. (1996) Statistics and the Theory of Measurement Journal of the Royal Statistical Society
@llynn The problem of rating scales as outcome variables for RCTs was discussed in the context of neurology, with a good introduction to the complexities of using these scales in studies.
Hobbart, J; et al (2007) Rating scales as outcome measures for clinical trials in neurology: problems, solutions, and recommendations The Lancet Neurology, Volume 7, Issue 1, January 2008,
1 Like
Because of low power to look at individual components in some cases, and because with frequentest inference there are multiplicity problems, we are stuck with needing summary scores. Let’s construct them wisely.
1 Like
The articles linked below might be useful to include in this thread:
This one highlights historical problems with trials studying treatments for another complex “syndromal” illness- major depression. The overlap with the history of sepsis research seems striking: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6078483/. Have sepsis researchers ever collaborated with researchers studying other conditions that involve similar challenges (e.g., depression, chronic pain), with a view to sharing approaches/lessons learned?
These articles from a few years ago summarize the many devilish problems with sepsis research:
The “Phenotyping Clinical Syndromes” thread links to this article:
https://jamanetwork.com/journals/jama/fullarticle/2733996. The ensuing discussion highlights problems with “data-driven” approaches to identifying different sepsis phenotypes. The main criticism seems to be that humans can always identify patterns in chaos (especially now that we have computers to help). After identifying patterns, we then create categories for things. Unfortunately, the chance that these categories reflect underlying “truths” about the essential ways in which groups of things differ from each other, and that they can then be used to design reproducible clinical trials, seems low. To this end, maybe articles related to “cluster analysis” and “latent class analysis” (and their inherent problems) are also relevant (?):
https://www.thelancet.com/journals/landia/article/PIIS2213-8587(18)30124-4/fulltext
4 Likes
Very intriguing. The intersection of math disciplines appears to be a problem when one discipline is poorly defined (or poorly definable) with the extant math. Imagine if that was true at the intersection of the physical sciences and engineering science.
This is why the burden falls on the statisticians because clinicians are deriving VERY simple functions. Very little of clinical medicine is math.
With a little due dilligence, these simple functions are very easy for a statistician to understand and factor. I could teach them to a math undergrad student in 15 minutes. This is not true for the statisticians who are using complex math, substantially the the entire discipline being math.
So if a clinician researcher says she wants to use SOFA chances are, she does not know the function SOFA is intended (but fails) to render.
A statistician should not connect a perceived function as a measure in an RCT to statistical math without understanding the function’s derivation, behavior and reproducibility.
There was a improper joke I saw an internist play on a surgeon when I was student.
After taking a history and examining the patient he drew a line on a patient’s abdomen over the gall bladder and next to it he wrote “Cut Here”. Now, of course, no diligent surgeon would comply without her own investigation.
When applying statistics to a measurement like SOFA, statisticans are, without due diligence, dutifully “cutting here”.
Yes, thankyou. These are relavant articles. But note that the leaders have progressed to this level of understanding but still default to SOFA (a composite measurement guessed in 1996 when most of this heterogeneity and its effect on RCT was not appreciated).
SOFA (delta 2 points) was chosen as the new 2016 measurement defining sepsis using the Delphi method.
Now SOFA itself had been shown in a large data trial to be nonspecific for sepsis in 1998. In fact SOFA was so nonspecific, they changed the word defining “S” of the SOFA mnemonic from “sepsis-related” to “sequential” (See 1998 article not just abstract.)
However, the new 2016 sepsis definition required “suspician of infection” (ie a prior) plus delta 2 SOFA.
That meant that after 2016 SOFA was the input, and SOFA could still be used as an independent variable and SOFA could be the primary or secondary output. Like turtles, by 2016 it became SOFA all the way down for RCTs of mankind’s greatest historical killer.
The issue of phenotypes and cluster analysis is pivotal. As I said before, sepsis is a 1989 cognitive bucket filled with different diseases (can be called phenotypes) which look similar clinically but induce profound HTE.
Reading these articles it’s easy to say this is too complex, “I’m going with the consensus”. However, these articles do not lead one to beleive SOFA will work. In fact, to the contrary, for the knowledgable they teach away from that approach.
While none of these articles conclude SOFA would work, they are silent on what measure(s) to use. Rather there is a conclusion that the matter is complex AND maybe the “Delphi Method” can sort it out. Which is what was done and where SOFA was selected.
However complex all of that is, the SOFA itself is comprised of simple math and easy for the statistician to factor and understand.
That’s what we need; statisticians which will rise to the challenge and say, “I may dutifully use the consensus measure but I’m not going to do that without learning, and explaining to the PI, its limitations.”
![]()
Given the pandemic there is an urgency to consider another myth. See article in Chest a prestigious journal.


Comparison of Hospitalized Patients With ARDS Caused by COVID-19 and H1N1 -…
There were many differences in clinical presentations between patients with ARDS infected with either COVID-19 or H1N1. Compared with H1N1 patients, patients with COVID-19-induced ARDS had lower severity of illness scores at presentation and lower…
I would add to the myths the common view that the output of a threshold based function (for example a composite sum of scores) can be used as a measurement and incorporated into the statistical math of a observational study or RCT to render a valid, reproducible result without due consideration of the origin, derivation, reproducibility of the function itself as well as its applicability to the specific population under test.
(In the example of SOFA, which I discussed in another thread, the measurement is derived from 30 threshold levels of 6 measurements rendering 6 values which are added to produce the score upon which statistical math is applied to render a statistical output.)
Now watch how statisticians incorporate this “measurement” into a study.
“Patients with H1N1 had higher Sequential Organ Failure Assessment (SOFA) scores than patients with COVID-19 (P < .05).” … The in-hospital mortality of patients with COVID-19 was 28.8%, whereas that of patients with H1N1 was 34.7% (P = .483). SOFA score-adjusted mortality of H1N1 patients was significantly higher than that of COVID-19 patients, with a rate ratio of 2.009 (95% CI, 1.563-2.583; P < .001).
The “sofa score adjusted mortality” proves the saying “You can adjust for a baseline ham sandwich.”
Probabaly some trusted the adjusted stats here.
Joking aside. Andrew, I would welcome your respected input in the measurement thread about composite scores and SOFA…
1 Like