Dear Scholars,
I hope you all are well. I have a consultation with you all.
I am a Japanese psychiatrist currently studying at the University of New South Wales in Sydney. My specialty is brain stimulation therapy and I am currently doing a meta-analysis on relapse proportion after electroconvulsive therapy(ECT). And I am doing a proportion meta-analysis in Stata(using ‘metaprop’).
The cochrane handbook does not sufficiently mention proportional meta-analysis, so I wanted to discuss this with you in the hope that I could access the wisdom of the wise here.
Here are the questions
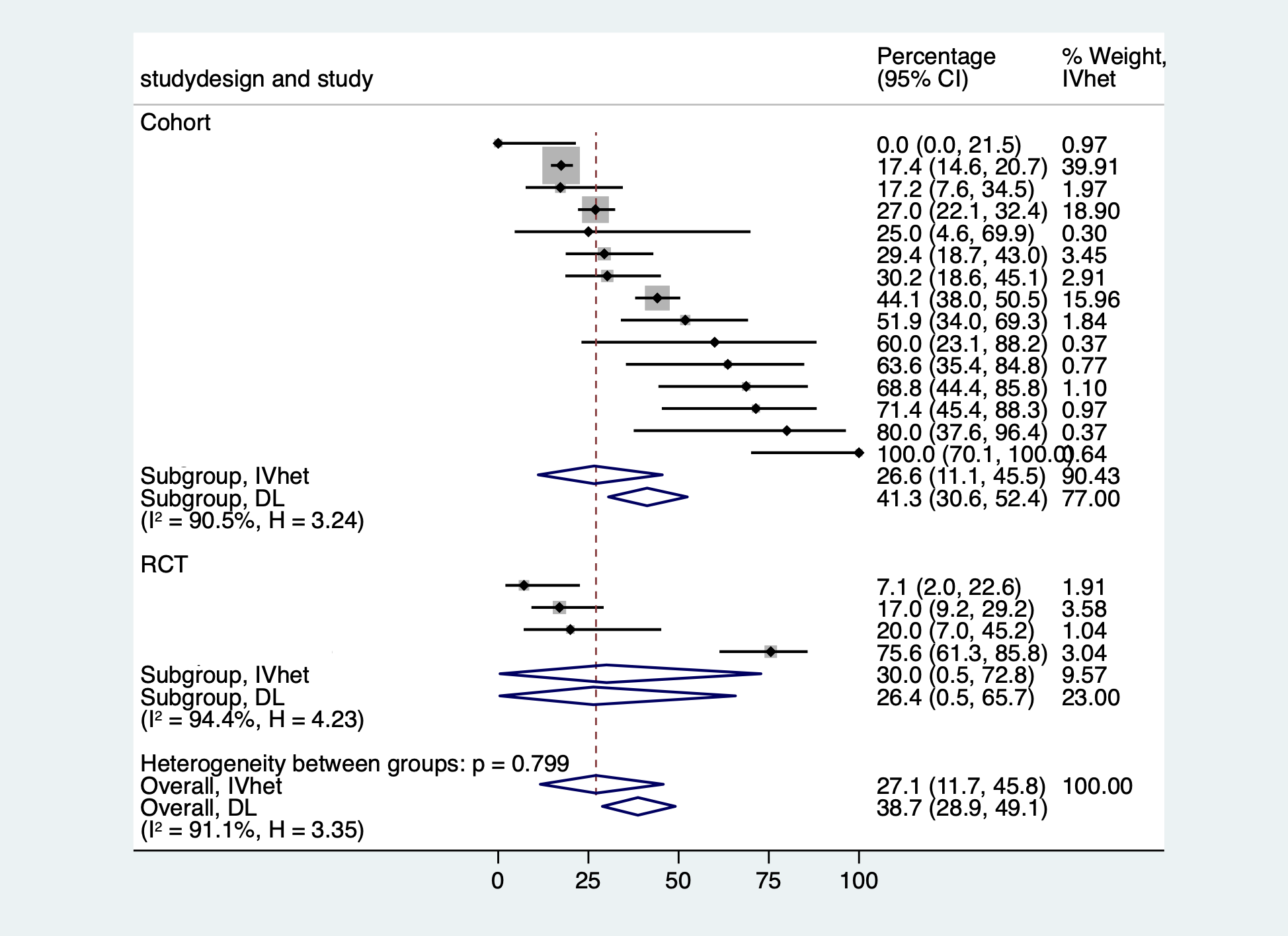
- In a subgroup analysis, I am having difficulty interpreting results where the 95 % CI is greater or lesser than 0 or 1. I understand that there is a large bias in this study because it included many cohort studies with small numbers of cases as well as RCTs, but I do not understand why the integrated results exceed 0 or 1.
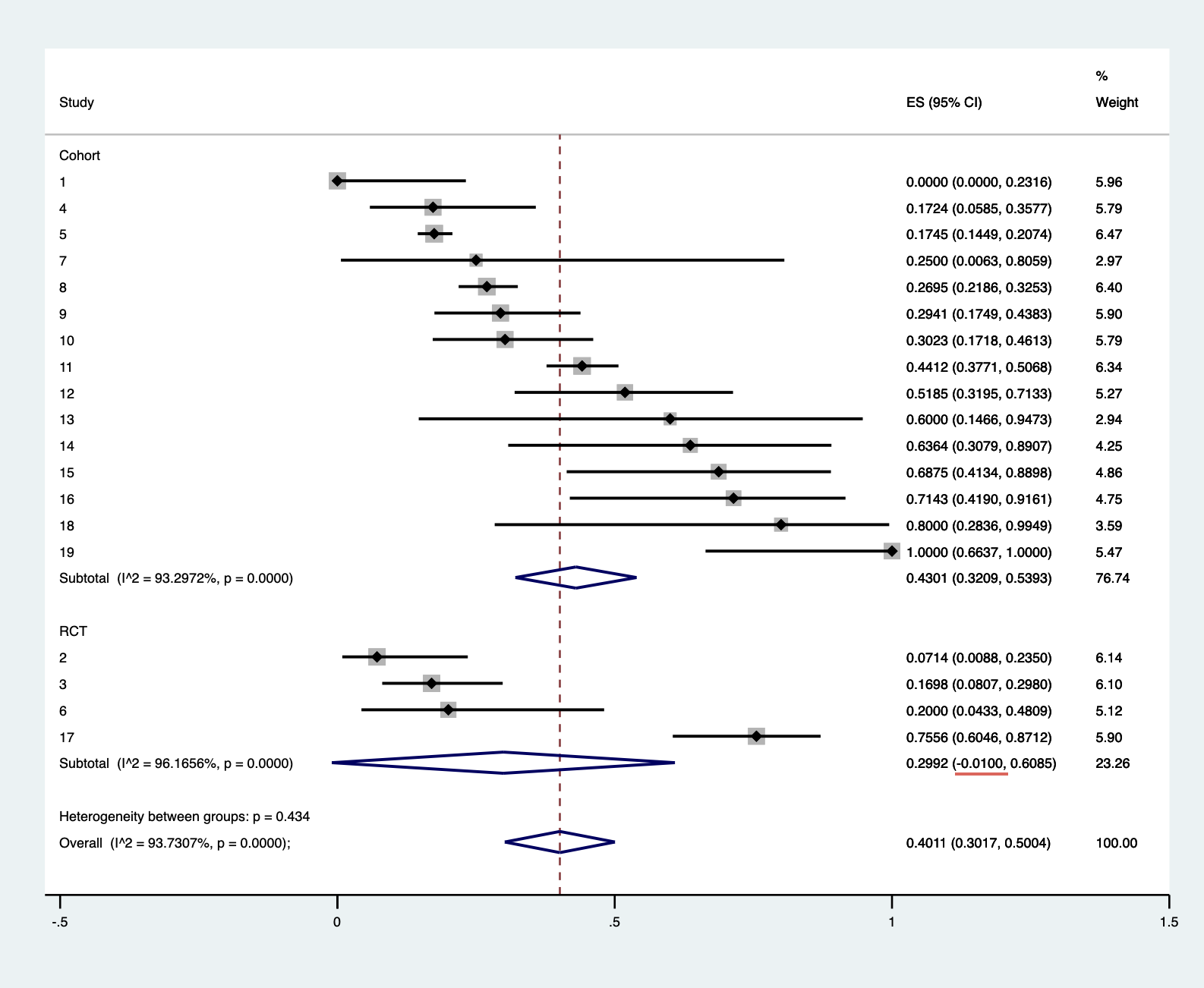
I would like to know if it is a problem that I am using Statat’s “metaprop”.
I have calculated the results using the following formula, based on the literature of Nyaga 2014 .
“Metaprop: a Stata command to perform meta-analysis of binomial data.” Archives of Public Health 72 (2014): 1-10.
metaprop case population, random by(studydesign) cc(1) dp(4) cimethod(exact) label(namevar=study) sortby(_ES)
xlab(0,.25,0.5,.75,1) xline(0, lcolor(black))
xtitle(Proportion,size(3)) nowt nostats
olineopt(lcolor(red) lpattern(shortdash))
diamopt(lcolor(red)) pointopt(msymbol(s)msize(2))
astext(70) texts(100)
- In proportional meta-analysis, there is no scale to assess heterogeneity and some papers do not report it or alternatively use I^2.
In this study, I refer to a proportional meta-analysis on the service life of the hip published in the Lancet.
Evans, J. 2019. How long does a hip replacement last? A systematic review and meta-analysis of case series and national registry reports with more than 15 years of follow-up. The Lancet , 393 (10172), pp.647-654.
This article did not report on heterogeneity (partly because it was a nation-wide study and had a large sample size), but ECT studies are characterised by few studies with sufficient samples, partly because of the difficulty in designing RCTs. In such cases, we would be grateful for your opinion on how meaningful it is to report heterogeneity and to perform meta regression.
It is possible to perform meta regression when using R. However, this was not recommended in the paper that mentioned proportional meta-analysis with R tools.
Wang, N. (2017). Conducting meta-analyses of proportions in R. Research Gate: College Station, TX, USA .
3.How meaningful is it to assess publication bias in proportional meta-analysis.If you use R, you can create a funnel plot, but the included studies are not comparative studies, but are created with results consisting of non-traditional binary data I would like to know if there is really any significance in a funnel plot.
This was also not recommended in the papers that mentioned proportional meta-analysis with the R tool.
Few previous proportional meta-analyses have reported funnel plots or meta-regression.
We would like to know if this is because there is not much significance to this as well.
I am truly sorry for submitting such a long question.
Thank you for reading the post, and I look forward to hearing from some scholars soon!
Kind regards,