Hello there,
I am developing a Fine-Gray competing risks prediction model for dementia incidence (with death as the competing event) using population-based survey data linked to administrative health records. My full model contains 76 candidate predictor terms, including restricted cubic spline transformations and interaction terms.
I am evaluating two approaches for model reduction to create a parsimonious model for clinical/public health use:
- Stepwise selection (particularly Ambler)
- Penalized regression / shrinkage (particularly LASSO)
Which of the two approaches above would be best recommended for my case? Or is there another approach which would be better?
Would appreciate any feedback!
Thanks,
Raf
Almost all researchers agree that stepwise selection is inappropriate. It can be ruled out from your list.
Professor Harrell would likely recommend using methods like principal component analysis; removing factors with weak or no association with your outcome is probably not a recommended approach. You can take a look at this (I am reading this recently too).
8 Case Study in Data Reduction – Regression Modeling Strategies
1 Like
Yes if there are many candidate predictors then unsupervised learning is a great first step.
Regarding the big picture, I don’t find prediction of AD that precedes death to be that meaningful. That’s what competing risk analysis does. I find it much more natural to use multi-state models. See [this](https://cran.r-project.org/web/packages/survival/vignettes/compete.pdf) amazing document by Therneau, Crowson, Atkinson.
Discrete time multistate models are even simpler.
[This survey](https://discourse.datamethods.org/t/clinical-trial-outcomes-interrupted-by-other-outcomes) revealed that most researchers find it impossible to really separate death from nonfatal outcomes anyway.
3 Likes
Hello everyone,
Thank you all for the feedback! Appreciated!
For unsupervised learning methods like principal component analysis, does it involve reducing the number of candidate variables before any model fitting?
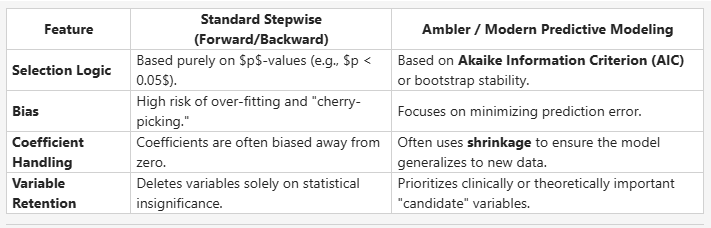
Also, I may have misclassified Ambler as pure stepwise earlier. My teammate said that the (Harrell-)Ambler method is not standard stepwise as it is categorized more as a selection procedure that emphasizes validation and shrinkage. Here are her comparison notes below:
Please let me know what you think.
Thanks again,
Raf
1 Like
Yes, as described here data reduction (unsupervised learning) involves reducing the number of variables to model in a way that is completely masked to Y. That way you don’t create model uncertainty / overfit, and interpretation can be enhanced by not trying to separate collinear variable. My favorite default method is sparse PCA for which there are two examples in those RMS notes. The one that is near the end of the ebook involves nonlinear sparse PCA.
Variable selection methods (other than ones based solely on subject matter knowledge), even when smartly using shrinkage as in lasso are unlikely to be stable and will miss important variables.
1 Like