A second scenario. Cancer patients routinely have lymph nodes removed during surgerey, but this often causes adverse effects. A model developed on a different data set is tested on a new cohort, with the results below. The model predicts the risk of positive nodes in a group of surgery patients, all of whom underwent lymph node dissection? Should the model be used to determine which patients should have lymph node dissection and which can be spared lymph node removal - and thus its attendant side effects?
Just to be sure, the model predicts the risk of lymph node involvement or the risk of adverse effects?
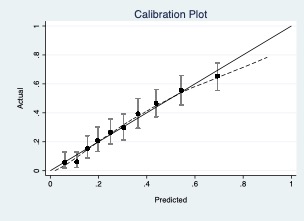
Overall, the model is well calibrated with some small exceptions at the top and lower end. However, the errors around the predictions are relatively large and there is quite a bit of overlap in the predicted risks of afflicted/non-afflicted. Regardless of what outcome the model predicts, this will probably lead to quite some over or under treatment (depending on where we put the cut-off).
I think you would accept quite some overtreatment as the alternative of not treating a (part of a) cancer is generally not acceptable.
Is it possible to get a little more information on what is predicted here as well as the proportion of adverse events or lymph node involvement? The outcome that is predicted here occurs in roughly 30% of individuals (rough estimation from the calibration plot), but this also means we don’t know how often either adverse effects of treatment or lymph node involvement occur in this population.
The response variable is not clear. In any case, if you are talking about the probability of at least one affected lymph node after lymphadenectomy, the hypothesis would be that low-risk subjects might not receive surgery. However, the best end point would be PFS or the % of local relapses over time, with or without lymphadenectomy. If everyone has had surgery and the interaction is not accounted for, it is possible that low-risk subjects with surgery will become high-risk individuals with a different therapy. Therefore, if the plot represents what I think it does, my answer is no. The intensity of therapy should not be reduced without considering the conditional nature of the probability.
I’m not sure why I understand why PFS or local relapses would be a better endpoint. The assumption here is that the risk of relapse or progression would be very high for a patient who has a positive lymph node but does not receive lymph node dissection during surgery. The idea of the model is to see if patients with a low risk of positive lymph nodes could be spared dissection.
It’s only my first insight without knowing all the details, so please take it cautiously. Your model seems to predict the conditional probability of having metastases, given that patients undergo lymphadenectomy. If patients eventually do not undergo surgery because of the prediction, the probability of relapse may paradoxically be higher. This could occur if you have errors in the classification of the nodal status, as a consequence of the pathological anatomy not having 100% sensitivity. There could be isolated tumor cells hidden in the nodes that are considered negative. The only way to know is to follow the patients and see if they relapse or not depending on the classification. Since the nodal status of unoperated patients is unknown, the only possible end point for all is local relapse over time. If you want to use the model as it is, it would only serve to recommend the opposite of what you say, that is, to support the decision to operate most of these high-risk individuals, but not to spare surgery in low-risk cases. That’s my view.
Typically in most cancers where lymph node dissection we decide to do the dissection based on the probability of involvement of nodes. This threshold varies but most surgeons will be comfortable offering the dissection if there is a 5% - 10% risk of nodal positivity. There will be several nuances to the decision but most of them will involve decision making regarding the tradeoff between missing a node and having the morbidity of dissection (and of course the risk of nodal recurrence). For example, if this model has been developed in head neck cancers, my decision making will be possibly facilitated. In the range of 5- 10% risk predicted by the model, the model possibly underpredicts the risk of recurrence a little but that may not be clinically significant. I would be comfortable using this model assuming the population this model has been developed in is representative of the population I deal with.
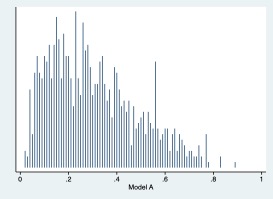
I am unclear what information the second plot is conveying. Is it showing the distribution of probabilities predicted by the model.
By the way excellent exercise. Your paper on decision curves is inspirational and I have been itching to try it out in a model.
Remember that these are hypothetical examples. I didn’t even describe a particular disease site! Suffice it to say that, as S_Chakraborty says, surgeons routinely use risk of positive nodes to inform the decision whether or not to remove lymph nodes. The question is, whether based on the calibration plots, AUC and the like, we can make a recommendation to a surgeon as to whether to use the model.
I always thought the net benefit and decision curve work was a very important contribution. For people considering using a model, I’m struggling to see where statistical measures focused on either discrimination or calibration offer anything that decision curve analysis does not. It would be nice if more papers presented net benefit across a range of thresholds so that net benefit could be included in meta-analysis.
One particularly valuable insight decision curve analysis provided for me was that we really need to have some active comparator when evaluating model performance. Clinicians are not clueless about risk in the absence of a prediction model, and it may well be that their judgement can provide estimates that are good enough to compete with models in a given domain. Completely uninformed predictions i.e. random bets are a silly comparator. Measures of overall discrimination and calibration are not useful for such comparisons because a model may outperform (or underperform) model-naive practitioners simply by being very good or very bad in an irrelevant range of risk.
Going back to the example, I think just like with the first one, we can’t make a definite conclusion about model usefulness based on just these metrics.
If we consider a risk threshold between 5-10% such as @S_Chakraborty suggests, then the model is miscalibrated precisely in this range and risks are overestimated for individuals with an average actual risk around the potential thresholds. I’d say this might make the model less useful for decision support as it is this area that you are uncertain of the balance between missing a node and treatment complications.
Yes, it is a general answer without knowing the background scenario. I’m sorry if I made a mistake. In general, I think the criteria for decision making should not be based on a prognostic model from an observational study, but on a RCT that demonstrates the safety & efficacy of carrying out or sparing the intervention. A prognostic model would allow stratifying individuals, but given that outcomes are conditioned to the intervention, a prognostic model can be used to define better eligibility criteria that requires validation in a RCT. As far as I know, a prognostic model based on an observational study should not in itself guide that decision making. In my opinion, this is a mistake. For example, it is believed that subjects with low-risk febrile neutropenia treated with high levels of supportive care may be given reduced support, but clinicians do not worry that this may increase their risk. When deciding on admission to the ICU, it is considered that those with a high risk of death should not be admitted, but it is not taken into account that the mortality on the normal hospitalization ward will be even higher. The literature is full of similar examples. The problem is the observational nature of the studies, not taking into account interactions or not testing the new criteria for stratification in RCTs. In your specific case, you cannot assume that a low probability of lymph node involvement after radical surgery is similar to a low probability of long-term local recurrence in absence of that surgery. For this reason, you cannot assume that lymphadenectomy is not critical to prevent relapse even in the low-risk group, nor can you predict what would happen to high-risk subjects if they did not have the surgery.
As you can see in the paper by Giuliano (above), the criteria for not operating is based on disease-free survival in a RCT with 10 years follow-up. The end point ‘number of positive nodes’ is just a surrogate variable, whose prognostic value depends on the background knowledge of each disease, but cannot be directly inferred or assimilated with a survival end point.
It is? Perhaps this shows the limitations of calibration plots, but the lowest decile is 6% (i just looked it up) and it is right on the 45 degree line (i just looked it up, it is 5.8% and 5.9%). the second lowest decile is about 10%.
If you want to say that we should only use prognostic models from RCTs and not from observational data for decision-making, fair enough, but then this thread isn’t for you. Most prognostic models are from observational data. if you want to argue about the benefit of lymphadenectomy, then that is rather straying from the point of the exercise. But if you like, you can imagine that the model is for spread to an adjacent structure, that removal of that structure is curative if affected by cancer but that removal of the structure leads to side effects.
None of these was my argument !
The point is that radical surgery is associated with side effects but suboptimal procedures are associated with recurrence and cancer-related death. So evaluate a database with operated and non-operated subjects, and look at efficacy and safety. If a dataset does not contain non-operated subjects, how can you infer anything about this population?
The point of this exercise is consider how we should evaluate prediction models. We are assuming that the risks and benefits of lymphadenectomy have already been well-characterized and that, as a previous commenter remarked, surgeons would do the dissection if risk was above 5- 10% or so. The data set is not to evaluate the value of lymphadenectomy but a prediction model to guide whether to do a lymphadenectomy in an individual patient.
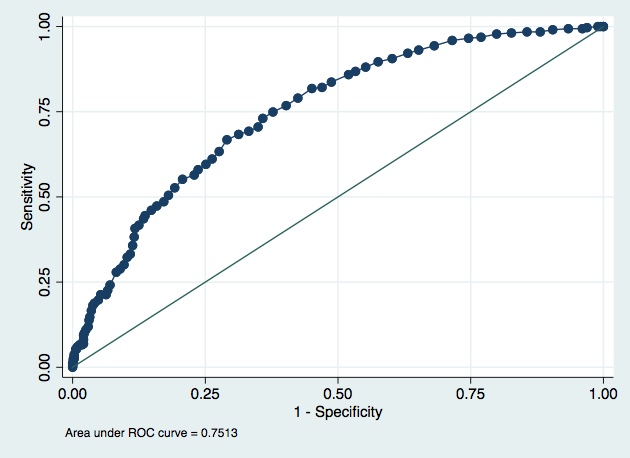
Great exercise. So at this point we have a model with good calibration but a quite poor discrimination. Am I right? It is difficult how to decide in face of this metrics if the model is OK to be used in practice. I consider that calibration is more “important” that discrimination, but @VickersBiostats is making his point very clear: we need more tools to decide. Let’s see how this continue!