Re ossified re: imputation I don’t think that I’ve seen any specific writings on this. We need to make it clear that imputations without using Y are improper and that using outcomes non-mechanistically (i.e., stochastically) does not steal outcome information into the baseline variables.
1 Like
Imputation is rare because adjustment of covariates beyond stratification factors is rare in pharma trials. It does not have to be limited to just stratification factors. Occasionally you do run into missing baseline outcome so imputation is helpful there. I find it strange that in large pharma people would want to adjust for postbaseline variable. In my experience it’s the opposite, that people know not to adjust for postbaseline variables intuitively but not necessarily understand why that’s an issue (blocking the causal chain , or a collider etc.)
3 Likes
yes, intuition should suffice, but if the “best statistician” says one thing, others follow the lead and sometimes the “best” is determined by who the clinicians favour, and they favour him/her because he/she is malleable. Moving between companies you see each has its habits which are justified as follows: “we always do it this way”. I think guidelines help here. Thus share guidelines widely and notice ema and fda guidance on adjustment for covariates even differs a bit as noted on linkedin: Paul Terrill on LinkedIn: New draft FDA guidance in case you missed it - on adjusting for covariates
1 Like
And what about continuous variables such as age or biomarkers? Any recommendations to account for non-linear associations ? Are restricted cubic splines acceptable ? How many d.f., should be predefined?
Frank, how should we use the outcome Y in a survival model? The event indicator and the survival time T? The Nelson-Aalen estimate at H(T) for each patient?
Yes this goes without saying. It’s just that the number of knots to be used needs to factor into the overall number of parameters often needing to be less than 10 or 8 and sometimes 5.
https://onlinelibrary.wiley.com/doi/abs/10.1002/sim.3618 which basically says to use the event/censoring time variable and the event indicator as imputers but not include their interaction.
But they seem to recommend using the cumulative hazard H(T) rather than T.
I has been implemented in the mice package…
Thanks for the correction. Check if the cumulative hazard is a 1-1 function of event/follow-up time. If that’s the case, using our usual nonlinear flexible spline imputation approach in R Hmisc::aregImpute should make this less important.
Related to the FDA draft covariate adjustment document, I’ve posted two new blog articles that are relevant. This one questions the appropriateness of adjusted marginal estimates on several fronts, especially on (1) the marginal estimates effectively assume the RCT sample is a random sample from the clinical population and (2) the claimed non-robustness of ordinary covariate adjustment needs to be questioned. In some sense, marginal estimates are the same as crude unadjusted estimates bit with correct (lower) standard errors.
UPDATE A commentary by myself and Stephen Senn is now available here.
2 Likes
Frank, in your post you defined the probability index which seems very similar to the AUC I defined earlier in another post:
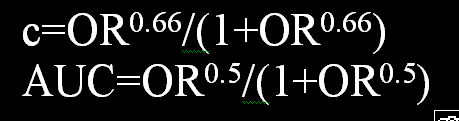
Whats the difference between c and the AUC?
c = concordance probability = AUROC = proportion of all possible pairs in which X is concordant with Y. The 0.5 power is not correct for the all-possible-pairs concordance index. You must be referring to a conditional concordance probability using only two covariate values, right?
Yes, that is right and in that case its 0.5 - right?
That is why I used it to make inferences on interaction terms
I think for simple ordering probabilities you are right but I’d like to see the derivation to check.
Derivation is as follows
In a diagnostic study, the diagnostic odds ratio (DOR) is a re-scale of the AUROC (AUC), but the AUC has an operational value from 0.5 to 1. Therefore:
ln(DOR)/2 = logit(AUC) [this can easily be checked to be true when DOR>=1]
ln(DOR)/2 = ln(DOR^0.5) = logit(AUC)
exponentiating:
DOR^0.5=Od(AUC)
Thus
DOR^0.5/(1+DOR^0.5) = AUC
The DOR in a diagnostic study is the same as the OR in logistic regression using the second covariate as the condition hence this holds for a conditional concordance probability using only two covariate values as you have mentioned previously.
from the blog post: The paper in our humble opinion began on the wrong foot by taking as given that “the primary goal of covariate adjustment is to improve precision in estimating the marginal treatment effect.”
more attempts to improve cov adjustment: Optimizing Precision and Power by Machine Learning in Randomized Trials, with an Application to COVID-19
“At the end of the trial, a prespecified prediction algorithm (e.g., random forests, or using regularization for variable selection) will be run and its output used to construct a model-robust, covariate adjusted estimator of the marginal treatment effect for the trial’s primaryefficacy analysis. We aim to address the question of how to do this in a model-robust way that guarantees consistency and asymptotic normality, under some weaker regularity conditions than related work (described below). We also aim to demonstrate the potential value added by covariate adjustment combined with machine learning, through a simulation study based on COVID-19 data”
there’s some interesting references … eg theyre movitaed by pnas paper: https://www.pnas.org/content/113/45/12673
I don’t think that either of the sources explained why a non-transportable marginal average treatment effect would be of interest. My opinion is that a key problem with several papers is the leap of logic in assuming that the low usage of covariate adjustment in RCTs implies that researchers are interested in marginal treatment effects. It doe not. It has much more to do with mental laziness that leads clinical trialists to do things as simply as possible. Then with a negative result they get interested in heterogeneity of treatment effects, which cannot be properly assessed with marginal methods.
4 Likes
the ema is drafting guidance on prognostic covariate adjustment: Opinions and letters of support on the qualification of novel methodologies for medicine development | European Medicines Agency
I’m seeing a lot of papers about optimising covariate adjustment, @f2harrell responded to one here: Commentary on Improving Precision and Power in Randomized Trials for COVID-19 Treatments Using Covariate Adjustment, for Binary, Ordinal, and Time-to-Event Outcomes | Statistical Thinking , here is a recent example in jasa: “we recommend a model-assisted estimator under an analysis of heterogeneous covariance working model that includes all covariates used in randomization” Toward Better Practice of Covariate Adjustment in Analyzing Randomized Clinical Trials
the fixation on statistical efficiency feels untoward. Data scientists bring to clinical research a different mindset that in some cases emphasises calculation over clinical understanding. Is some of that starting to leak into statistical thinking, or it’s always been there …? I havent had time to think very deeply about it, clearly. Note in the draft above it says “the construction of the prognostic model may be outsourced to machine learning experts”. I’ve heard it said (i dont know how true it is) that in that field there is a dominant view that we should not even seek to undesratnd the black box
1 Like
Targeted maximum likelihood estimation (TMLE) uses an ensemble of machine learning methods called “super learner”. I tried super learner once and got some of the worst overfitting I’ve ever seen. Using an emsemble of methods did not protect against one dominanting part of the ensemble overfitting to an extreme (a random forest-like method). But to your point a recent study found that you need to put the whole TMLE process, which is hugely computationally burdensome, inside a cross-validation loop for the inferences to be accurate. Thus computational costs will skyrocket. By the time you do all this you’ll probably see that ordinary parametric covariate adjustment works pretty darn well. I keep doing simulations to see if an extreme model validation invalidates the results of the adjusted treatment comparison and so far haven’t demonstrated a problem. I’m concentrating on semiparametric models.
3 Likes
id be very interested in hearing about any future progress with the simulations. As you note in the blog post, they compare with no adjustment when claiming the superiority of some new strategy, and that’s not really a test
Yes- what I’m most concerned about is that new methods need to compare performance with old methods. Standard ANCOVA was never addressed in the paper. One way to think about robustness as detailed in fharrell.com/post/impactpo : totally mismodeling an adjustment variable is like it wasn’t there, giving you an unadjusted comparison.
2 Likes