Can you clarify the definition of outcome heterogeneity? What is a good/intuitive example?
How is it possible that controlling for a confounding doesn’t address outcome heterogeneity? In addition, why does propensity score control for confounding, but doesn’t necessarily address outcome heterogeneity?
Good questions. Outcome heterogeneity equals the existence of risk factors for the outcome. This is also called susceptibility. If older patients are more likely to suffer the outcome, there is outcome heterogeneity due to age. Confounding due to age would mean in an observational study that the age distribution is different for patients getting treatment A compared to those getting treatment B, and that age is also associated with outcome. If one controlled for the confounder age through covariate adjustment, and the age relationship was not oversimplified (i.e., linearity was not assumed when the age effect is nonlinear), then the covariate adjustment will explain outcome heterogeneity due to age while also adjusting for confounding due to age. Explaining more outcome heterogeneity means increasing power and getting the overall model more correct, which will negate things like non-collapsibility of odds ratios. If age appears in a propensity score (PS) but not as a separate covariate, explanation of outcome heterogeneity will be incomplete unless both the shape and weight of the age effect in the PS, which are derived without reference to the outcome variable, happen miraculously to equal the shape and weight against the outcome. Outcome heterogeneity would typically be under-modeled. In the case where age happened to have the same distribution in A and B but is prognostic, the PS will ignore age and you’ll miss accounting for a lot of easily explainable outcome heterogeneity.
All this is why PS is a more complicated procedure and is only recommended when the set of potential confounders is so large as to not allow for ordinary covariate adjustment due to overfitting. PS is complicated because you have to develop a PS model, use a spline function of the logit of PS for adjusting for PS (if using an ordinary regression model) and you have to have key prognostic variables also as separate predictors in this model. PS takes care of confounding and the separate variables (like a spline of age) take care of explaining easily explained outcome heterogeneity.
On a related note, PS hides treatment by covariate interactions.
7 Likes
I will attempt a simple example to illustrate this as requested by @Agnes_Cororaton
Say we have the data below from a RCT:
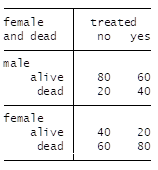
Males / females are distributed equally so there is no confounding by sex of the treatment effect
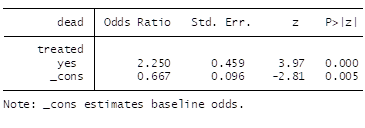
The marginal OR is given by:
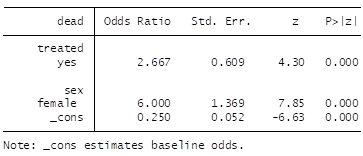
Then after adjustment by the prognostic covariate (sex) we get:
Now we note what has been discussed in this thread:
a) The adjusted OR (2.67) is closer to the empiric individual treatment effect
b) The unadjusted OR of 2.25 does not apply to males, does not apply to females and applies only to a person whose sex the physician refuses to know and whose distribution is as in the RCT
c) The change in OR (from 2.25 to 2.67), although attributed to noncollapsibility, in reality reflects a change due to reduction in outcome heterogeneity due to sex
1 Like