Have you heard of hybridizing Delphi and AI. Probably not, its new. Yet the dataset used to train AI are derived from samples which might reflect significant bias. What happens if this occurs? This is one of the most pressing questions at the intersection of AI and traditional statistical analysis.
The present state of RCT for critical care syndromes is in flux. For the past 35 years the RCT measurements defining the syndrome under test were simply “expert guessed” or derived by the 1980s Delphi consensus derivation method. This approach has failed.
This linked study offers a new “hybrid” approach for deriving threshold RCT measurement and clinical score derivation combining machine learning and the Delphi method.
While it may seem reasonable to discount the entire result, given the failure of one-size-fits-all threshold measurements to measure a syndrome comprised of many hundreds of infection types accross the world, the authors try hard to render data driven results and should be commended for trying to step away from (or improve) the old syndrome RCT measurement guessing method.
Here though, we see how bias associated with combining expert opinion (Delphi Method) with AI/ML can produce interesting results.
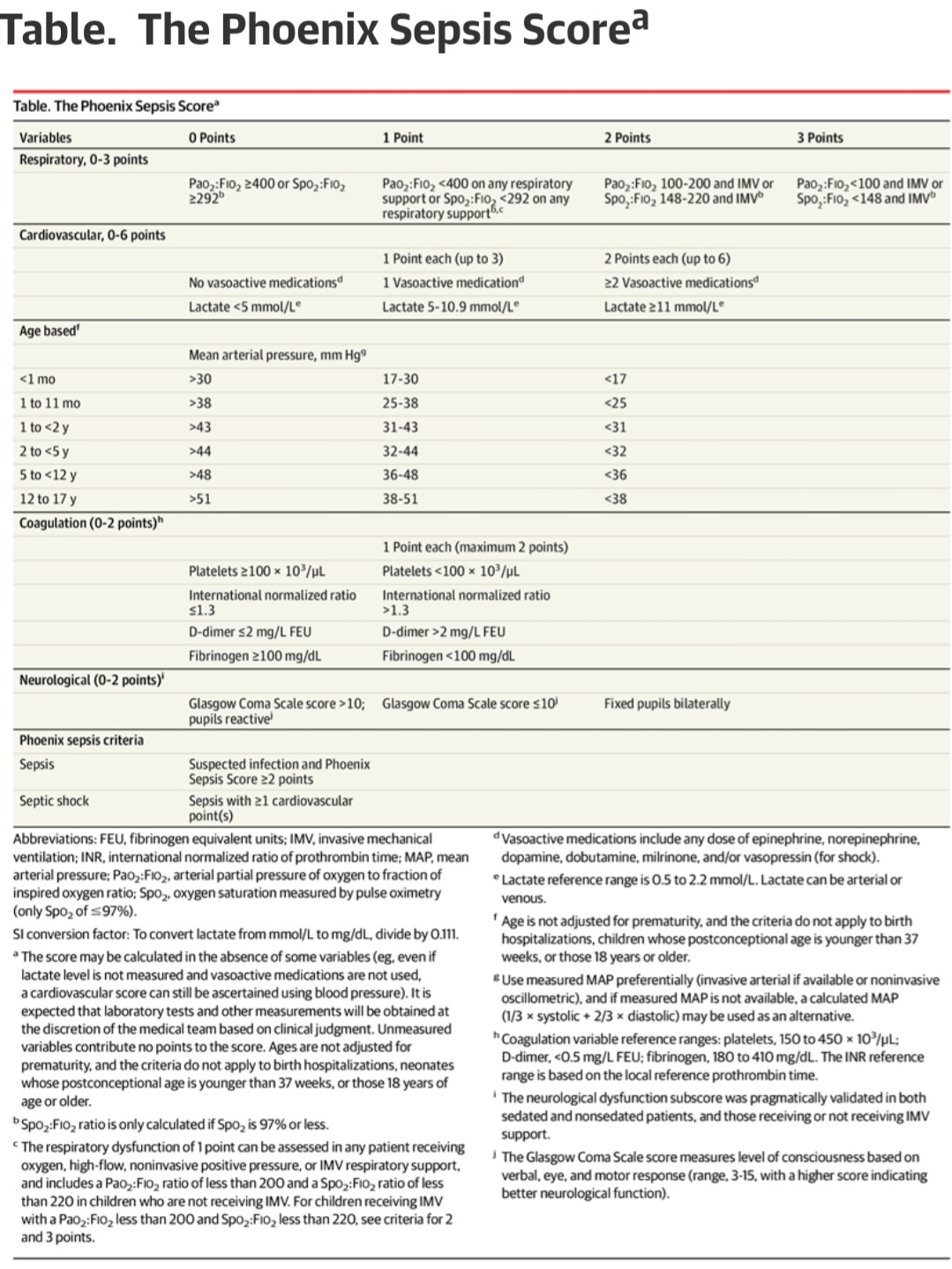
For example the platelet threshold of 100 is identicle to the platelet threshold of 100 from SOFA (guessed in 1996).
Futher we see they apparently use SOFA and other legacy guessed scores as a features along with the raw data for ML training.
The conclusion that the threshold for platelets is the exact same number (100) as guessed legacy scores may indicate that bias crept into the ML.
Indeed 100 and 10 were favored numbers in the old 20th century legacy thresholds reflecting “number bias”.
This is one danger of AI, that it may be trained on biased datasets or that the datasets chosen for training are defined by bias.
The most striking occurrence here is the absence of a score for myeloid failure. This may be due to to bias against the legacy Myeloid thresholds of SIRS (WBC of 12 or Bands 10%) which were guessed and certainly set as too sensitive. Measurements from the myeloid system have been used as part of the standard for almost 35 years and now the whole system is abandoned.
The myeloid system had already been deleted from the adult sepsis measurement when SEPSIS 3 (which was based on SOFA) replaced SIRS in 2015. The authors state they had a goal of harmonizing with the adult measure. One possible example of legacy measurement bias
I bring this here because one of the risks of AI is that the massive datasets make the thresholds appear valid. Certainly platelets, lactate and the other signals are death signals in infection, so correlation with death is expected and does not validate a particular threshold for clinical use as measure of a syndrome comprised of a SET of diseases.
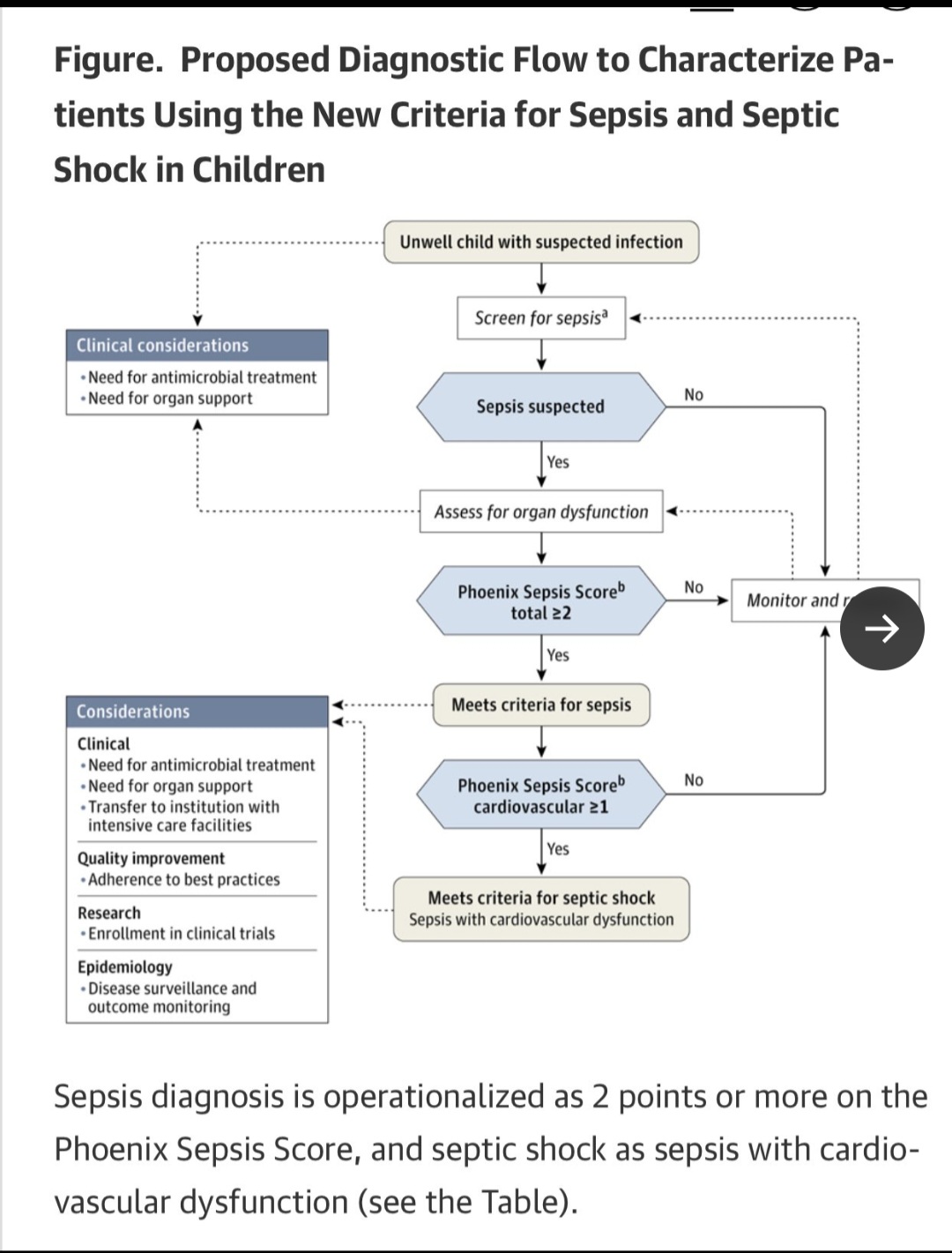
Here they also offer a clinical decision tree for a patient based on the derived thresholds.
From a worldwide AI and Delphi processed data set to the beside of a 6 year old in Kenya and a 14 year old in St. Louis, this is a scary proposition for anyone understanding the limitations of syndromes and AI.
This is being discussed on X but we need this groups help here or join in on X. These are the world’s children in a state most vunerable, a time to engage the world’s great statistical minds
We are at the cusp of the introduction of AI, and here it starts with the derivation of measurements for bedside clinical and RCT use. This has to be right. I’m hoping for many comments.
This paper is a major accomplishent. Profound amount of organization and work. Yet, is it effective to pool data from accross the world, apply AI, and derive a threshold value for clinical use in the instant patient? Is that an effective use of AI? It’s a question that must be answered soon given the promulgation of this standard which may be clipped to the pediatric ward walls within days.
Its worthwhile to think of the heterogeneity of those pooled cases. Can we generalize such broadly aquired results to the local, instant patient under care and can we apply them as measurements for RCT?