I posted some of this in another discussion:
However this method for defining measurements for syndrome RCT and for clinical decision making relating to syndromes is particularlly relevant to this thread.
Rather than simply guessing the measurements for a syndrome (as they had for 35 years) they now blend in ML. Yet, like the past guessed iterations, this is a still one-size-fits-all measurement.
This is an image of the most recent process for defining RCT measurement and clinical decision making, relevant to the syndrome “pediatric sepsis”. Data from patients virtually worldwide are obtained.
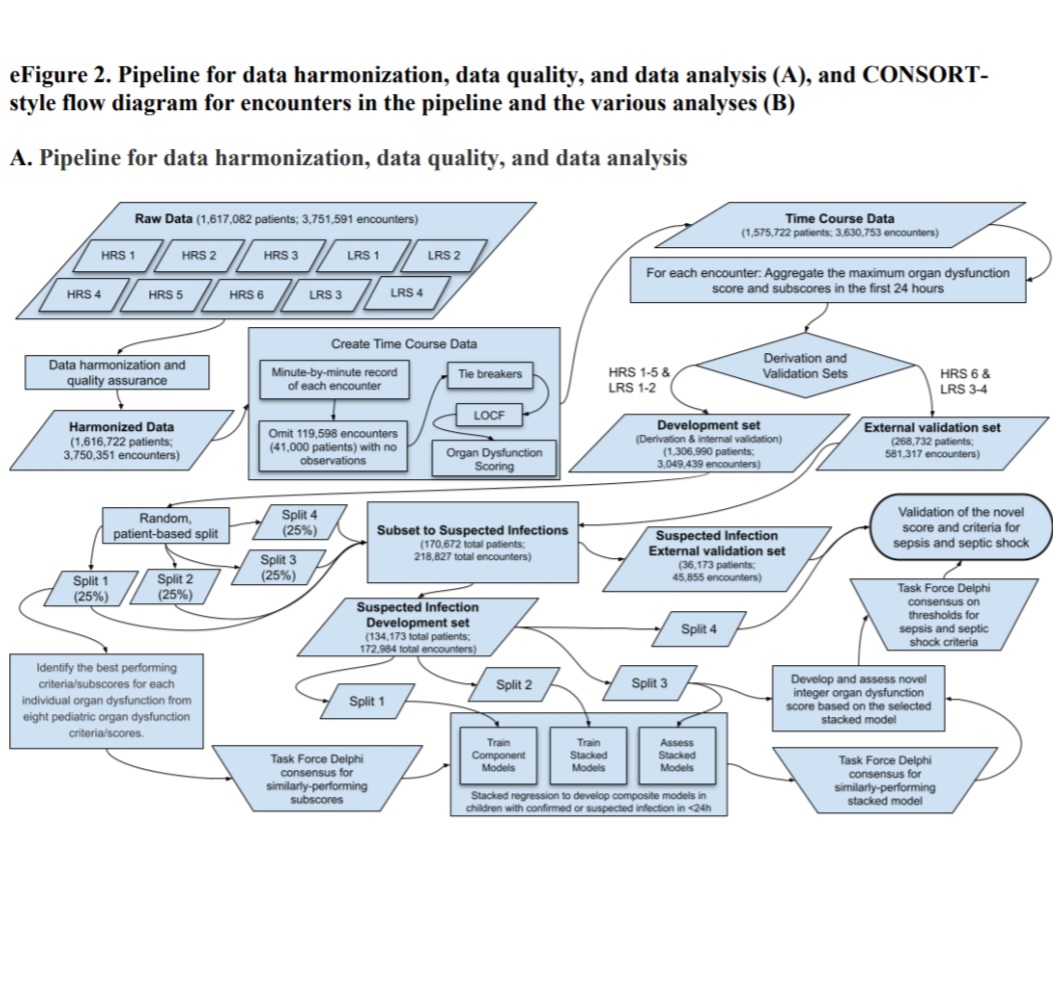
The result of this process are the RCT measurements (thresholds) and the clinical decision thresholds promulgated below.
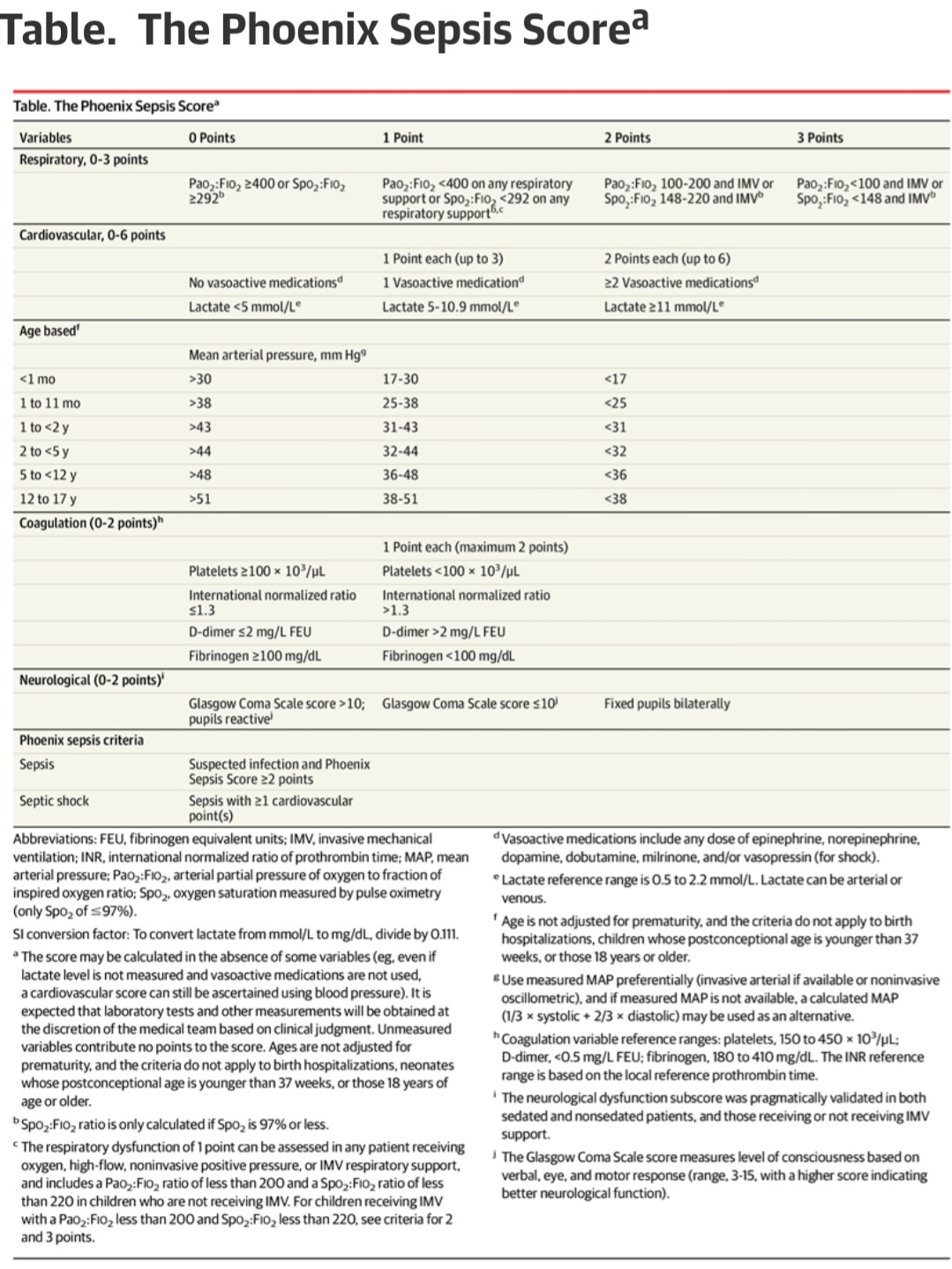
In research applications, these thresholds will be used to measure patients to identify “sepsis” for testing a given treatment and in clinical medicine the physcian is advised to use the threshold in a sample decision tree.
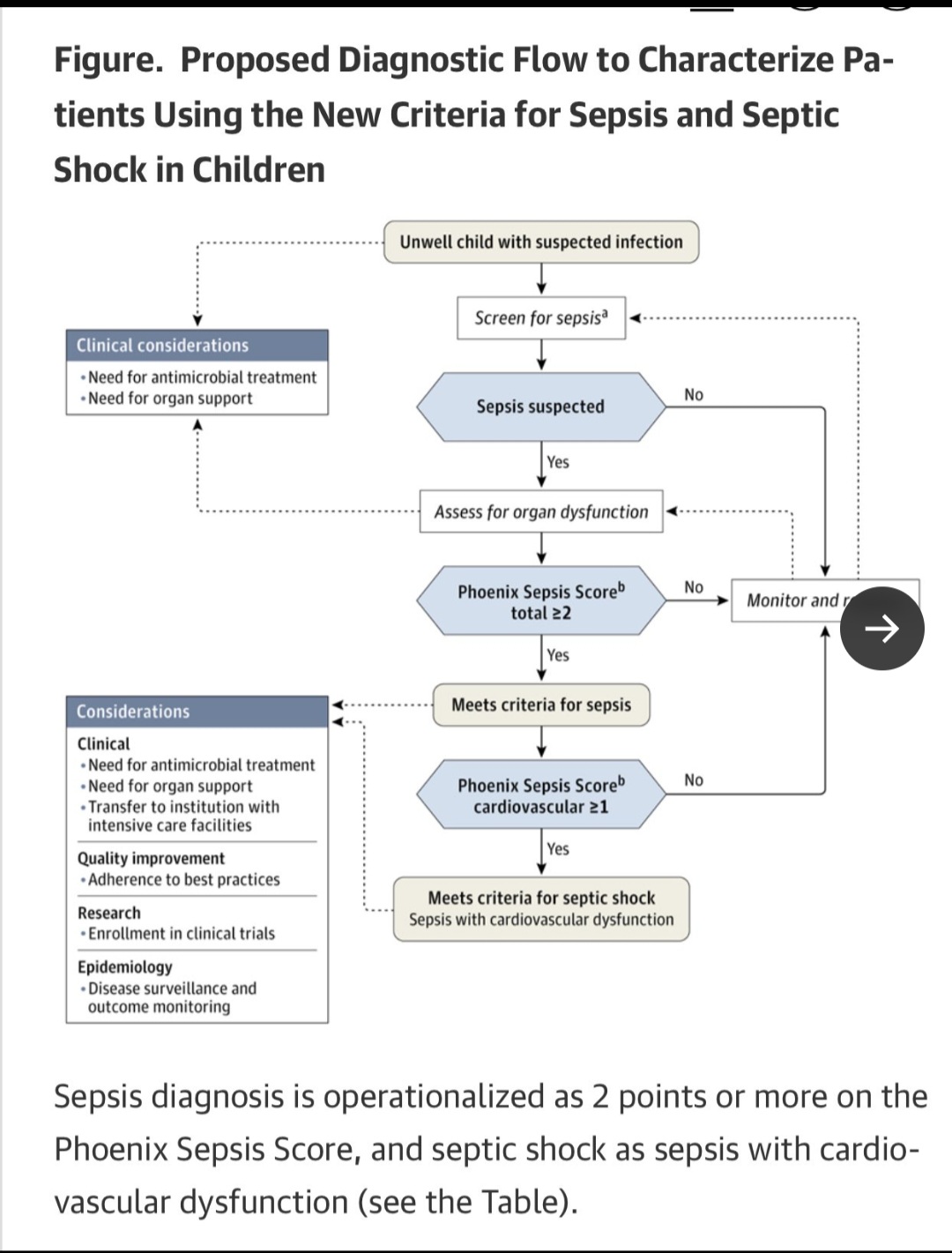
In the future, now that these are standards, RCT are performed with these measurements capturing the population. The captured patients are randomized and treatment applied to the treatment group. Rigorous math (Statistical processing) will then then applied to the outputs.
So is this is the same as the old PathologicalConsensus method but with ML/AI applied instead of simply guessing thresholds de novo?
Will this method work? Is this method statistically sound?