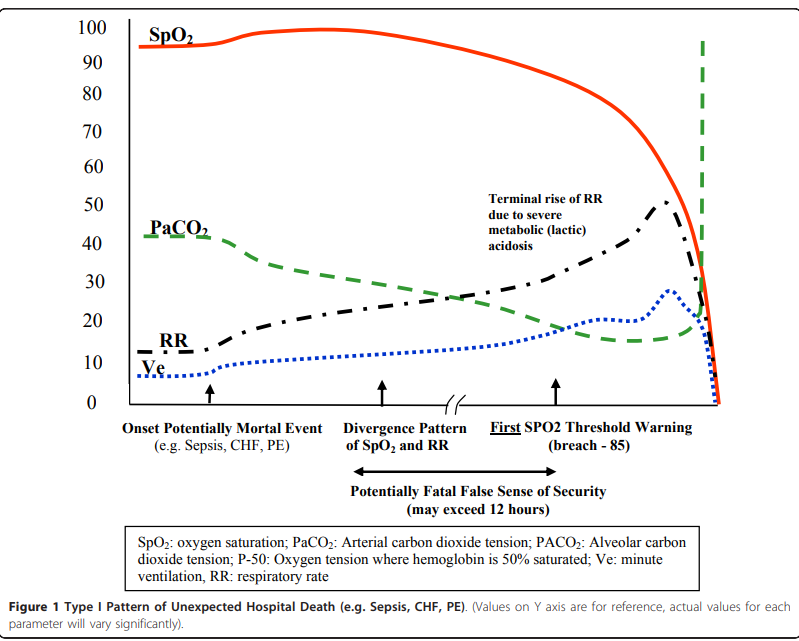
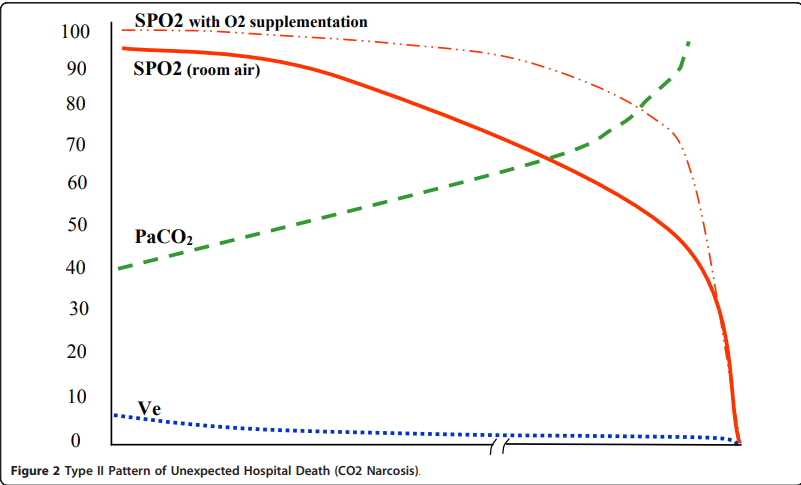
Apologies for resurrecting this old thread, but I came across some additional relevant publications and links (phrases that stood out to me are bolded).
Recently published:
“ This formulation has the following simple implication: when policy-makers optimize counterfactual utilities, then, in general, more people will die. Proponents of a counterfactual approach may argue: but all deaths are not considered equal; they may argue that the true utility, given by…, is one that uses the possibly asymmetric counterfactual utility function on the principal strata that is appropriately formulated to reflect notions of counterfactual harm. However, a serious problem is that we have no direct evidence that these principal strata exist . Even if one makes the metaphysical commitment to their existence, a patient will never know their true principal stratum, except under extreme circumstances; thus, no patient will ever know their post-hoc utility, and no policy may ever be evaluated, or compared to an alternative policy, using direct observations. In other words, the counterfactual approach requires a faithful belief in metaphysical objects whose existence can neither be confirmed nor denied. While patients may be free to hold such beliefs, policy-makers should know the implications: when a counterfactual framework is deployed to determine social policies and regulations, it coerces conformity to an unverifiable metaphysics and a corresponding logic that deals in those terms. In contrast, when an interventionist framework is deployed in such a setting, no such coercion is made, and patient and group outcomes are observable and thus transparent…
…We have defined and contrasted counterfactual and interventionist approaches to decision making. Contrary to claims of some authors [15, 7], a counterfactual approach should not necessarily portend a revolution in personalized medicine… In tension with proponents of a counterfactual approach, we have reviewed several practical and philosophical considerations that seem to problematize its use and challenge some of its core premises, e.g. that it somehow naturally corresponds with prevailing medical ethics and legal practice. Perhaps most problematic from a population policy-maker’s perspective: when the outcome is death and a counterfactual approach is used, in general, more people will die under the identified optimal policy compared to that identified by an interventionist approach. A strong critique of the counterfactual approach calls it “dangerously misguided”and warns that “real harm will ensue if it is applied in practice” [24]. We take the following stance: as causal inference become increasingly embedded in the development of personalized medicine, it is important that stakeholders clearly understand the different approaches to decision making and their practical and philosophical consequences.”
A rebuttal:
“…In a recent paper Mueller and Pearl, 2023, we illustrate an example of a treatment that diminishes the death rate by 30 percentage points, from 80% to 50%, equally in both men and women…
These conclusions are not metaphysical but logically derivable from the available data (assuming that the treatment and outcomes are binary and that the system is deterministic1 , hence every individual must fall within one of the four possible response types, or principle strata (S ∈ {1, 2, 3, 4}) as defined by SS)…
1 The deterministic assumption was contested by Dawid [Dawid, 2000] and defended in [Pearl, 2000]. Dawid’s contention emanates from the observation that the response of each individual may vary with unknown factors (e.g. time of day, previous history, patient’s mood, etc) and cannot, therefore, be a deterministic function of the treatment. However, if we include those factors in the definition of a unit, determinism regains its legitimacy (barring quantum uncertainties) .”
From post #213 above:
“This assumption of ‘consistency’ is therefore unverifiable and unrefutable by study and based on personal belief leading to a forceful assertion. ”
This quote seems to be supported by a statement at minute 6:43 in the video linked below: “I strongly believe that we are deterministic machines…”
I’m no philosopher, but belief in causal determinism seems pretty controversial (likely because it’s unprovable/“metaphysical”?). Those who don’t agree with a deterministic view of human biology/physiology/behaviour seem unlikely to adopt any proposed method of decision-making in their field that depends on deterministic assumptions…
In Dr.A.Gelman’s blog from July 26, 2021, there was an interesting discussion between statisticians about deterministic versus stochastic counterfactuals and the potential outcomes framework (entitled “A counterexample to the potential-outcomes model for causal inference”- unfortunately, the link below seems a bit wonky)
https://statmodeling.stat.columbia.edu/2021/07/26/causal-counterexample/
“As regards “I guess the right way to think about it would be to allow some of the variation to be due to real characteristics of the patients and for some of it to be random”, I guess I like to think in terms of mechanisms. In the case of adjuvant chemotherapy, or cardiovascular prevention, an event (cancer recurrence, a heart attack) occurs at the end of a long chain of random processes (blood pressure only damages a vessel in the heart because of there is a slight weakness in that vessel, a cancer cell not removed during surgery mutates). We can think of treatments as having a relatively constant risk reduction, so the absolute risk reduction observed in any study depends on the distribution of baseline risk in the study cohort. In other cases such as an antimicrobial or a targeted agent for cancer, you’ll have some patients that will respond (e.g. the microbe is sensitive to the particular drug, the patient’s cancer expresses the protein that is the target) and some that won’t. The absolute risk reduction depends on the distribution of the types of patient.”
In the comments section from this blog post:
Sander Greenland on July 26, 2021 2:41 PM at 2:41 pm said:
“Andrew: As an instructor like you are, I found deterministic models provide simple, intuitive results that often generalize straightforwardly to all models; but it seems Vickers was getting at how some mechanistic models are much better captured by stochastic potential outcomes. Thus early on I began using stochastic potential outcomes for general methodologic points…In light of my experiences (and the current episode you document) I have to conclude that adequate instruction in causal models must progress from the deterministic to the stochastic case. This is needed even when it is possible to construct the stochastic model from an underlying latent deterministic model. And (as in quantum mechanics) it is not always possible to get everything easily out of deterministic models or generalize all results from them; for example, it became clear early on that while some central results from the usual deterministic potential-outcomes model generalized to the stochastic case (e.g., results on noncollapsibility of effect measures), others did not (e.g., some effect bounds in the causal modeling literature don’t extend to stochastic outcomes). And when dealing with the issues of causal attribution and causation probabilities, Robins and I ended up having to present 2 separate papers for technical details, one for the deterministic and one for the stochastic case (Robins, Greenland 1989. “Estimability and estimation of excess and etiologic fractions”, Statistics in Medicine, 8, 845-859; and “The probability of causation under a stochastic model for individual risks”, Biometrics, 46, 1125-1138, erratum: 1991, 48, 824).”
I doubt that many physicians or social scientists (who contend with problems that reflect the interplay of biological, behavioural, and environmental complexity) would subscribe to a view of human beings as “deterministic machines” who will always react the same way when presented with a certain stimulus/input/treatment. It follows that few who work in these fields would entrust life or death decisions to a decision-making framework that is supported by such an assumption.