I have a question that leads on from observations on non-collapsible odds ratios. Let’s start with Greenlands example:
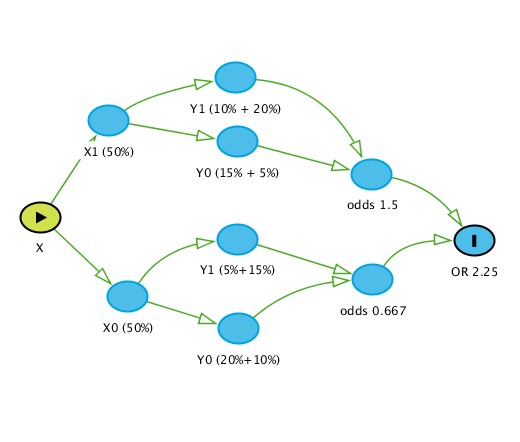
This figure demonstrates the flow of stratification (X is the exposure and Y is the outcome) and clearly the unconditional OR (2.25) differs from the ones conditioned on Z (2.67) and the reason is quite clear - the unconditional OR is subject to how Z redistributes across strata of X given that both X and Z are prognostic for Y. Thus the OR of 2.25 is simply an “average” OR when we do not measure other prognostic factors and Z while the conditional OR is the “average” OR when we do not measure other prognostic factors except Z. Thus we can agree that non-collapsibility implies that this is a true effect measure and collapsibility implies otherwise.
Having introduced this lets analyze the Greenland example using logistic regression and a sample size of one million:
We get the ORs as expected
1.X 2.67
1.Z 6
X#Z 1
_cons 0.25 (baseline odds)
These are the same results from Greenland
Now lets randomly select a sample of 400 from this million participants and run the regression again
We get the ORs as follows
1.X 1.30
1.Z 2.74
X#Z 2.76 (P=0.022)
_cons 0.46 (baseline odds)
Without the interaction we get back to a closer estimation of reality which is:
1.X 2.13
1.Z 4.35
_cons 0.35 (baseline odds)
Each time we select a sample of 400 this interaction term varies widely. The average OR remains reasonable without the interaction but seems ridiculous with it and the interaction is basically a consequence of random redistribution of strata so does this mean that interactions are not meaningful since they are simply due to random error?
 . Its much clearer in my mind now and you are right - there needs to be a more nuanced view taken regarding these product terms and of course some basic understanding of the underlying context.
. Its much clearer in my mind now and you are right - there needs to be a more nuanced view taken regarding these product terms and of course some basic understanding of the underlying context.