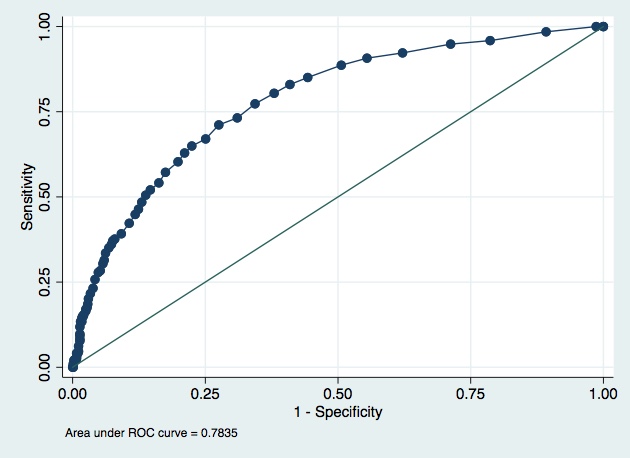
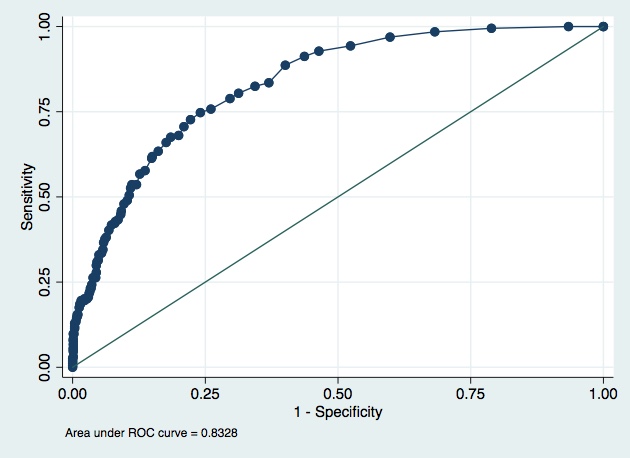
Two models have been proposed to select for biopsy patients at high-risk for aggressive prostate cancer amongst those with elevated PSA. These two models are evaluated on an independent data set. Model A is the standard model used in many clinics. Model B is a new model that adds in the results of new imaging test. The new test is somewhat unpleasant for patients, although far less unpleasant than a biopsy. Should we use the new model, subjecting patients to the unpleasant new test?
What is the unpleasantness that you refer to in your description of the new imaging test? That seems to be a key factor in your framing the question as to which model to use.
Having recently been through an mpMRI for prostate cancer evaluation myself at the Mayo Clinic in Jacksonville, FL, there was nothing unpleasant about it, other than being in an MRI tunnel for an hour. Certainly easier than a trans-rectal or a trans-perineal biopsy.
In my case, as a low risk patient, the results of the mpMRI, which found no lesions (low PI-RADS score), also supported the decision, in consultation with my urologist, to delay a biopsy and follow up in 6 months with PSA monitoring. Contrast that to the urologist to whom I was referred originally in the Orlando area, who would not have done the mpMRI and would go directly to a biopsy. Given the risks associated with a biopsy, including bleeding and infection, avoiding a biopsy is a benefit of the mpMRI, given other factors that support a decision to delay a biopsy.
In addition, if one has the mpMRI results and a decision is made to proceed to biopsy, the ability to use fusion MRI/biopsy provides enhanced diagnostic capabilities for biopsy mapping and targeting the cores taken.
TRUS to get volume for instance? But remember that what we are talking about here is evaluation of models. Let’s not get too distracted by the specifics of the hypothetical examples. These are simulated data sets after all…
Actually, I got a prostate volume from the mpMRI…so did not need the TRUS…
The key is to be at a facility using a 3 Tesla MRI (which also avoids the need for the rectal coil) and have experienced radiologists vis-a-vis reading mpMRIs.
In either case, your point is taken. Just adding my thoughts both as a statistician and as a patient on the receiving end of a decision tree process relative to my own care. Since you raised it, the notion of unpleasantness, if any, is relative to other considerations.
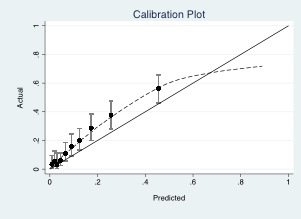
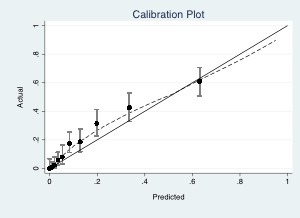
Both of your models have a tendency to under-predict the risk, albeit, less so in model B.
Having been through the process, I would opt for using model B, especially in light of the potential benefits of the imaging, even if one does get a biopsy, presuming that you were referring to mpMRI, as I noted above.
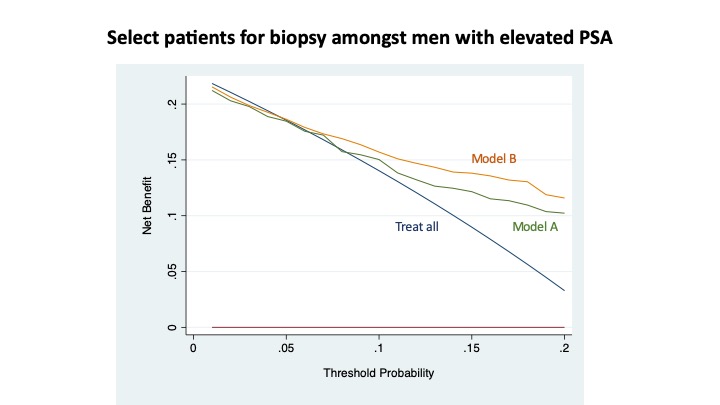
Model B seems better across the board, less under-prediction, better AUC etc. It’s however not directly clear if the better performance of B results in a worthwhile improvement in individuals with the outcome undergoing the biopsy and whether this outweights any discomfort/risk that is caused by the additional test that is required for model B.
In a bit more detail. In the first topic about these models we considered the 5-20% range as the likely area for the cut-off for determining whether to proceed to a biopsy or not. In this range, there is some difference with again a better performance for model B around these cut-offs, but the differences are not that big as those at higher predicted risks.
I think these last ones are relatively unimportant for choosing between model A and B, as on average the high risk individuals will receive a high predicted risk under both models. These individuals gain only the potential harm from undergoing the additional test with no additional benefit from model B (as long as we think of this as a theoretical exercise of course, in reality there might be other benefits such as @MSchwartz highlighted).
In the area around the cut-offs, B performs slightly better and should on average more accurately predict whether individuals are above/below any potential threshold. But from the data alone above, I don’t think we can say how big this improvement is and if it outweighs exposing the entire population to an additional test.
Model B seems better, yes. But is the improvement that you see with model B (e.g. 0.05 points better on AUC) enough to justify the additional imaging test?
I agree that it is difficult to tell from the data given. But isn’t this a huge problem? Here are all the metrics we have been told to report for years, and they can’t even answer the most basic of questions.