How to estimate the Non inferiority Margin/Equivalence Margin if we do not have Placebo controlled Trial
This is not the answer you are looking for, but the tradition of determining noninferiority margins from previous studies has got to end IMHO. Non-inferiority should be based on what’s important to the patient no matter how well an active control has done in comparison to placebo previously.
3 Likes
Is this then equivalent to the minimal clinically important difference? Many trials seem to still derive this from previous studies when it ought to be from patients or subject matter experts. And others just pick a value…
There has been some work done on Bayesian noninferiority trial designs - but is a “noninferiority trial” not really a purely frequentist concept? A trial analysed with Bayesian modelling could produce an estimate of treatment effect anywhere on the spectrum from inferiority to equivalence to superiority. The outcome might be noninferiority, but there doesn’t seem to be a need to specify this as the goal at the outset under this paradigm.
if i remember correctly Senn argued against pre-specification for the non-inferiority margin, but that may have been many years ago, or even just an off hand remark made at a conference
edit: actually it’s in his book, section 15.2.9 It is essential that the noninferiority margin be prespecified: “What this suggests is that it is not prespecification of the interval of equivalence
that is important but rather the interval that may be believed to obtain once the data
have been analysed. A cynical interpretation of current accepted practice is that the
regulators are merely abandoning their obligation to decide what is and what is not
equivalent and attempting to hide behind prespecification. To be fair, these guidelines
do require that the margin should also be medically justified in some way, but it is not
clear why this can be left to the sponsor.”
1 Like
It is so trivial to do with Bayesian posterior inference that I think you’re right there is little need for it in the Bayesian paradigm.
1 Like
Blockquote
How to estimate the Non inferiority Margin/Equivalence Margin if we do not have Placebo controlled Trial.
There seems to be a distinction between a “non-inferiority” trial (where the control is a treatment presumed to be effective), and an efficacy trial, that is compared to placebo (presumed to be inert).
The following has a nice chart that elaborates on the distinction.
The regions and the frequentist procedure to provide evidence against the default:
- Noninferiority – .One sided test against lower bound of effect size of interest.
- Equivalence – TOST (Two one-sided tests).
- Efficacy – Two Sided conventional test against effect of exactly 0.
I do think the Bayesian intervals or Jeffrey Blume’s interval intersection procedure are interesting alternatives.
1 Like
I’ve been struggling with this recently - especially in the context of efficacy testing vs. non inferiority testing. Specifically, why do we talk about efficacy testing as a two sided test with alpha = 0.05? If the investigational treatment is ‘significantly worse’ and the NH test has a p-value of < .05 then wouldn’t we still say that the trial fails? Why don’t we just do one sided tests with alpha = .025?
With inferiority testing, the default hypothesis is that the treatment is inferior, so there is no interest in any effect below the lower bound of the MCID,
When testing at a presumed effect of 0, a significant true negative result would be surprising, and likely reported. If you just test for one side, you miss significant effects in the opposite direction.
1 Like
THe clinically irrelevant difference would usually be much lower than the clinically relevant difference. (IMO, certainly no more than 1/3 of the former.) There is some related discussion here Minimally important differences v2 (slideshare.net)
1 Like
Dr. Harrell,
Could you elaborate on the relationship between “Bayesian posterior inference” and noninferiority analysis?
Briefly, with classic frequentist non-inferiority testing you set a non-inferiority margin, i.e., how much harm can the treatment get away witih before you wouldn’t use it, then do a hypothesis test to try to reject the new treatment being that bad, in favor of it being better than that. The margin is pretty arbitrary and the inference is very indirect. With Bayes you define a similarity margin, e.g., for a binary or ordinal outcome you might set an odds ratio (OR) between 4/5 and 5/4. Then try to show that the Bayesian posterior P(4/5 < OR < 5/4) is high, to bring evidence for similarity. The corresponding evidence for non-inferiority would be P(OR < 5/4).
1 Like
Totally agree. Equivalence analysis using Bayesian methods is indeed very informative. The latest REMAP-CAP preprint is a great example:
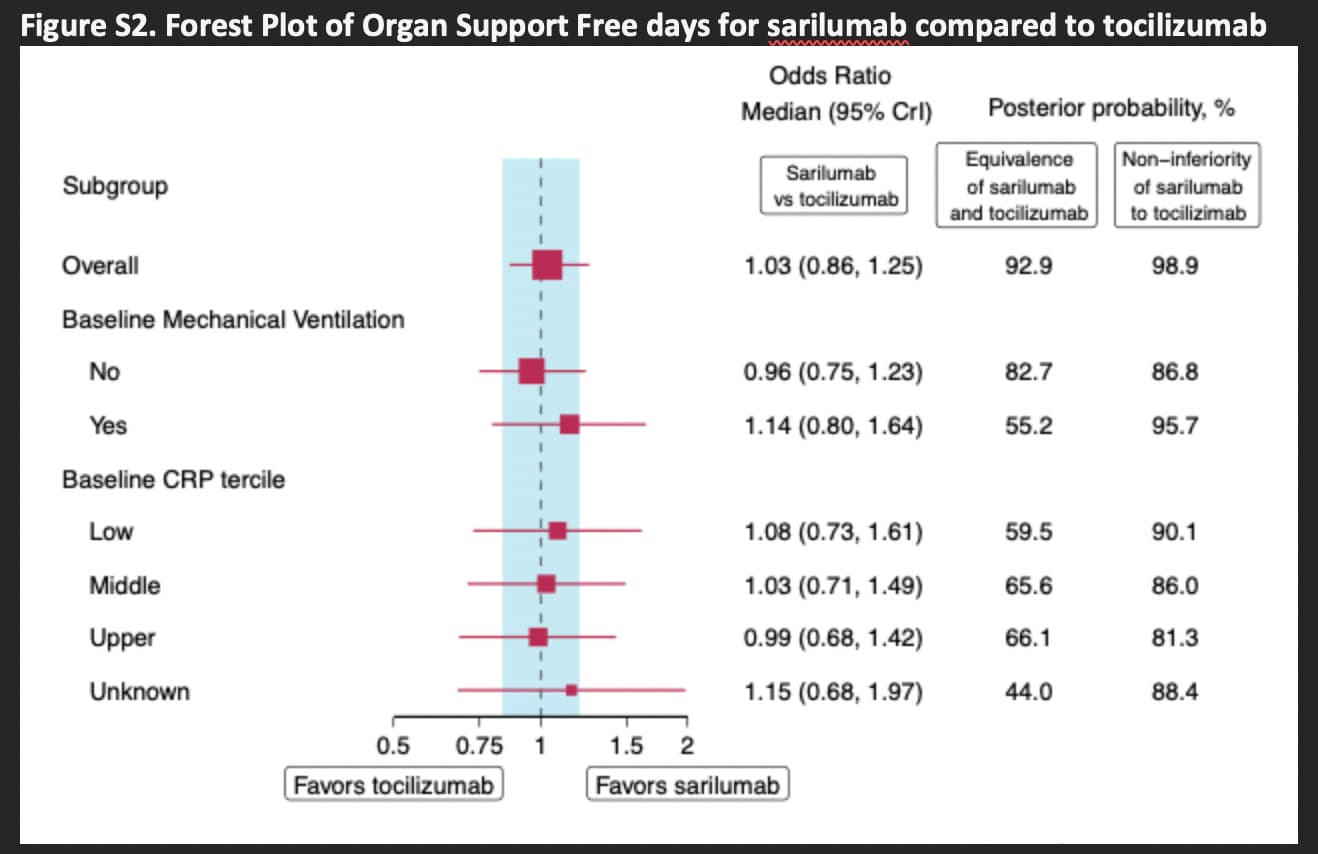
Ref: https://www.medrxiv.org/content/10.1101/2021.06.18.21259133v2.supplementary-material “Supplementary Appendix”, page 45
1 Like
Fantastic. P(non-inferior) must be > P(similar) as they show.
1 Like
I would like to point out that one could even perform great sensitivity analyses with different margins while using Bayesian methods. John Kruschke has a post with informative figures on this topic: Doing Bayesian Data Analysis: How much of a Bayesian posterior distribution falls inside a region of practical equivalence (ROPE)
1 Like