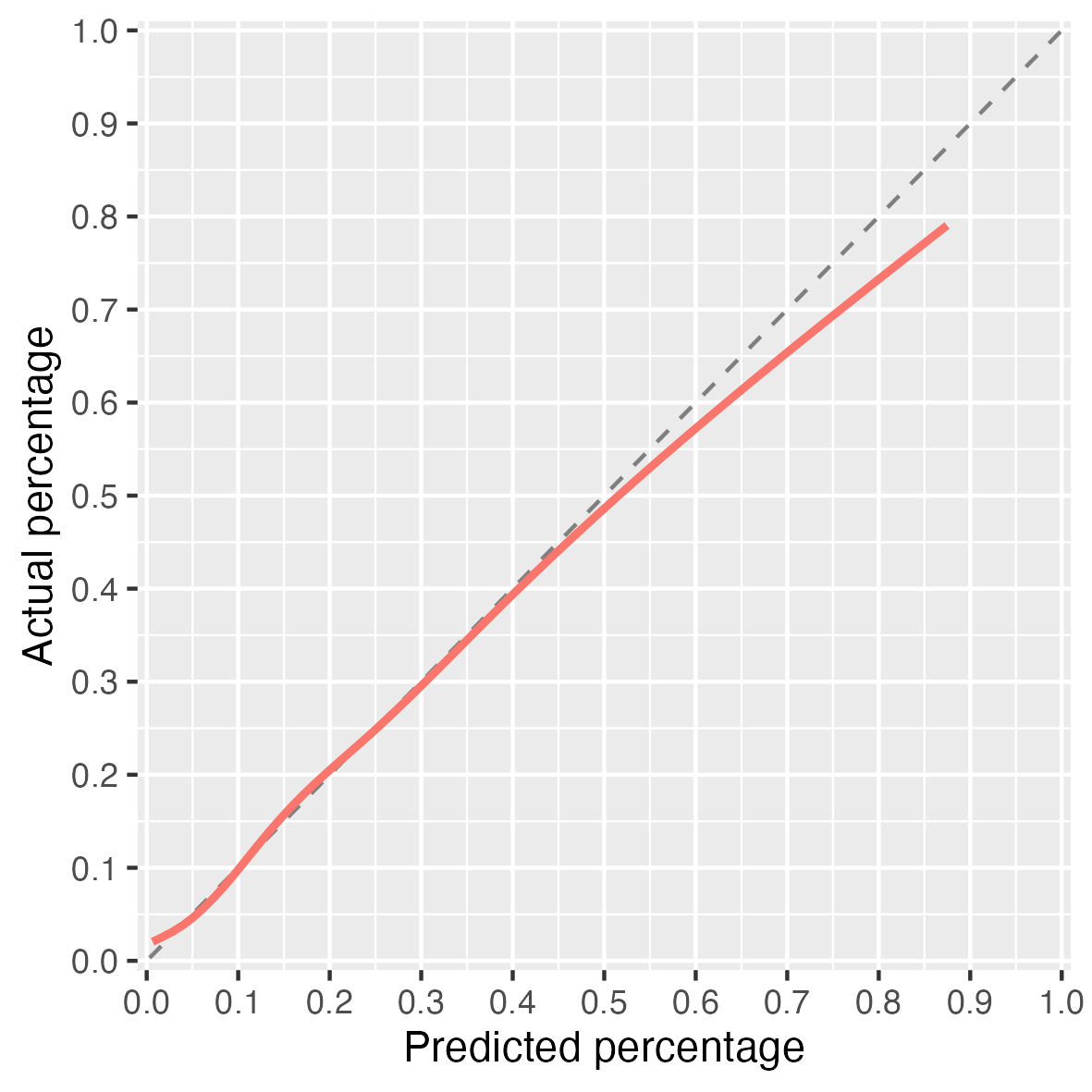
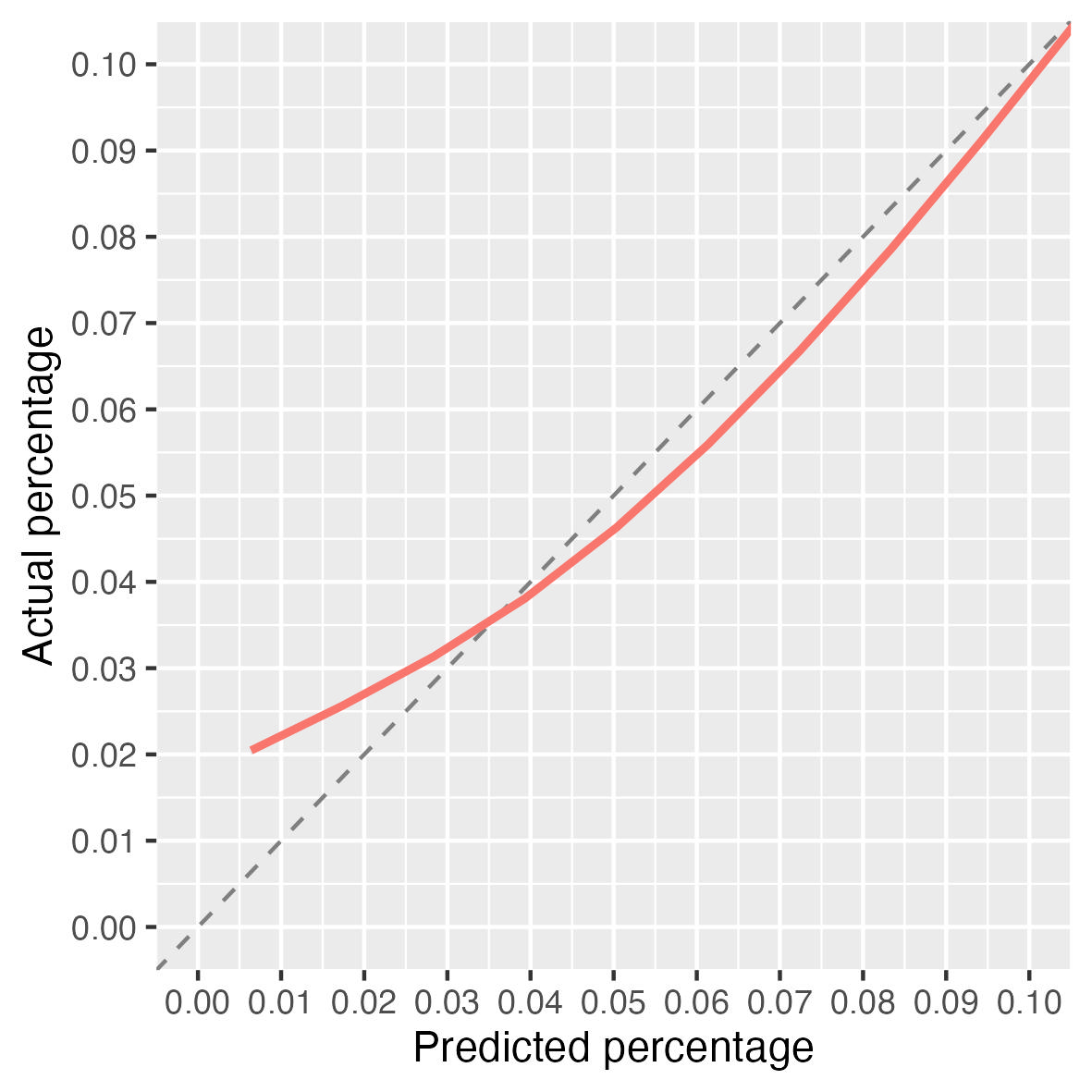
Whether a regression model or a machine learning model there are times when the performance of the model across certain ranges of probabilities is very important to a clinician making decisions. A lot of what I am involved in supporting emergency physicians deciding whether to keep someone in for more testing or send them home. They are risk averse (thankfully) and so will only send home when they have high certainty that a person has a low-probability of an event (eg heart attack). Therefore, if we are to provide models that output a probability of a diagnosis we want to ensure it is very well calibrated at the low-end.
Ultimately we’d like to use decision models that optimize expected patient utility. Short of the we like to have excellent absolute accuracy. So you might concentrate on an interval of predicted risk as you stated. A good general-purpose summary measure that doesn’t quite do that but is still very helpful is the 0.9 quantile of absolute calibration error, E_{90}.
Note that your axis labels are incorrect. These should be Predicted Risk and Actual Risk or Predicted Probability and Actual Probability as they are not percents.
When you say tuning, what do you mean? Add more parameters? You can do some post-processing of the predicted probabilities (e.g. isotonic regression) though in my experience that is often a bit like adding more parameters and makes things unstable.
This could be a bad idea, as you aren’t meant to interpret coefficients, but you could also take a look at the patients whose risks are being underestimated. I would find that interesting.
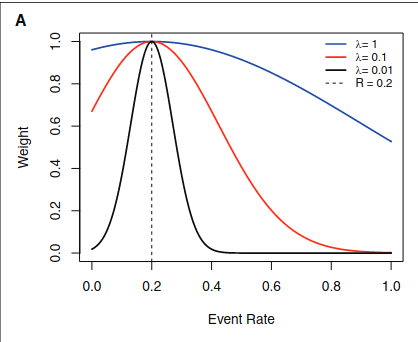
I think Mishra et al. (2021) is potentially relevant as it relates local calibration around a decision threshold t\in(0,1) with net benefit optimization (Corollary 1). They leverage this relationship to propose a weighted recalibration method that improves net benefit at specified thresholds. A similar approach for ML classifiers would be to optimize the underlying prediction cutoff based on net benefit. Either way, you need a fixed decision threshold.
But from a pragmatic point of view I tend to think it’s an overkill. I mean, conceptually it points out the important issue: It’s important to calibrate predictions that are near the decision boundary in order to have a better NB.
The biggest conceptual obstacle is still declaring a p.threshold or a range of p.threshold that reflects the personal tradeoff between TP and FP. Once you have that, for the most part a calibrated model is already an improvement from a baseline strategy (“Treat None” for the most part).
This is related to discussion I frequently have with @VickersBiostats where I try unsuccesfully to make the point that to cover all bases you need the calibration curve to be excellent wherever you have enough data in the risk range to estimate it.
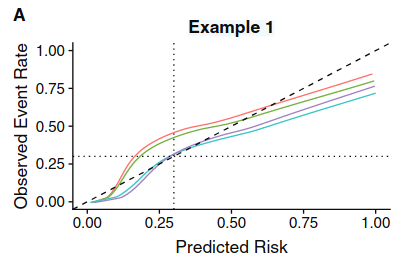
You’ve been unsuccessful because you haven’t made a good argument yet! Take the case of a model to predict cancer on biopsy, where you’d do a biopsy if there was, say, a 5 - 20% risk of cancer, depending on the patient and their preferences. Your model is well calibrated up to 50%, but then underestimates risk (e.g. model estimates 60% when it is in fact 70%). My view is: so what? whether a patient has a 60% or 70% risk of cancer, you are still going to biopsy them. Now my understanding of your prior argument insisting on good calibration across the risk range where you have data is yes, but you can’t predict how the model might be used in the future. The obvious response to that is you can say for instance i) our model is “fit for purpose” it has good clinical utility (e.g. from decision curve) for what we want it to do, which is inform the biopsy decision making; ii) it is miscalibrated at high probabilities; iii) it should not be used for other uses for which accurate estimation of high probabilities is important; iv) if you wanted a model for such a use, you’d have to do more research and modify the model or use a different one.
Andrew that’s a good argument except for addressing the cases where there is clinical disagreement or clinical ignorance about the decision thresholds.
True. Although: 1) clinical disagreement about the thresholds is part and parcel of decision curve analysis, it is why we calculate net benefit over a range of thresholds (such as 5 - 20% in the example above). 2) If there is clinical ignorance about the decision thresholds, then there is no point having a model and the issue of calibration doesn’t come up (or alternatively, miscalibration doesn’t matter). If I have a model and I tell a doctor “your patient has a 22% chance of the event” and they say “ok. but I’m baffled. Is that high or low? I have no idea. What do i do now?” then why are we building and evaluating the model?
Can’t fully agree. When there is disagreement on thresholds, different physicians will make different decisions, as they do anyway. Thresholds don’t always exist but calibration does.
“When there is disagreement on thresholds, different physicians will make different decisions, as they do anyway”. How is that disagreeing with what I said before? That is exactly the point of a decision curve analysis, to see if the finding that a model is preferable to some alternative depends on the threshold.
“Thresholds don’t always exist”. Can you provide me with an example of a model where: 1) no-one knows what the threshold is; 2) folks find it useful; 3) we worry about calibration? This should not include general prognostic models, because those assume a very large number of different decisions (should I quit my job and go on a cruise around the world? should I get extra health insurance? should I make those investments?). (this is why, for such models, we give decision curves across a very wide range)
Not to belabor an old argument, there are new clinical practice situations where not much is known and traditions have not been established. That’s why it’s good to sometimes separate accuracy from decisions. We hold calibration as a “sacred” part of model validation. For one thing it rules out badly done ML algorithms that can’t even get calibrate-in-the-large correct.
Thank you everyone for the comments (and sorry for mislabelling Frank…). For the risk assessment processes I work with the most in the emergency department False Negatives rather then False Positives are the greater issue - so as with Andrew’s example with Cancer and biopsies a miscalibrated model at the higher end (or even for moderate risks) is not a big deal… they patient will be admitted anyway. However, for something like assessment for possible myocardial infarction the clinician’s don’t want to miss events, so calibration down at the very low end is important (so, near the “edge”).
Giuliano - thank you for that revered… I will certainly look into it.
Robin - for “tuning” it could by hyperparameters in some machine learning model, or it could be something as simple as the function used for a continuous variable in a logistic regression model.
Thanks again everyone.
Can you give an actually example? What is a model that has been developed and “not much is known and traditions have not been established”? How would the model be used? I agree in general that we need calibration, because a miscalibrated model will often be harmful. But there are many situations where miscalibration at certain risks is clinically irrelevant and I still don’t understand why we should worry about it. Are you really saying if you had a model used with low thresholds (say around 10%) that was perfectly calibrated up to 50%, and had great net benefit, you’d recommend against the model if it was miscalibrated for risks above 50%?
Risk models are used all the time. Even more so outside of medicine but a lot in medicine. Many are successfully used without consideration of decision thresholds in the initial paper, relying on good decision making in the field.
ok, fair enough. But could you answer the two questions I asked?
Could you give an example?
Are you really saying if you had a model used with low thresholds (say around 10%) that was perfectly calibrated up to 50%, and had great net benefit, you’d recommend against the model if it was miscalibrated for risks above 50%?
I don’t see the need for an example. Regarding 2. I’m not saying that if clinical opinion about the 10% threshold was unanimous or if 20 clinical experts all placed the threshold below 30%.
Need for an example. You say “we need calibration irrespective of clinical utility is situation X”. I don’t think situation X exists.
Not sure I understand your response here. Are there some missing words? Let’s assume that there is an overwhelming consensus that thresholds are below 25% and the model is well calibrated up to 50%.