I will fix this post about medical decision making with an example that relates to a manuscript my colleagues and I posted recently on MedRxiv ( https://medrxiv.org/cgi/content/short/19011924v1). Women at high risk of tubo-ovarian carcinoma, such as women who carry a disease associated variant in BRCA1 or BRCA2 are usually offered prophylactic surgery (bilateral salpingo-oophorectomy) as a preventive measure. The lifetime risk of tubo-ovarian carcinoma in a BRCA1/2 carrier is over 15 per cent. Recently other genes with uncommon disease associated variants have been identified and there has been some debate about the level of risk that would be appropriate to offer prophylactic surgery. Some have suggested a lifetime risk of 3 to 5 per cent. This would be equivalent to a odds ratio of about 3. The purpose of this topic is not to discuss the rights and wrong of whether an odds ratio threshold of 3 is appropriate but about how we deal with estimates of risk at or around this value.
The example here is provided by the manuscript above. We sequenced the gene PALB2 in 13,000 samples from multiple case-control studies. Protein truncating variants were associated with an increased risk with an odds ratio of 3.0 (95% CI 1.6 – 5.7). The question now arises as to whether or not this is clinically useful.
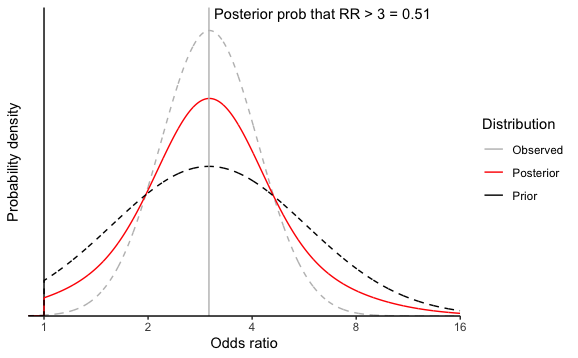
Given that we cannot be certain what the true odds ratio is, how certain, as a percentage do we need to be that the odds ratio is above 3 to offer prophylactic surgery to carriers of a deleterious variant. I would say at least 50% and perhaps as high as 80%, but definitely not as high as 97.5% (corresponding to the lower 95% confidence limit). At this point it is worth remembering that a frequentist confidence interval does not give us any sort of certainty that the true value is within a given range (despite its name). Ideally, we would have done a formal Bayesian analysis of the original data in order to obtain a distribution of the likely odds rato estimate, but my team and I have not yet managed to convert to this. Instead I will resort to using mixture distributions to combine a prior distribution for the odds ratio and the observed distribution from the frequentist point estimate and standard error to generate a posterior. I have assume the prior distribution of the log(odds ratio) to be normal with mean log(3) and standard deviation 0.65, but truncated at an odds ratio of 1 because it is extremely unlikely that these variants would be associated with a reduced risk. These values were taken from a previously published risk estimate and confidence interval.
The prior, observed and posterior distributions are shown in the Figure. From the posterior distribution there is a 51% chance that the true odds ratio is 3 or greater. However, if we wanted to be 80% certain that the true odds ratio is 3 or greater, these data would be insufficient to warrant offering prophylactic surgery to carriers. If the true odds ratio is 3, even with a huge sample size, we will not have that degree of certainty.
My question for others is how should we think about precision when the true effect is at or around and effect size that might be considered a threshold for decision making? I suspect that some sort of probabilistic thinking around the decision threshold is required, but I would be interested to hear the views of others.
Thanks for posting this Paul. I suggest making a few edits before I add my $.02 worth. Relative risk is much different from odds ratios. It would be good to not use RR anywhere but refer only to OR for clarity, including in the first paragraph.
Unless I’m missing something here, it seems to me you are asking the wrong question. The key question here is what are the sensitivity and specificity of these protein truncating gene variants to predict the incidence tubo-ovarian carcinoma. Moreover, you need to define in what population would these gene variants be measured, so that the predictive value for a positive test in that population could be defined. I fail to see how can you obtain the relevant information for a clinical decision (the positive predictive value) from a relative measurement of effect of a risk factor.
Sensitivity and specificity apply to retrospectively sampled data, e.g., case-control studies, and play no role in prediction. The prediction problem does not condition on the future to predict the past.
Changes made to odds ratio throughout. However, for ovarian cancer the rare disease assumption seems quite reasonable so the OR does approximate the RR.
I am primarily interested in the principle around the precision of estimates and clinical decision making. Whether any given estimate is relevant to a specific population is a different issue (though important).
This is probably a more complex question than you hoped it was, since your decision to treat will also need to depend on things like outcomes from surgery, life expectancy with/without Sx, costs (to help capture opportunity cost), quality of life in any additional years etc.. etc.. and that’s before you even get to the uncertainty part. So in my opinion what you need is some sort of the loss function, with the approach I am most familiar with in health being to create a cost-effectiveness model, but you might also be interested in/able to get away with something like stochastic multi-criteria acceptability analysis. In both cases I would argue that precision is only important if you are in a position to recommend further research (see: The irrelevance of inference: a decision-making approach to the stochastic evaluation of health care technologies - PubMed).
I guess you could also look at whether recommendations would differ along your CI? But again I think that depends on assumptions you make around baseline risk and all the risks/benefits of subsequent therapy.
My point was to take as given all those other issues and assume that the decision threshold was established. This is quite a pragmatic issue. Many family cancer clinics offer prophylactic surgery at a given risk threshold. If the odds ratio estimate for a given gene were 3 (0.3 - 30) then it is unlikely that anyone would be testing for that gene at all. The idea that clinicians would be carrying out some complex sliding scale decision analysis seems unlikely. So, at what level of precision does it become useful to do testing for that gene?
I guess what I’m saying is that I don’t think this is really possible without some sort of loss function. How expensive is the test? Who bears those costs? What care is foregone as a result of loss of that money/clinician time? From whose perspective is the decision being made? How long will the test be relevant? What benefit does it provide over the current best-practice (genetic risk + history and environment I assume?). I guess you could try to assume that the OR is directly proportional to utility of the decision, but I have a hard time believing that will lead to good decision making. Even then, the uncertainty related to the decision is more relevant for whether to delay implementation to fund future research to increase precision or implement now and also fund research.
Say that you use some rule that says you shouldn’t recommend treatment if your 95% Credible interval includes 2 (because of some sense that then risks of surgery or risks + costs outweigh benefits). Then in this case you would not recommend use of the screening tool even though it’s more probable to be effective than not. The link above is a seminal paper on exactly this problem (i.e. how to incorporate uncertainty into decision making).
Decision analysis for a given population would be done by a research team and then used by clinicians and patients as part of the decision making process if the patient in front of them is relevant to that analysis.
Some other thoughts that come to mind:
Your OR is really only a tool to turn an assumed baseline risk into absolute probability for a given population. Making a cut point based on an OR assumes that you have a well enough defined patient population that they all have similar balances of benefits/harms at that OR.
All of this also assumes your predictions are well-calibrated, your OR of 3.01 can be interpreted causally, etc…
I think we are discussing at cross purposes. My point is not whther 3 or 4 or 2 or any other value is the right trheshold, but if we have a threshold what credible interval is relevant. You selected 95% but why? Why not if the 50% credible interval excludes 2, or even just the point estimate.
I just used 95 to be consistent with what you were using above.
The relevant interval is going to depend on whatever loss function you implicitly used when coming to your OR = 3 threshold. Maybe the easier question is at what point would you no longer recommend treatment? OR = 1.3? 2? 2.5? Are you risk averse? Is the patient? Maybe the best approach would be to make a plot with ORs ranging from 1-5 on the x axis and P(OR at least that large) on the y.
Whether or not you recommend using the tool shouldn’t be based on any cut-point from that plot though, if your goal is to maximize patient benefit.
I respectfully disagree. It is perfectly possible to estimate the accuracy of a test by estimating their prospective sensitivity and specificity. Here are a couple of examples: doi: https://doi.org/10.1136/bmj.327.7426.1267 and https://doi.org/10.1111/j.1464-5491.2005.01494.x. The “prospective” sensitivity and specificity of the test may be the best way to assess the accuracy of any tool used for prediction, at least from the clinical perspective. If we are to make a treatment offer to a patient, based on the results of a predictive test, which is the issue in this case (if I got it right), we should know how good our prediction would be conditional on the finding of the predictive tool. A relative measure of effect does not tell that. We do not offer treatments based on risk ratios or odds ratios. As suggested in a previous comment, what is needed in this case is some sort of loss function, such as a cost-effectiveness analysis. Otherwise, we can not know what is the need benefit of using this prediction tool and what is its incremental cost-effective ratio as compared to the standard option (i.e. not using the prediction tool). For instance, when we use the Framingham equation to inform the decision of offering preventive treatment, we do not do it because the risk of cardiovascular events in patients with a high Framingham score is 5 or 10 times higher than in patients with a low Framingham score. We do it because we know that a sizable fraction of patients with a high score will develop a cardiovascular event and that, event if not all of them will develop a cardiovascular event, the benefit of this approach (selecting patients by their expected risk) is greater than the cost (including the cost of not treating patients with a low score who will develop a cardiovascular event).
I have obviously failed to explain the issue sufficiently. The Framingham score is somewhat distinct from a genetic test. The genetic test is either positive or negative - there is not some sort of continuous measure with the test being labelled as positive above a given threshold.
The penetrance or disease risk is akin to the positive predictive value - it’s the probability that someone who tests positive will get the disease in the future. SO we ahve a direct estimate of the PPV and the issue is about the precision of that risk estimate associated with a positive test.
I think you have been clear. You’re asking a question about uncertainty in decision making, but I think the issue is that we approach recommendations for medical decision making very differently. I just don’t think you can answer any questions about how you should deal with this kind of uncertainty without really knowing the costs of being wrong/benefits of being right.
If we take for granted that the OR of 3 is a good decision making rule, and that any value below 3 would result in withholding the test then the value of information (i.e. future research) would be at its peak so then the question is whether future research is actually worth it, since as you mention:
So one approach to whether you should make a decision today vs do further research is to conduct a value of information analysis which requires:
A estimate of the size of population for whom the test is relevant
A time horizon over which this test would be relevant (i.e. when it will be replaced)
The cost of future research
The time required for additional research
A loss function
If the cost of future research (in $ and foregone health) is more than the value of that information then the right decision is to make the decision today that maximizes utility. This way you’re taking into account all potential benefits, and harms including the harm of delaying access. This assumes you aren’t risk averse, so it will change if you are (i.e. being a little wrong is worse than the truth being a little better). You may be interested in reading Gianluca Baio, Carl Claxton, Mark Sculpher, Andrew Briggs (white book). This is why I don’t think you can separate the problems of specifying a cut point and assessing how you should handle uncertainty in your parameter.
Using retrospective reverse information-flow quantities of sensitivity and specificity is like making three right turns to do a left turn. Coupled with the fact that sens and spec vary significantly by patient types it’s very hard to see why the use of transposed conditionals ever caught on in the first place. If you like sens and spec then you’d have to like the following way of summarizing a hypertension randomized trial: patients with higher blood pressures were more likely to have been randomized to treatment A.
Let me clarify my original concern, as I’m finding it hard to grasp the relevance of your arguments. If I understood correctly, what motivated the original question was the investigators desire to develop a clinical decision rule: When should we offer an oophorectomy to a patient with a positive genetic test? To answer that question the investigators are looking for ways to refine the precision of the odds ratio for the association between the gene variant(s) and the incidence of ovarian cancer. My point (limitation?) is that I fail to see how such a rule could be based on a measurement of the association between the gene variant(s) and the disease. As far as I understand, such a rule can not be defined without taking into consideration the properties of the test (sensitivity and specificity), the expected incidence of the disease, and the absolute and relative cost and benefits of the proposed intervention. I fail to see what this has to do with the flow of information in estimating sensitivity and specificity or the direction of causality in interpreting randomized trials.
They are not that different, since we make the Framingham score positive or negative by using a predefined cut point. I think Tim suggestions are right on target: “we approach recommendations for medical decision making very differently”… you should conduct a value information analysis (I’d say a cost-effectiveness analysis) to define the best cut point. Assuming you could get the best precision possible for the OR, I still do not see how you would go from the OR to a clinical decision rule (a decision to offer or not to offer an oophorectomy to a patient with a positive test). Of course, my not been able to figure out how to do this, does not mean it is impossible.