First of all, a big thank you to @f2harrell and @Drew_Levy for the wonderful 4-days RMS course! I have learned so much and am now even more determined to do my part in lessening the replication crisis in my field of research.
I would love recommendations on the modeling strategies. My data has:
- A continuous outcome Y, a blood biomarker, measured once at age 25.
- The exposures are repeated measures of a Likert scale that measure stress, measured annually from age 9 to age 19. I’m starting with modeling this as a continuous variable because of the choice of the models that I listed below.
- N is roughly 1000. Missing data pattern is unusually good for a longitudinal dataset with very small % of attrition.
I have two main research questions:
- Is the exposure across time (cumulative life-time effect) associated with the outcome measured once at age 25?
- Can we include an interaction term in the model to account for effect modifiers?
And maybe a bonus question:
3. Can I model my repeated exposures as ordered cumulative predictors as described by Bürkner, P. C. and Charpentier, E. (2018). or not? 10.31234/osf.io/9qkhj
To study these research questions, my initial literature reviews found the following strategies:
- Unsupervised data reduction with PCA/clustering and use of the PCs/cluster assignments in an OLS linear regression. I think that this method makes sense and is simple. The downside is the usual choice of how many PCs, or the number of clusters to choose from and how well would this work for repeated exposure over time. I can test this in a simulation.
- The latency models for protracted exposures by David B. Richardson at 10.1097/EDE.0b013e318194646d. This models the exposure over time as an integral of the time-weighted exposures as a term in a linear regression model.
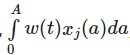
The pdf of a log-normal distribution or splines can be used to estimate the weights (w) parameters if certain assumptions about the form of the exposure overtime are made (strong intial influence then dropping off overtime). - The Bayesian relevant life course model by Sreenath Madathil 10.1093/ije/dyy107. This model is conceptually similar to the latency model.
 .
.
I’m thinking of using the latency model for my data. But I was wondering if anyone is experienced with this kind of analysis and has any suggestions and recommendations?