Meanwhile…

https://www.atsjournals.org/doi/abs/10.1164/rccm.202303-0558WS
I have just assumed the role of one of the statistical leaders of the new APS (ARDS/Pneumonia/Sepsis) consortium funded by NIH and I’ll be working with several of the authors of that paper. I would appreciate seeing some discussion of the paper.
I hope there will be considerable discussion. This is an interesting paper as it provides a perfect opportunity to examine operational 1980s “Pathological Consensus” (PC) from the statistician’s perspective. Note, that the consensus group appears to have been clinical. The authors appear to gloss over the effect on RCT reproducibility (as induced by augmenting the heterogeneity of the cohort captured by the expanded thresholds). The comments also appear to relate to clinical issues not statistical questions about trials such as RCT. One commenter touches on heterogeneity. "I would prefer identifying characteristics that would focus on specific ‘types’ leading to more personalized interventions." The response of the authors largely ignores the comment simply indicating that more research is needed.
The new measurements added are pulse oximetry derived SPO2 to generate a SPO2/FIO2. This is not uniquely problematic and its substitution seems reasonable.
The new signal being added, SPO2 from pulse oximetry is a volatile measurement and it also falls within the category of a death signal but this is also true of PaO2 (the Berlin measurement). “Volatile death signals” such as blood pressure, lactate, heart rate and SPO2 are problematic for ML, (for example), because they become increasingly nonspecific during the dying process. For example the three common patterns of unexpected hospital deaths’ all include a falling SPO2 yet Acute Lung Injury (i.e. “ARDS”) is only a portion of the Type I pattern of death. Patterns of unexpected in-hospital deaths: a root cause analysis - PubMed
The paper fails to note that “reproducibility” has not been a feature of RCT applied to a cognitive bucket of different diseases over the past 35 years. Even so, this non-reproducibility is well known and the bane of critical care consensus science so it is surprising that statisticians are not in the consensus group. (Perhaps they are but I do not see any statistical discussion of the affect of this new definition on trials) .
This more expanded definition was predictable in any regard as pathological consensus groups generally provide a more expansive “updated” definition every decade or so. Given that the Berlin definition for ARDS was 2012 it was time for the “expanded Berlin”. (for example expanding SIRS based sepsis threshold sets were 1992, 2002, 2012, and then when it became clear that SIRS was failing they moved to SOFA in 2015). (Recall despite this there has not been one reproducibly positive sepsis trial in 35 years) : The threshold cutoff expansion was so severe In the field of sleep apnea that eventually the majority of some populations had sleep apnea after the expanded “Chicago” consensus definition.
The paper also gives credit to Dr. Petty who guessed the syndrome in 1960s. "We would like to dedicate this manuscript and the work of this committee to Thomas L. Petty, MD and John F. Murray, MD who provided foundational contributions to recognizing and studying the Acute Respiratory Distress
Syndrome."
This is typical . PC papers do not cite discovery but rather the thought leader who guessed the original definition. Dr. Petty, in the simple days of the1960s, thought all these conditions of acute lung injury (e.g. viral pneumonia, post trauma, pancreatitis, gastric acid aspiration) looked like “Respiratory Distress Syndrome (RDS) of Prematurity” so he speculated they had a common pathophysiology (hyaline membrane disease) and lumped them together, calling them “Adult Respiratory Distress Syndrome”(ARDS) to differentiate his new syndrome from “RDS” of prematurity.
Dr. Petty’s idea was false and indeed this paper finally accepts (after 56 years) there is no common pathology captured by the Consensus thresholds.
Even today, to physicians managing cases of acute lung injury, they do look quite similar but part of that is due to the fact that the lung is a collection of alveoli and capillaries so it is not surprising that a wide range of injuries to the lung look the same. The authors of this paper acknowledge that “our ability to distinguish between the specific pathology of ARDS and the more general syndrome of non-cardiogenic acute hypoxemic respiratory failure remains limited.” They go on to say, “histological findings vary and often include intra-alveolar edema, inflammation, hyaline membrane formation, and alveolar hemorrhage, often termed diffuse alveolar damage; however, these histological features are not always present and are not necessary for a clinical diagnosis of ARDS.”
Given that there are no common histological findings and a widely divergent pathophysiological basis, the question arises as to what is the difference between “non-cardiogenic acute hypoxemic respiratory failure” and “ARDS”. Is there a difference? If there is how do we keep non-cardiogenic acute hypoxemic respiratory failure" from contaminating an “ARDS” trial. Is COVID pneumonia (where type II alveolar cells are infected) ARDS so it can be lumped for RCT with post trauma ARDS where there is no infection at all? The authors do not provide answers to these questions.
In 1980s pathological consensus, the measurements for RCT are consensus “guessed” and there are a range of means for this process. Since this can introduce bias, the basis for selecting the authors is important In this case the authors were “selected through an informal cascading recruitment process. The conference chairs identified subject area experts who then recommended other members, considering the stated diversity goals.”
The diversity generated by this approach may be superior to prior methods. For example the application of the sepsis definition and protocols developed in high resource countries had an adverse effect when applied in low resource countries Simplified severe sepsis protocol: a randomized controlled trial of modified early goal-directed therapy in Zambia - PubMed
However this still has all the characteristics of pathological consensus particularly the threshold set captures a range of diseases with widely disparate pathophysiology and pathology which will likely have disparate disease specific ATEs which will be hidden by the RCT studying the unified “syndrome”. As it was for sepsis in Zambia in the cited article, the mix of captured diseases (and their different ATEs) which are included as “ARDS” will be different for different world regions and different trials. There is no evidence that the authors considered this in the derivation of the consensus.
In summary as a “construct” of hypoxemic respiratory failure due to acute lung injury this seems like a good expansion. As a measurement for the investigation of treatment for the synthetic syndrome “ARDS” the expansion is likely to have little effect as ARDS is already profoundly heterogenous. Non reproducibility of trials and the application of protocolized treatment to diseases which were not sufficiently represented in the index trial (as occurred with COVID pneumonia) will continue if pathological consensus is allowed to go forward as a platform for world research.
It seems like there are three maddeningly complex and intertwined problems:
As the authors note: “The therapy for ARDS may be outstandingly performed by the best intensivist expert in the world on mechanical ventilation, but if the colon perforation is not well treated the patient will die no matter how well the patient is mechanically ventilated…”
Some articles note that the majority of patients with ARDS die for reasons not directly related to “unsupportable ventilation,” but rather from other components of their illness (e.g., infectious complications). In other cases, the patient might be kept alive with mechanical ventilation but is ultimately unable to tolerate weaning from the ventilator. And in many cases, deaths involving patients diagnosed with ARDS might be related to a decision to withdraw care for reasons unrelated to the patient’s respiratory status (e.g., multi organ failure, anticipated poor neurologic recovery). Considering all these nuances, how exactly should a death “due to” ARDS be defined?
Lawrence- I’d be interested to hear somebody clearly articulate the goals of research directed at ARDS. Possible goals (?):
The more a person thinks about these problems, the more wicked they seem…
Thanks so much @llynn end @ESMD for the exceptionally helpful thoughts about the paper. I’m going to let the authors of the paper know of this discussion, and hopefully some of them will join in.
Thankyou. I hope they will.
If you send them the excellent artcle cited by @davidcnorrismd particularly “table 3”) it might help them understand the focus here is on trials notwithstanding the potential value of ARDS as a clinical “construct” for awareness, etc.
This month a study was published using an alternative measurement broadening of the standard 2012 Berlin Measurement for Adult Respiratory Distress Syndrome (ARDS) using a threshold flow rate of High Flow Nasal Oxygen (HFNO) as criteria.
They compare mortality using the old 2012 definition (Berlin) and this new one but how this relates to the mortality using the other new “Global Definition” cited by @simongates is unknown.
Recall, the other (“Global Definition” ) for broadened of Berlin uses SPO2 from pulse oximetry (substituting SPO2/FIO2 for PaO2/FIO2). These are measurements of oxygen in arterial blood in relation to treatment (the fraction of oxygen being given and/or the nasal oxygen flow rate).
Using thresholds of treatment as a measurement for RCT is something which I hope we can discuss here.
This 2023 paper demonstrates the profound complexity of attempting to retain the 1967 ARDS dogma of Tom Petty as a unified platform for RCT and other trial measurement.
I will do that here to provide an example of the state of the dogma. Here I describe, in lay terms (very basic, forgive me) the evolution of the “science” of adult (later called “acute”) respiratory distress syndrome (ARDS).
The Origin of Adult Respiratory Distress Syndrome (ARDS)
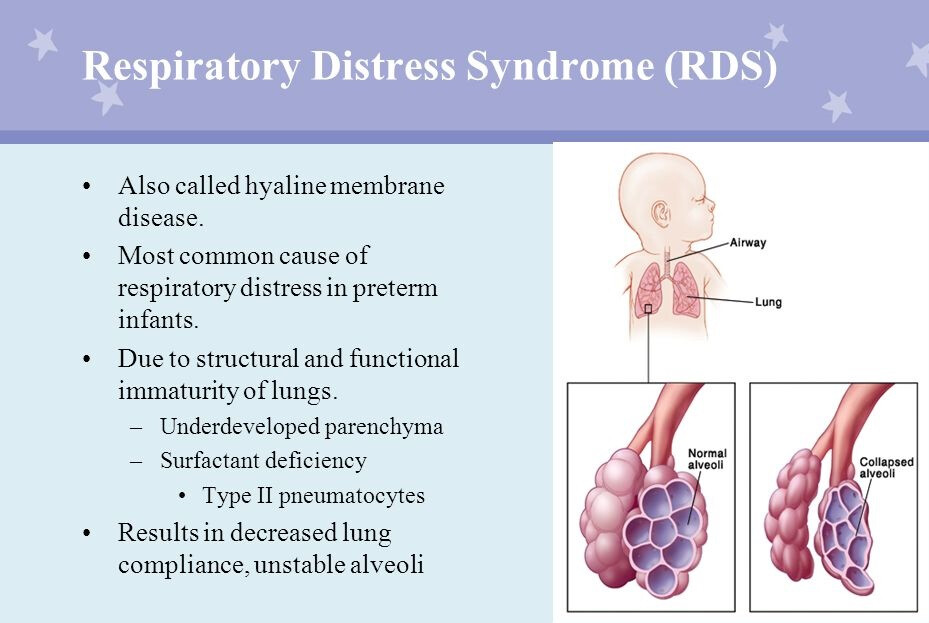
In the 60s “Respiratory Distress Syndrome” (RDS) of premature newborns was common.(eg death a child of President John Kennedy). This was caused by lack of a biochemical called “surfactant” which functioned to reduced severe and intractable collapse of the tiny lung air sacs (alveoli). The lack of surfactant produced RDS.
In RDS (hyaline membrane disease), the alveoli become progressively more difficult to inflate even with a mechanical ventilator. The lungs would become stiffer (harder to inflate) and the “chest Xray” (CXR) would show fluid diffusely in both the lungs. Blood oxygen would fall to severe levels despite high oxygen administration. in other words the partial pressure of oxygen (PaO2) and the saturation of arterial hemoglobin with Oxygen by pulse oximetry (SPO2) would fall in relation to the fraction of inspired oxygen (FIO2) producing a low Pao2/FIO2 or SPO2/FIO2.
1st Idea: Tom Petty suggests adults can also have “Hyaline Membrane Disease” (RDS)
In the late 60s, a pulmonary physician, Thomas Petty noted that adults had a similar “appearing” condition (to RDS of the newborn) with stiffening lungs and CXR findings after viral pneumonia, major trauma, pancreatitis, the inhalation of vomit, and many other diverse conditions. He theorized that this was also “hyaline membrane disease” and that it had a similar cause as RDS of newborns and he called the condition Adult Respiratory Distress Syndrome (ARDS). Indeed these patients had strikingly similar presentation and progression with increasing lung stiffening with increasing pressure required for ventilation.
Even in severe cases the lung pathology was often not the cause of death. Rather it was often not possible to wean them from the ventilator and they commonly died of “recovery failure” with secondary infection or by patient or family request. Mortality was highly variable but often quoted in the mid 30s to 45% range for more severe cases.
Clinical trials of “ARDS” begin lumping the causal diseases together thinking they were treating a single disease of the lung
Consensus groups guessed broad threshold set measurements for ARDS for RCT and, under these guessed measurements, the trials lumped ALL the diverse diseases inducing the appearance of RDS into Petty’s ARDS. However, surfactant treatment did not provide benefit.
All drug trials for Petty’s ARDS fail
None of the drugs tried over many decades worked for Dr. Petty’s lumped diseases, although corticosteroids seemed to work or were harmful in various trials.
2nd Idea: “Recovery failure is due to ventilator induced lung injury (VILI)”
In the late 1990s, given the lack of success, a new idea developed that it was the ventilator induced inflation pressure injury causing failure to recover. A trial showed the 6cc/ Kg breath from the ventilator was better than 12cc/kg. This led to the low volume ventilation but the gain in outcome was quite modest and unfortunately the 12cc/kg used in the trial was a high ventilator volume not normally prescribed (usual volume was 10cc/kg).
3rd idea: Recovery failure is due to patients “fighting” the new low volume settings of the ventilator
As noted, improvement with low ventilation volumes was quite modest but one problem with low volumes was that patients often felt like they were suffocating. This air hunger (Tobin called it waterboarding) caused considerable suffering and higher sedation (which was know to cause adverse effect on weaning) was required to prevent wide pressure swings leading to lung injury. The solution was thought to be paralysis of the patients. However, paralysis trials were performed which did not improve survival.
4th idea: Patient Self-Inflicted Lung Injury" (P-SILI) is suspected as the cause of recovery failure.
The next the idea was that the patient herself was causing the lung injury before being connected to a ventilator by hard breathing. This was called “P-SILI”. This led to very early intubation and mechanical ventilation to minimize the effort. This aggressive treatment idea (based on a theory) failed during the COVID pandemic and produced much controversy.
In summary.
Tom Petty’s 1960s idea was an example of the wrongful (in retrospect) application of parsimony, the view that the simplest explanation is often the correct one. It was a simpler time. DNA had only recently been discovered. Disease was perceived in simpler terms. Seeking a common causal basis for both RDS of the new born and the similar appearing pulmonary dysfunction associated with adult diseases was logical.
RDS of the newborn had been successfully treated. Not so for Petty’s idea of “ARDS”. However, buoyed by the success of RDS treatment and believing Petty was right, optimistic researchers over 5 decades cycled through drugs, ventilator adjustments, paralysis, and early intubation seeking a unified treatment for Petty’s perceived but elusive “common cause” of recovery failure. After 37 years, by the turn of the 21st century Petty’s lumping idea had become dogma, in all the textbooks and taught worldwide. The RCTs of the 21st century embraced Petty’s idea which had now become fully entrenched dogma.
The pandemic exposes the paradigm
Then the pandemic showed that parsimony (lumping) had failed and exposed the extreme to which the dogma combining such disparate diseases had evolved over 56 years. Severe COVID pneumonia, which includes actual infection and destruction of type II alveolar cells, was so profoundly different than RDS of the newborn and many other causes of “ARDS” yet it was just summarily lumped in with all the other diseases because it met the guessed measurements and Tom Petty included viral pneumonia in his original description of ARDS (because, in his view, viral pneumonia looked like RDS of the newborn). COVID exposed the pitfall of oversimplification and lumping over decades disparate diseases by guessing a set of non specific thresholds to capture the diseases for RCT. (so called “pathological consensus”)
Of course COVID pneumonia was not the only outlier disease, it was simply the most overt as an outlier and it was so plentiful that it’s outlier status could not be averaged away by broad application of a protocol. Now it was clear that lumping all these diseases with disparate pulmonary pathology and pathophysiology for protocols and for RCT clearly was (in retrospect) a mistake. However, even after the pandemic, researchers despite 56 years of failure, could not give up on Petty’s idea.
However, after the pandemic, the casual ideas for salvaging Petty’s ideas became very complex and layered as researcher clung to Petty’s original 1960s idea. Maybe, some experts mused, they could just exclude severe COVID pneumonia as an anomaly rather than recognize it as the counter instance it was. Some experts even proposed calling the rest of ARDS, “non-COVID ARDS”.
The latest ESICM ideas for unified ARDS trials are so complex and fluidic that RCT applying the 1960s lumping dogma do not appear to rise to the statistical level (see previous post for citation). Whether or not severe COVID pneumonia is still included in ESICM 2023 “ARDS” is not clear. After all, how could it be?
Yet, in the 1960s an alternative approach to parsimony was bypassed by Dr. Petty. This is the tried and true simple approach of studying each disease individually. (eg RDS of the newborn, RDS of COVID pneumonia, RDS of Influenza A, RDS of a given drug, RDS of inhaled vomit, RDS of post trauma, or RDS of pancreatitis.)
This is traditional parsimony wherein the measurements relate to detection of an objective disease and the “thresholds” only define severity, not the guessed “synthetic syndrome” itself. This approach is universal in much of medicine and profoundly simpler but it requires much more administrative complexity with advanced multicenter research to achieve high enough cases for each trial. That’s something Petty could not do in the 60s (so he had to lump) but such trials are quite possible now. The reluctance to abandon the ARDS (unified syndrome) as an RCT platform is understandable.
Perhaps a common pathway will be found.
However, such trials must be performed within the statistical domain. The RCT measurements must rise to the statistical level. If this is not possible, then performing RCT directed to respiratory failure associated with each specific disease (and not ARDS as a unified state) must be considered and the pitfalls of the dogma must be taught and promulgated and not hidden within the complexity of evolving attempts to salvage Dr. Petty’s original 1960s idea.
lex parsimoniae
What a wonderful historical account and so well written. This will help many us trying to work in this field!
Thank you. Very good. I’ll do my bit to translate – how it might be worded in a consent document to help the lay person (a worried parent or child) stay with it and appreciate it.
Edit: Stepping through it more slowly, I don’t have material sufficient for a consent document, which would describe how the study intervention compares to current best practice.
Related: Guidelines on the management of acute respiratory distress syndrome
https://bmjopenrespres.bmj.com/content/6/1/e000420 (which seems properly nuanced to me based on a cursory read)
What I had before stopping - mainly shorter sentences limiting the use of technical terms:
Question: Should we treat Adult Respiratory Distress Syndrome (ARDS) like we treat Respiratory distress syndrome (RDS)?
RDS is a condition that occurs in babies born early (premature) whose lungs are not fully developed. The earlier the infant is born, the more likely it is for them to have RDS and need extra oxygen and help breathing.
RDS is caused by the baby not having enough surfactant in the lungs. The surfactant helps to prevent the collapse of tiny air sacs in the lungs called alveoli. In RDS (hyaline membrane disease), the alveoli become progressively more difficult to inflate even with a mechanical ventilator.
It has been thought (but not proven) that ARDS has a similar cause as RDS in newborns because adults with ARDS had similar presentation and progression of the lungs: increasing lung stiffening with increasing pressure required for ventilation.
Understanding how ARDS is discussed in the literature is pivotal. Here UpToDate presents ARDS as a unified condition. (i.e. As a Synthetic Syndrome) for treatment lumped according to the 1960s dogma.)
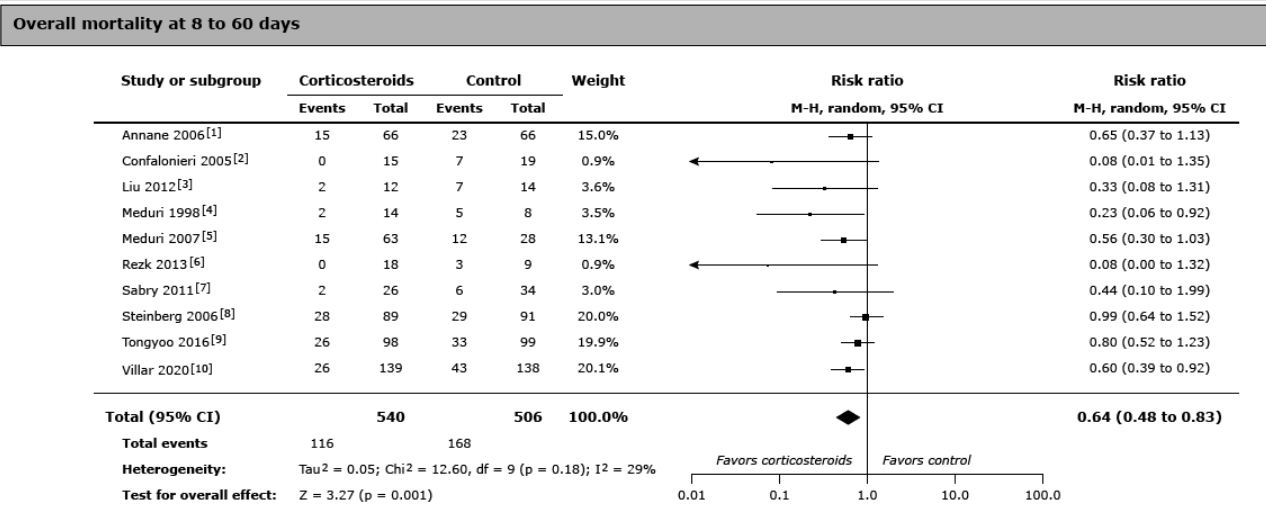
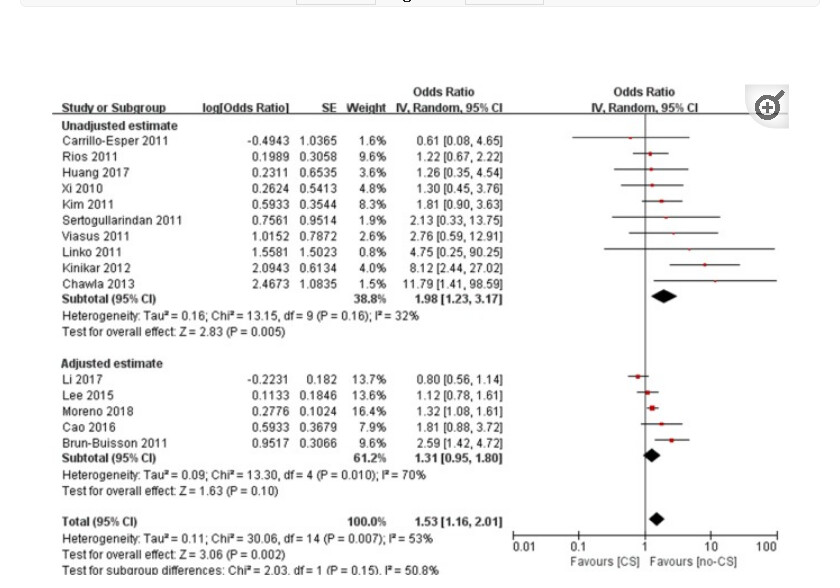
Compare these two graphs of treatment of ARDS with corticosteroids (also called “glucocorticoids”),
The first graph is from UpToDate and is a graph relating only to “ARDS itself” (whatever that is) and agnostic to the set of diseases under test. (Since the entry criteria are based on the guessed measurements defining the synthetic syndrome itself.)
The second graph, in contrast, is from a metanalysis of corticosteroids for “ARDS” secondary to Influenza suggested harm. This metanalysis was not agnostic to the set of disease under test.
.
First Graph
Second Graph
So why blindly aggregate all diseases into a single metanalysis if some diseases benefit and others are harmed by corticosteroids? This is due to the dogma and inability to let go of the 50 year old syndrome as a unified entity for drug study and protocolization. In fact in the first grouping of “ARDS itself” there was a study specifically for ARDS due to COVID pneumonia*. (Villar et al is 20% weight) but this study is just mixed in (included) with the rest rendering the entire analysis of ARDS outcomes disease agnostic
So… I decided to see what UpToDate would tell physicians to do and it is quite telling. UpToDate says:
"When glucocorticoids are used for other steroid-responsive conditions that are associated with ARDS, we follow the protocol typically used for that etiology. When glucocorticoid therapy is used for ARDS itself, commonly used regimens include:
●[Methylprednisolone]…
●[Dexamethasone]…"
UpToDate has the concept of “ARDS itself”, for which early corticosteroids are recommenced, and then UpToDate identifies ARDS due to COVID pneumonia as responsive but recommends against use of corticosteroids in ARDS due to Influenza Pneumonia.
What this shows is that when ARDS is studied simply as a severity marker of a specific disease rather than as a Synthetic Syndrome (a cognitive bucket or set of diverse diseases meeting a guessed set of thresholds), the results are different.
The strange UpToDate recommendations actually make sense in light if the past 20th century synthetic syndrome research approach which was agnostic to the mix of diseases under test so UpToDate calls that "ARDS itself" . Of course there is no way now to know which diseases are responsive in the set called “ARDS itself” and which are harmed in that same set (other than those like COVID and Influenza which were studied as specific diseases).
Understanding this shows the difficulty encountered when performing and discussing research in an area encumbered by an old synthetic syndrome dogma and obsolete lexicon which includes the nebulous, cognitive bucket term, i.e. “ARDS itself”. The statistician must be aware of the strange lexicon which may otherwise be difficult to define by valid math.
References:
UpToDate: treatment of ARDS
Reproducibility of any RCT is a direct function of the validity of the measurement of the condition under test.
I have shown how “Pathological Consensus” is the 21st century equivalent of Langmuir’s “Pathological Science”.
Indeed, Langmuir describes the abandonment of Pathological Science as potentially taking decades. In the case of the pathological measurements of N-Rays, the challenge came directly. The measurements were proven incorrect so they were summarily abandoned by the scientific community. Thats how science is supposed to work.
However, the Pathological Consensus of ARDS dates back nearly 60 years with changed (termed “updated”) guessed measurements every decade or so by a process of “consensus reguessing”.
So pathological consensus is durable because, unlike pathological science, where measurements are proven false and abandoned, pathological consensus measurements are fluidic.
Nonreproducibilty simply spawns a new set of guessed threshold measurements for RCT usually expanding the captured set of diseases within the syndrome.
One might ask, if the RCT consensus measurements are freely changable how does Pathological Consensus become abandoned. One might even ask if it is possible to cause abandonment of Pathological Consensus.
Here, with eyes open, scientists can witness, in real time, one possible mechanism of the collapse of a given class of Pathological Consensus.
Here is an example of how an expert clinician perceives the #PathologicalConsensus of ARDS.
https://emcrit.org/pulmcrit/pulmcrit-ards-is-not-a-real-thing/
Here is a quote from PulmCCM.
"Back in 2017, the American Thoracic Society, the European Society of Intensive Care Medicine, and the Society of Critical Care Medicine together issued a clinical practice guideline for the management of acute respiratory distress syndrome (ARDS).
That consensus seems to have frayed over the intervening 7 years each separately issued its own updated ARDS guideline in 2023, and SCCM did not lend its name to either. The dueling guidelines conflict in parts, reflecting the fundamental ontological confusion and challenges to effective research on the amorphous syndrome that is ARDS."
Its easy to forget these are consensus “measurements for RCT” not just for clinical gestalt. So “dueling” RCT measurements (and one group, the SCCM apparently clinging to the old RCT measurement) is not sustainable.
Here we see a potential mechanism for demise of consensus measurement of ARDS. In the past it was not politically expedient for trialists or statisticians to question any consensus RCT measurement. Now, at least for ARDS, there is no global consensus.
One might think this, with a little introspection, would be trigger the end of the Pathological Consensus of ARDS but that’s not true. Dueling guessed measurements occured in the past with synthetic syndromes of sepsis and sleep apnea and in neither have RCTs been reproducible for decades. In both synthetic syndromes the dueling measurements provided fertile ground for nearly unlimited studies comparing the different consensus RCT measurements. All, of course, a waste with the next “updated” RCT measurement.
Yet there is reason for optimism. Now, the academic environment is different. The nonreproducibilty of RCT of synthetic syndromes was widely understood (if not widely promulgated) but the consequences to the public health of pathological consensus as a basis for RCT measurements was not perceived until the pandemic.
Clinicians also now perceive that the pitfalls of guessed thresholds as consensus measurements for RCT extend beyound the frustrating lack of reproducibilty, to negatively impact care, through a “false positive” evidence basis for worldwide protocolized intervention.
Over the next few years we will see different societies, and different parts of the world struggle as each different contemporaneous measurement (or social construct) of ARDS engages with the unyielding pathophysiology of the many diverse diseases captured in each construct. For ARDS its now the wild west with RCT measurement de l’année. Yet thats a more diverse evenvironment favoring introspection and debate. That’s not quite science but much better than 5 decades of unified pathological consensus of ARDS which rendered worldwide RCT measurement conformity by design.
The next virus may be more virulent.
While all of this is an amazing thing to watch, from the perspective of learning the social behavior of scientists, its time to place the determination of validity of the RCT measurement as a first consideration.
Maybe there is no valid measurement of a syndrome guessed by one physcian in 1967. Even that minimal level of open introspection would be real progress.
The linked paper presenting “blindness to marginal utility” as a primary driver of negative critical care trials is titled:
“More is exponentially less: marginal utility in critical care research”
https://doi.org/10.17267/2675-021Xevidence.2022.e4722
https://journals.bahiana.edu.br/index.php/evidence/article/view/4722/4776
Quoting:
“It is notorious that randomized clinical trials (RCT) on critical care are prone to return negative results, especially if the study outcome is mortality”…
“blindness to marginal utility is frequently found in critical care RCTs and that marginal effect sizes are common.”
Before the pandemic I pointed out that there was no hope for reproducibility of critical care RCT (and sleep apnea RCT) because they use guessed measurements which capture a variable set of diseases with diverse pathophysiologies.
Here we see one problem is that marginal utility may be rendered more insignificant when a target is present in only a fraction of the diseases captured by the measurement. Further, this fraction is variable depending on the disease mix of the instant set (as captured by the applied measurement in the instant RCT) and will vary from one RCT to the next.
There are two ways to consider this paper.
First, Critical Care reseachers have long questioned whether their research is “doomed to fail” by mechanisms other than Pathological Consensus. This provides an alternative failure mode for those clinging to traditional RCT of synthetic syndromes.
A better way to understand this, is that it provides a mechanism by which the adverse effect of Pathological Consensus is magnified. In other words this is one more reason why Pathological Consensus has long been predictably fatal to critical care research.
It is progress that the author presenting “blindness to marginal utility” does not argue this as an alternative failure mode to pathological consensus. Rather, he states:
“Clinical trials of ARDS and sepsis, both poorly defined syndromes, usually fail because of the teleological “find a patient for a treatment” approach of current diagnostic criteria.”
Here he points to one dimension of the problem of marginal utility is that the diagnosic criteria (RCT measurements) are not valid measurements of the pathophysiologic target of the treament under test.
However he does not mention an important point: whereas the concept and quantification of marginal utility is highly complex, pathological consensus is a simple RCT design mistake from the 20th century and is an easily correctable design flaw.
However, as entrenched dogma, that which is easily corrected from a RCT design perspective cannot be corrected without a revolution of enlightenment.
The recognition of marginal utility is useful but it will never be possible to address this issue until the 20th century apical mistake of deriving a set of thresholds for RCT measurements by consensus guessing and thereby capturing variable sets of different diseases with diverse pathophysiology (i.e. pathological consensus) is abandoned.
The framework of marginal utility adds to the discussion of the mistakes intensivists made at the inception and keep making at each revision of constructs like Sepsis and ARDS.
I think the error stems from the teleologic nature of these constructs. Intensivists have to be operational. Facing a patient in shock, or a case of hypoxemic respiratory failure with diffuse chest infiltrates, we have to act without having a full diagnostic workup. I advance to declare Sepsis and ARDS are less than syndromes, the lowest level of medical diagnosis. These constructs are merely operational approaches, akin to triage tools, wrongly treated like real nosologies. The need for an agreement around some basics of life support caused Critical Care to stray into Pathological Consensus, which I interpret as constructs made on simple bona fide guessing, not built over sound pathophysiological hallmarks.
Most of the time, clinicians have enough time for a diagnostic exercise before proposing a treatment. The diagnosis has an implicit mechanistic reasoning that elicits the treatment options, or at least an approximation of them. Becoming merely operational is not a trivial change in the way physicians think.
When scientists and clinicians reason without a pathophysiological hallmark, they see every plausible mechanism as equally relevant. Hence, they can not find a dominant cause of morbidity to intervene in. And treating marginal causes yields marginal results. The result is that our specialty is struck with RCTs suffering from this peculiar problem. Finally, I think that blindness to marginal utility helps explain why these pathological consensuses arise and perpetuate.
I posted some of this in another discussion:
However this method for defining measurements for syndrome RCT and for clinical decision making relating to syndromes is particularlly relevant to this thread.
Rather than simply guessing the measurements for a syndrome (as they had for 35 years) they now blend in ML. Yet, like the past guessed iterations, this is a still one-size-fits-all measurement.
This is an image of the most recent process for defining RCT measurement and clinical decision making, relevant to the syndrome “pediatric sepsis”. Data from patients virtually worldwide are obtained.
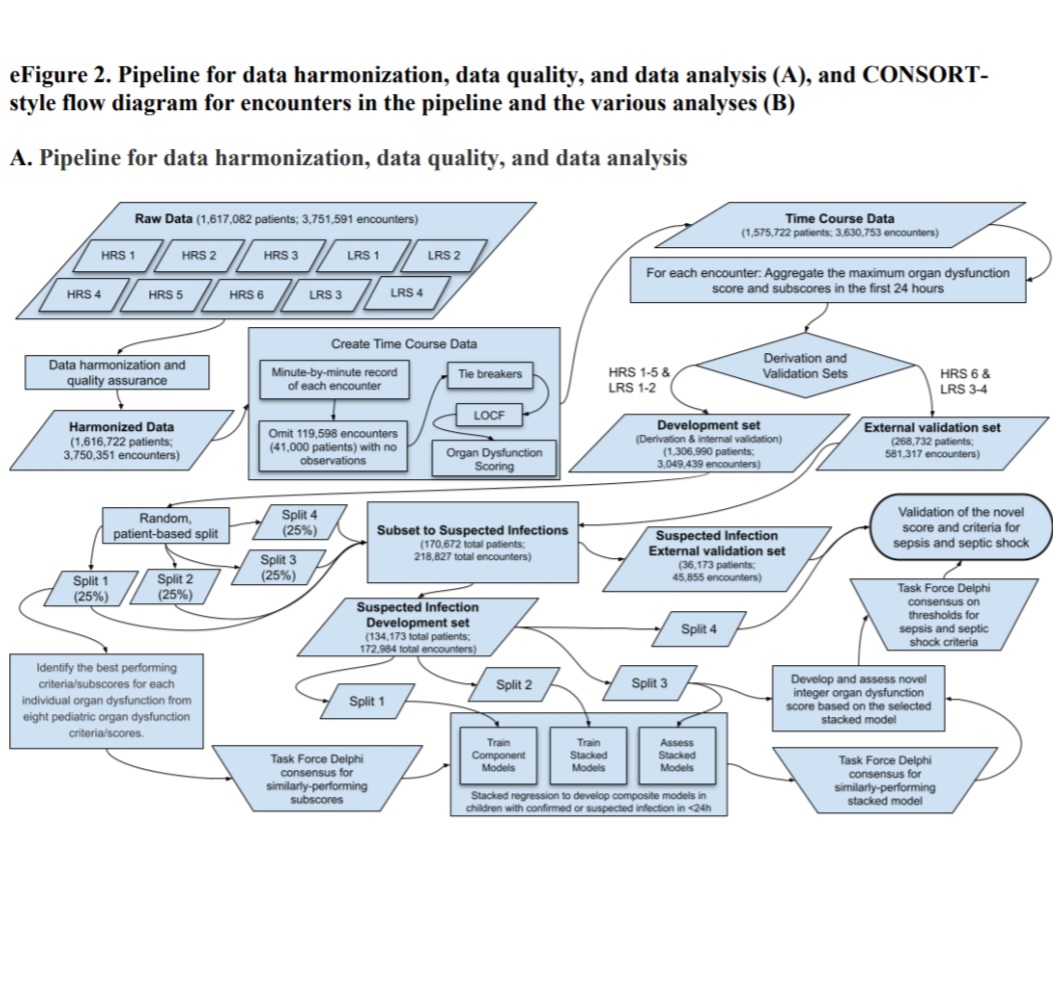
The result of this process are the RCT measurements (thresholds) and the clinical decision thresholds promulgated below.
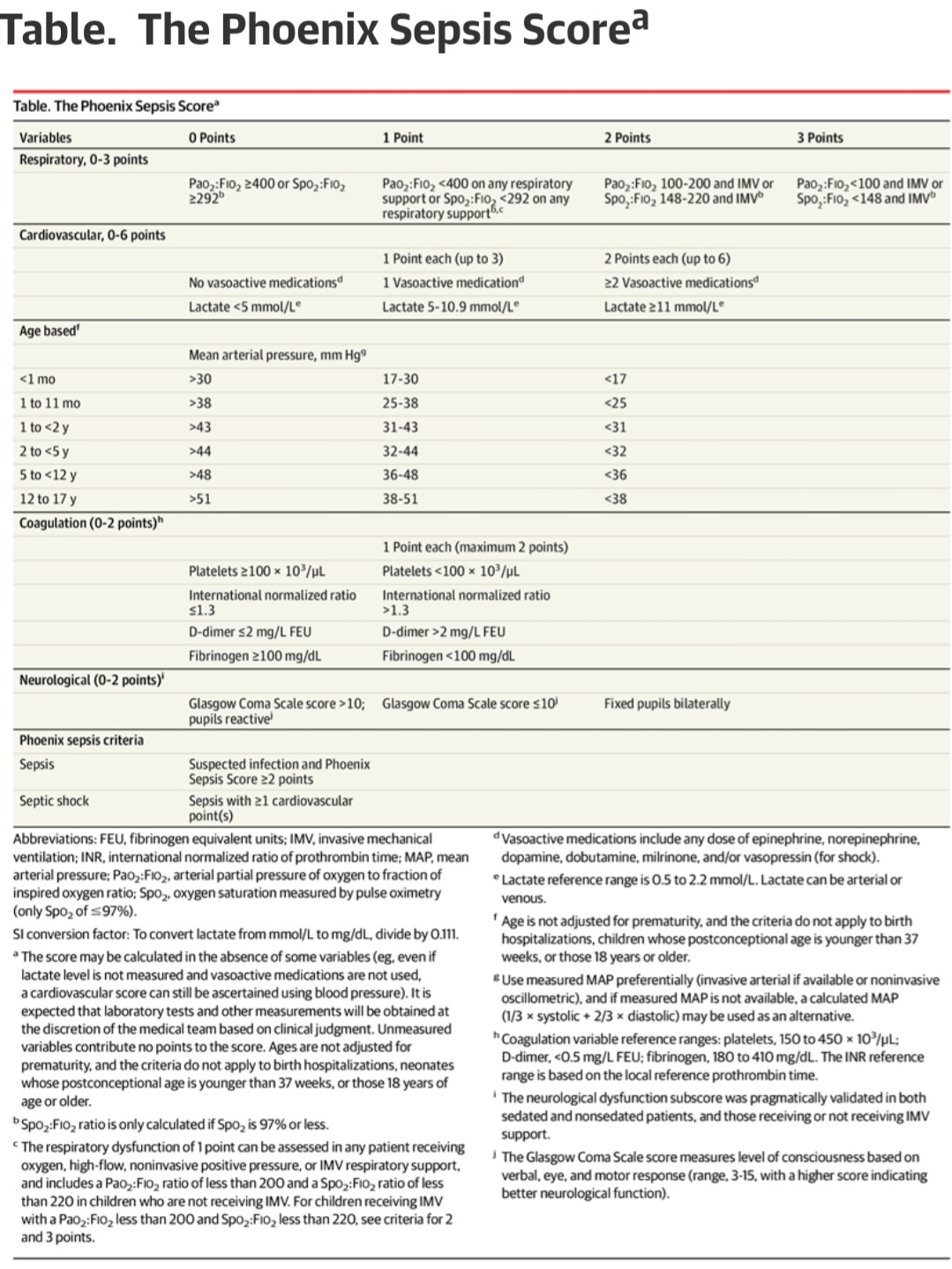
In research applications, these thresholds will be used to measure patients to identify “sepsis” for testing a given treatment and in clinical medicine the physcian is advised to use the threshold in a sample decision tree.
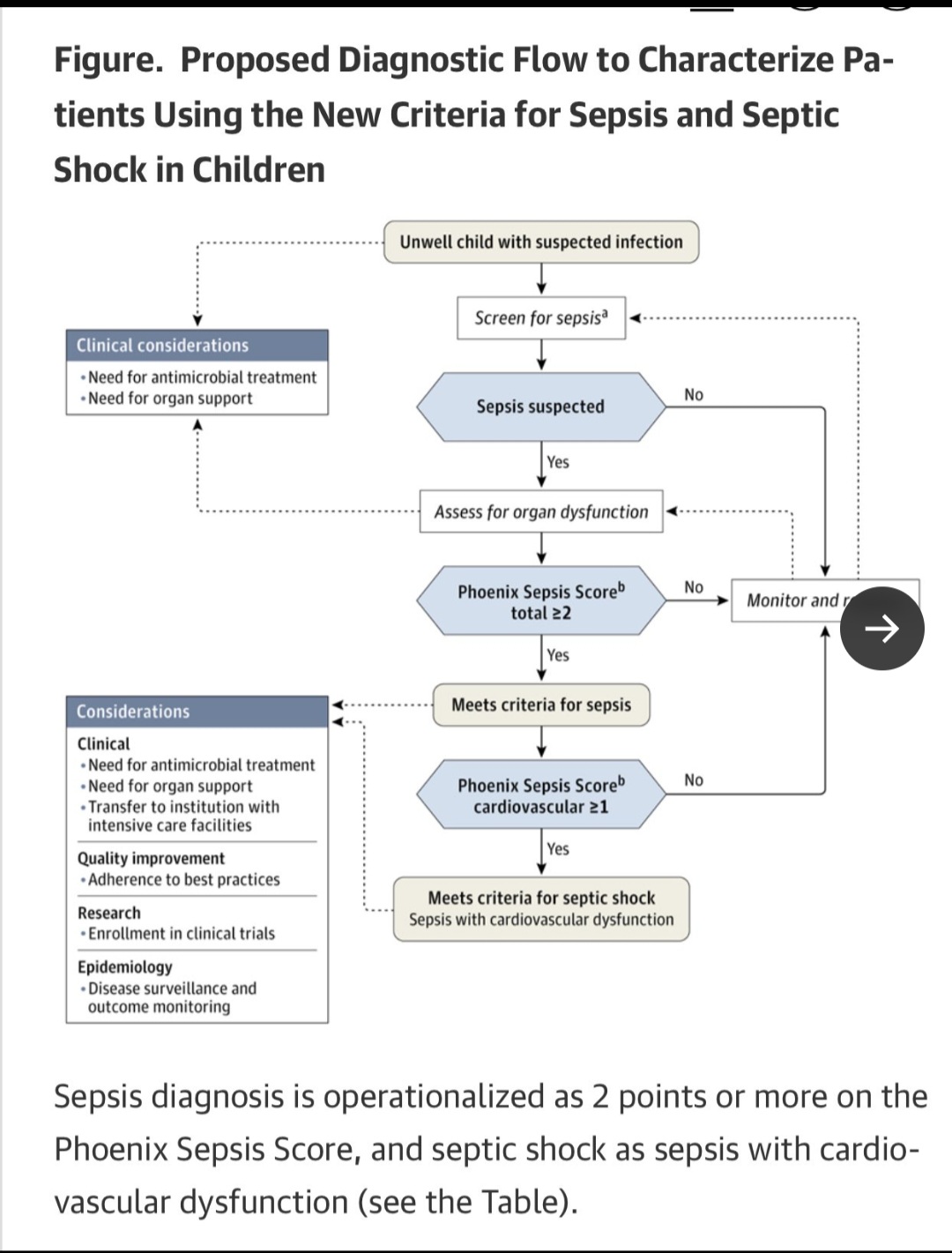
In the future, now that these are standards, RCT are performed with these measurements capturing the population. The captured patients are randomized and treatment applied to the treatment group. Rigorous math (Statistical processing) will then then applied to the outputs.
So is this is the same as the old PathologicalConsensus method but with ML/AI applied instead of simply guessing thresholds de novo?
Will this method work? Is this method statistically sound?