I began the campaign teaching about the pitfall of deriving “fake RCT measurements” for the performance of RCT in the study of synthetic syndromes before the pandemic
What is a fake measurement tool and how are they used in RCT.
It is amazing that in the middle of these teachings, the emergence of the pandemic provided a natural social experiment to show how critical care researchers would respond to a clear counter-instance to RCT applied to synthetic syndrome science.
Acute Respiratory Distress Syndrome (ARDS) is one of those “synthetic syndromes”. ARDS was defined nearly 50 years ago by a pulmonologist named Tom Petty. Editorial: The adult respiratory distress syndrome (confessions of a "lumper") - PubMed
Dr. Petty was a confessed lumper and he included severe viral pneumonia in the ARDS definition he made up. Unbelievably, nearly 50 years later, Dr. Petty’s decision to include severe viral pneumonia in ARDS would have severe impact on perceived EBM care for COVID pneumonia in 2020 and provides the basis for us to see how synthetic syndrome scientists think when faced with a disease (COVID pneumonia) that never existed before Dr. Petty’s guess but meets the criteria for the syndrome made up by Dr. Petty nearly 50 years earlier.
So here you see them over 30 years studying corticosteroid treatment of Tom Petty’s ARDS.
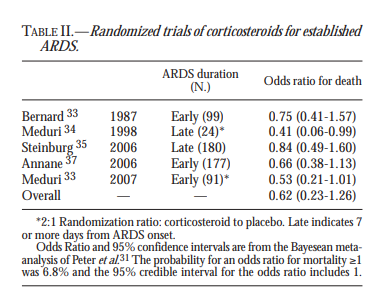
https://www.minervamedica.it/en/freedownload.php?cod=R02Y2010N06A0441
Then about 12 years later in 2019 Cochrane Review provides a metanalysis examining the mortality endpoint associated with Corticosteroids in ARDS. One year before the pandemic) Cochrane review states: "We found insufficient evidence to determine with certainty whether corticosteroids… were effective at reducing mortality in people with ARDS.…" This RCT evidence caused perceived “evidence based” opposition to corticosteroid treatment of “ARDS” due to severe COVID-19 pneumonia (remember severe COVID pneumonia was called ARDS because Tom Petty included severe viral pneumonia in the ARDS definition he made up in the 1970s)**.
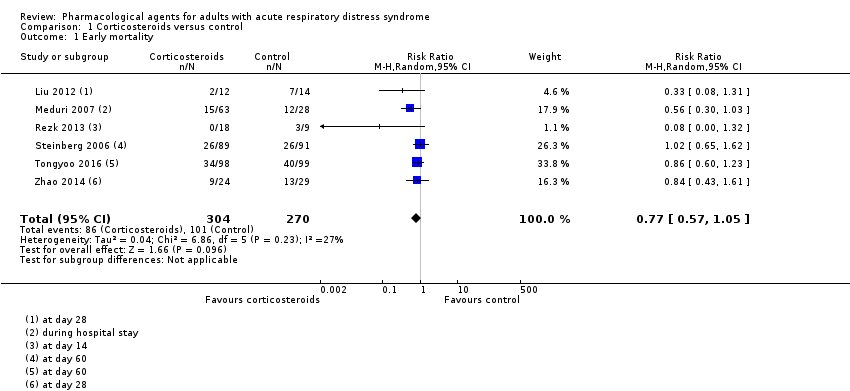
In contrast to the 35 years of “ARDS” RCT, this is the study of Corticosteroids in severe COVID Pneumonia which never-the-less meets the 1970s definition and the 2012 criteria for ARDS.
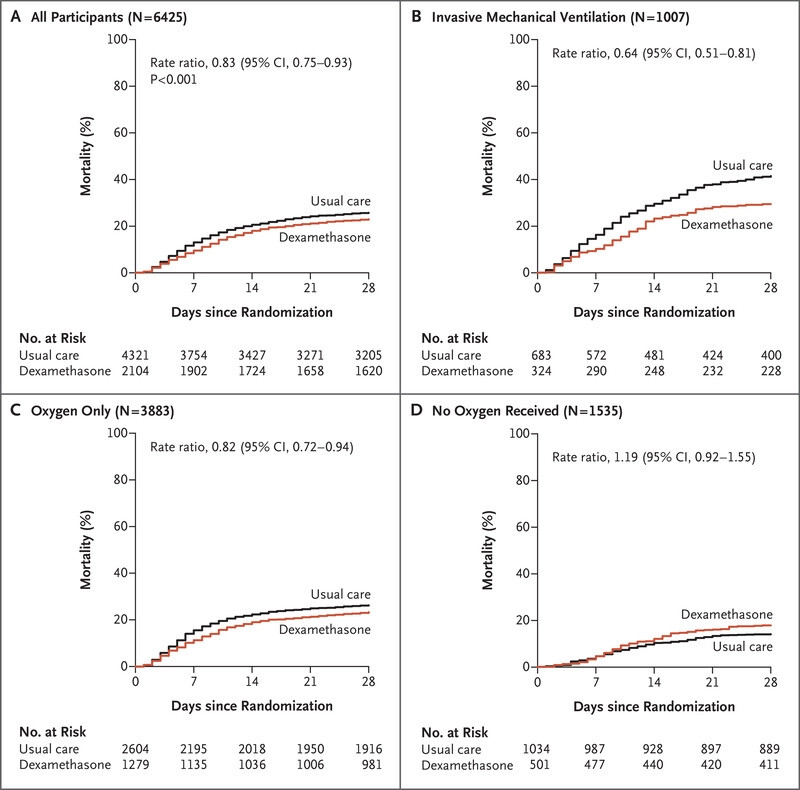
Now those clinging to the RCT and metanalysis for ARDS (the Tom Petty synthetic syndrome) were totally confused.
So this is what has emerged for this social experiment…The splitting the ARDS synthetic syndrome into a dichotomy
But why a dichotomy? Why should we believe that NON COVID ARDS is a syndrome? If we had a pandemic of pancreatitis would we be splitting ARDS secondary to pancreatitis based on its effect on the results of a metanalysis wherein so called pancreatitis associated ARDS dominated. .
It is interesting to watch and read the effects of the cognitive flagellations as the application of RCT to Tom Petty’s 1970s guessed synthetic syndrome is exposed as non-science by the emergent pandemic . But couldn’t we see it was non-science all along? We bundled viral pneumonia induced pulmonary dysfunction due to a novel virus in 2020 with pulmonary disfunction associated with trauma for an RCT because one pulmonologist thought that was a good idea in 1976?
Worse though is the emergence of the new synthetic syndrome for RCT “Non COVID ARDS”. This shows the lesson of the pandemic was not learned. RCT are not applicable to guessed cognitive buckets of diseases because the bucket mix changes all the time. Sometimes that change is due to a new virus. Scientists must learn the lesson the new virus has taught about the futility of guessing syndromes and making up measurements for RCT.
Now think again about this process:
- Prior to1975 Tom Petty guesses a syndrome “ARDS” and includes severe viral pneumonia.
- 1987 RCTs begin investigating corticosteroids in the treatment of Tom Petty’s guessed syndrome…
- Over 3 decades the results of the RCT for “ARDS” are mixed but largely weak or negative.
- COVID Pneumonia emerges as the greatest acute killer since WW2.
- Academics decide that since COVID pneumonia meets Tom Petty’s 1970s definition (as amended) and corticosteroids have failed in RCT these drugs should not be used in severe COVID pneumonia because RCT of Tom Pettys ARDS have been negative.
- An RCT is performed only on severe COVID pneumonia and it shows efficacy.